Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
To learn decision trees using training tuples annotated with classes, we use a technique called induction. Each internal node (non-leaf node) of a decision tree in data mining represents a test on an attribute, each branch represents a possible result of that test, and each leaf node (or terminal node) stores a class label. The node at the top of a tree is called the root node. Understanding decision tree data mining begins with understanding data science; you can get an insight into the same through our Data Science Training.
In data mining, the supervised learning technique of decision tree is utilized for classification and regression. There's a tree there that aids with selecting choices. Tree-like models for classification or deterioration can be generated using the decision tree. While creating the decision tree, the data set is partitioned into smaller subgroups. As a result, we get a decision tree with leaf nodes upon completion.
At the very least, a decision node will have two forks. The leaf nodes represent classification or a final verdict. Leaf nodes are the topmost decision nodes in a tree and are connected to the best predictor, also known as the root node. Decision trees are flexible enough to handle both numerical and categorical information.

Depicts the structure of a typical data mining decision tree. It stands for the idea of buying a computer and can foretell whether or not an AllElectronics consumer will make that purchase.
Ovals represent leaf nodes, while rectangles represent internal nodes. Not all decision tree algorithms can generate nonbinary trees; some can only generate binary trees (in which each internal node branches to precisely two other nodes).
When asked, "How are decision trees used for categorizing objects?" The attribute values of a given tuple (X) are compared to those in the decision tree to determine whether or not the tuple belongs to a specific class. The data is followed up from the root via a series of intermediate nodes until it reaches a leaf node that stores the class prediction for that tuple. Classification rules may be generated using decision trees with little effort.
Why are decision trees used in so many classification systems? Decision tree classifier design is well-suited to discovery through exploration since it does not need prior knowledge of the domain or the establishment of parameters. High-dimensional data is no problem for decision trees. The tree structure they use to display learned information is natural and straightforward to understand for most people. Decision tree induction's learning and categorization processes are quick and easy.
In most cases, classification decisions made using decision trees are highly accurate. However, the quality of the available data may influence the outcome. For categorization purposes, several fields have turned to decision tree induction algorithms, including those in medicine, industry, economics, astronomy, and molecular biology.
Several popular rule induction tools are based on decision trees. You can also learn the six stages of data science processing to grasp the above topic better.
Algorithm: Generate a decision tree. Generate a decision tree from the training tuples of data partition D.
Input:
1) Data partition, D, which is a set of training tuples and their associated class labels;
2) Attribute list, the set of candidate attributes;
3) Attribute selection method, a procedure to determine the splitting criterion that “best” partitions the data tuples into individual classes. This criterion consists of a splitting attribute and, possibly, a split point or splitting subset.
Output: A decision tree.
Method:
(Step 1) Create a node N;
(Step 2) If tuples in D are all of the same class, C then
(Step 3) Return N as a leaf node labeled with the class C;
(Step 4) If attribute list is empty then
(Step 5) Return N as a leaf node labeled with the majority class in D; // majority voting
(Step 6) Apply Attribute selection method(D, attribute list) to find the “best” splitting criterion;
(Step 7) Label node N with splitting criterion;
(Step 8) If splitting attribute is discrete-valued and multiway splits allowed, then // not restricted to binary trees
(Step 9) Attribute list ← attribute list − splitting attribute; // remove splitting attribute
(Step 10) For each outcome j of splitting criterion // partition the tuples and grow subtrees for each partition
(Step 11) Let Dj be the set of data tuples in D satisfying outcome j; // a partition
(Step 12) If Dj is empty then
(Step 13) Attach a leaf labeled with the majority class in D to node N;
(Step 14) Else attach the node returned by Generate decision tree(Dj , attribute list) to node N; end for
(Step 15) Return N;
4) There are three inputs to the algorithm:
The first one is dimension (D), a list of attributes, and a technique for selecting those attributes (Attribute selection method). D is shorthand for "data partition," which is the official name for this concept. At first, it is the full collection of training tuples and their corresponding class labels. The set of properties that characterize the tuples is the parameter attribute list. The attribute selection technique This method uses a metric for selecting attributes, like the Gini index or information gain. In most cases, the attribute selection measure determines whether or not the tree contains only binary nodes. The Gini index is one such attribute selection measure that requires the output tree to be binary. While certain factors limit branching, such as knowledge acquisition, others do not (i.e., two or more branches to be grown from a node).
5) The training tuples in D are initially represented by a single node in the tree, denoted by the letter N. (step 1).
6) When node N is a leaf and is assigned a class based on whether or not the tuples in D are all of the same class, we say that D is a class-based tree (steps 2 and 3). It's important to realize that 4 and 5 are dead ends. The algorithm's last section explains each of the possible exit situations.
7) In this case, the algorithm uses the Attribute selection approach to choose the criteria for the split. By identifying the "optimal" way to partition the tuples in D into individual classes, realize the splitting criteria indicate which attribute should be tested at node N. (step 6). With respect to the test results, the splitting criterion also specifies which branches to develop from node N. In particular, the splitting criterion denotes the splitting attribute and, optionally, a split-point or splitting subset. The splitting criteria are established to produce "pure" partitions at each branch. Pure partitions contain only tuples from the same category. In other words, we want the partitions that arise from splitting the tuples in D following the mutually exclusive results of the splitting criterion to be as clean as feasible.

Data Science Training
8) The splitting criterion is a test at attributed is indicated by the label (step 7). For each possible result of the splitting criterion, node N sprouts a new branch. Tuples in D are separated as needed (step 1 indicates, there are three distinct outcomes available if we define A as the dividing characteristic. According to the data in the training set, the value of A can take on v different forms: a1, a2,..., av.
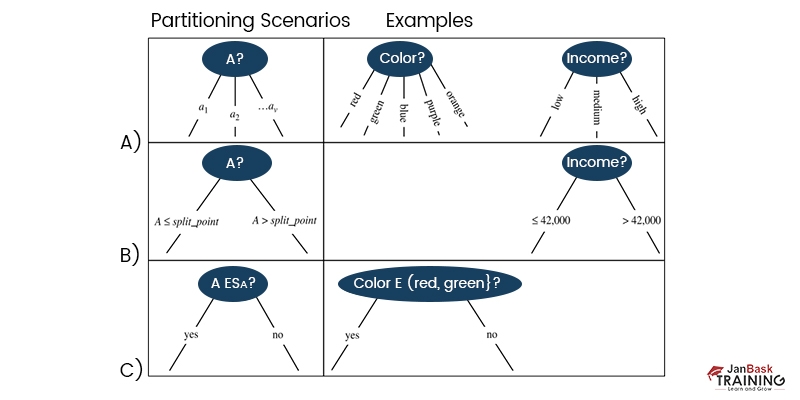
9) The algorithm uses the same process recursively to form a decision tree for the tuples at each resulting partition, Dj, of D (step 14).
The recursive partitioning stops only when any of the following terminating conditions is true:
10) The resulting decision tree is returned (step 15).
There are few advantages of using decision tree induction in data mining. Let’s explore these advantages:
Decision tree induction plays an essential role in data mining by providing valuable insights into the complex relationships between input variables and outcomes. It has several advantages over traditional statistical methods, including ease of use and scalability. It is suitable for diverse applications ranging from finance/insurance sectors, fraud detection, healthcare industry, customer segmentation, marketing campaigns, etc. You can also learn about neural network guides and python for data science if you are interested in further career prospects in data science. Check Our community page for data science community
| Data Science Courses | Course Links |
| Data Engineering Certification Training - Using R Or Python | https://www.janbasktraining.com/data-engineering |
| Artificial Intelligence Online Certification Training | https://www.janbasktraining.com/ai-certification-training-online |
| Python Online Training & Certification Course | |
| Machine Learning Online Certification Training Course | https://www.janbasktraining.com/machine-learning |
| Tableau With Data Science Training & Certification | https://www.janbasktraining.com/data-visualization-with-tableau |

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  12.1k
12.1k
What is Model Evaluation and Selection in Data Mining?
Mar 28, 2023 12.1k

Rule-Based Classification in Data Mining
Mar 27, 2023 11.7k
Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







