Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Data mining is the process of extracting useful information from large datasets. One of the most popular techniques used in data mining is clustering with constraints, which involves grouping similar objects based on reconsidering traditional clustering, making any external knowledge or constraints that may be available about the data. This can lead to suboptimal results and make it difficult to interpret the clusters. Researchers have developed constrained clustering algorithms that incorporate domain-specific knowledge or user-defined constraints into the clustering process to address this issue. Furthermore, clustering with constraints is a vital concept of data science. So to know more about the topic, keep reading.
Constraint based clustering (CBC) is a constrained clustering algorithm that uses additional information or constraints to guide the cluster formation process. The goal of constraint based clustering is to produce clusters consistent with these constraints while still being as homogeneous as possible within each cluster.
CBC is a popular clustering technique in various fields, including biology, social sciences, and computer science. It provides a flexible framework for incorporating prior knowledge or domain-specific information into the clustering process.In constraint based clustering, constraints can take different forms depending on the application domain. For example, genes may be constrained to belong to specific biological pathways or co-expression modules in gene expression analysis. In image segmentation tasks, pixels may be constrained to have similar color intensities or spatial proximity. In text mining applications, documents may be constrained to belong to predefined topics or categories.
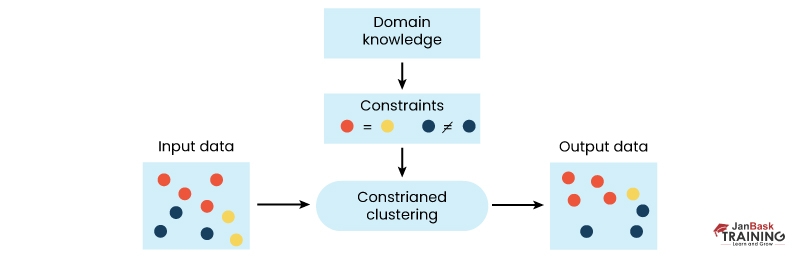
CBC algorithms typically consist of two main steps:
(1) Constraint Modeling: The constraints are encoded as mathematical expressions that define the allowable configurations of clusters. This can involve defining similarity measures between data points based on their attributes and relationships with other data points.
(2) Cluster Formation: In the second step of constraint based clustering algorithms, clusters are formed by optimizing an objective function that balances adherence to constraints with homogeneity within each cluster. This optimization process involves the iterative refinement of cluster assignments until convergence criteria are met.
Several constraints can be used in constraint based clustering, including pairwise similarity/dissimilarity constraints, must-link and cannot-link constraints, attribute-value equality/inequality constraints, and hierarchical structure constraints. Let’s learn about these methods in details:
Several popular algorithms have been developed for constraint based clusterings each algorithm has its strengths and weaknesses, depending on the type of constraints used and the nature of the data:

One way that constraint based clustering can specific external knowledge is by using constraints. Constraints are conditions or rules that specify how specific data points should be assigned to clusters based on prior knowledge or domain expertise. For example, a constraint might state that two data points must belong to the same cluster if they have similar values for a particular feature. By incorporating these constraints into the clustering process, constraint based clustering can produce more accurate and meaningful clusters.
Overall, constraint based clustering is a powerful tool for exploratory data analysis and pattern recognition that leverages additional information beyond just raw input features during the clustering process resulting in more accurate results than standard techniques when dealing with complex datasets with some form of prior knowledge about groupings within its contents.
Despite its advantages, several challenges are associated with constraint based clustering.
Constraint based clustering has become essential for data mining researchers who want to incorporate external knowledge or user-defined constraints into their analyses. By using these algorithms, analysts can produce more meaningful clusters that better reflect domain-specific information about their datasets while still being as homogeneous as possible within each cluster. However, the continuing challenges associated with constraint based clustering must be addressed if this technique continues growing in popularity among practitioners across different domains. Finally, if you are keen to become a data scientist, then you must have mastery over programming languages like R, Python, and Hadoop. Proficiency in these languages and proper communication skills will help you attain your dream job as a Data scientist.

Data Science Training
FAQ’s
Q.1. What is The Benefit of Clustering with Constraints?
Ans. The significant advantage of clustering with constraints is that it helps you make the clustering job more precise and definite by uniting user constraints, which can be instance-level or cluster-level constraints.
Q.2. What is The Need For Clustering with Constraints in Data Mining?
Ans. It is implemented in marketing to know about customer demographics. Having a deeper insight into various market divisions helps you target buyers accurately with promotional advertisements. It provides the scope for various practical applications for clustering with constraints in data mining.
Q.3. Give Some Examples of Clustering with Constraints.
Ans. Some examples of clustering with constraints are as follows:
Q.4. When Should We Not Use Clustering?
Ans. Clustering must not be utilized when there is data. Still, there is no method to arrange it into definite groups/ If there is a proper class label in the data set, then the labels made by a clustering analysis may not work properly like the natural class label.
Q.5. Mention The Types of Clustering with Constraints.
Ans. The types of clustering with constraints include centroid-based clustering, density-based clustering, distribution-based clustering, and hierarchical clustering,

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  12.1k
12.1k
What is Model Evaluation and Selection in Data Mining?
Mar 28, 2023 12k

Rule-Based Classification in Data Mining
Mar 27, 2023 11.6k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







