Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Data discretization in data science is the technique used to evaluate and manage large amounts of data into simplified forms. This technique converts a large number of data values into a smaller number of values. In a nutshell, data discretization is a method that converts the attribute values of continuous data into a discrete collection of intervals while minimizing the amount of data that is lost in the process.
The first method is known as supervised discretization, and the second is known as unsupervised discretization. Both of these methods are used to discretize data. A technique known as supervised discretization utilizes class data as part of its analysis. The term "unsupervised discretization" describes a process that is determined by the way in which the operation is carried out. This indicates that it is applicable to both the top-down technique of dividing and the bottom-up method of merging. Get the required Data Science Online Certification Course and become fully prepared for these prominent concepts of data science.
The process of transforming the attribute values of continuous data into a limited set of intervals while sacrificing as little information as possible is referred to as "data discretization." The process of data discretization, in which interval markers are substituted for the values of the numeric data, makes the transmission of data more easier. It is possible to substitute interval labels like (0-10, 11-20...) or (0-10, 11-20...) for the values that are stored in the 'generation' variable, which are similar in nature (kid, youth, adult, senior). The process of data discretization can be broken down into two distinct subcategories: the first is supervised discretization, in which the class data is utilized; the second is unsupervised discretization, in which the results are determined by the direction in which the operation is carried out, also known as a "top-down splitting strategy" or a "bottom-up merging strategy."
Continuous characteristics are a requirement for many different types of data mining projects in the real world. However, a significant number of the most recent exploratory data mining algorithms have difficulty appealing to qualities of this kind. In addition, even if the machine learning job is able to manage a continuous attribute, the output will benefit substantially if the continuous attributes are replaced with their quantized values. This is because the machine learning task is better able to manage the continuous values. The act of converting continuous data into intervals and then designating the precise value that should be used for each interval is known as data discretization. It is also possible to describe it as the process of discretizing time based on the units of time intervals, as opposed to a particular value.
Although the discrete values from the discrete attribute domain are not required to be present in each discrete interval of the discretized attribute domain, these discrete values must nonetheless cause an ordering to be imposed on the domain of the discrete attribute itself. As a consequence of this, it results in a very significant increase in the consistency of the information that is discovered, as well as a decrease in the amount of time required to complete various data mining tasks, such as the discovery of association rules, classification, and of course, prediction. It provides a steady improvement for domains that have a modest number of continuous characteristics, but even as the number of attributes rises, it is usually always accurate.
The process is referred to as top-down discretization or slicing if it begins by first locating one or a few points to divide the entire set of attributes (referred to as split points or cut points), and if it then performs this recursively at the intervals that result from the divisions made by those points.
Bottom-up discretization or merging is the term used to describe the process when it begins by considering all of the continuous values as possible split-points. Other continuous values are then discarded by combining neighboring values to form intervals, which is why this method is also known as bottom-up discretization.
Quick discretization of an attribute is possible, and it enables one to achieve what is known as a definition hierarchy, which is a hierarchical split of the attribute values.
Data Discretization Using Decision Tree Analysis - A supervised method is used to do data discretization in an application of decision tree analysis known as top-down slicing. This operation is carried out to ensure accurate results. In order to discretize a numeric attribute, you must first select the attribute that has the lowest entropy, and then you must put that attribute through a recursive process that will break it up into several discrete disjoint intervals, one below the other, using the same splitting criterion. This must be done in order for the attribute to be discretized.
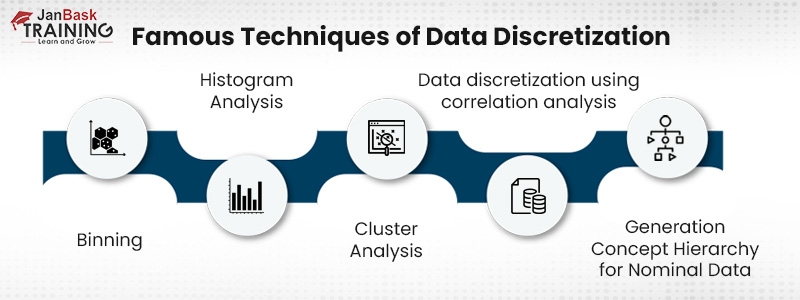
Binning - This method may also be utilized for the discretization of data and, moreover, for the establishment of thought hierarchies. The values discovered for an attribute are organized into a set of bins with widths and frequencies that are equal to one another. The numbers are then smoothed down by applying either the bin mean or the bin median to each bean. You may construct concept hierarchy by iteratively applying this approach. recursively. Unsupervised discretization is achieved by binning since it does not make use of any class information.
Histogram Analysis - The observed value of an attribute is partitioned by the histogram into a collection of discrete subsets, which are sometimes referred to as buckets or bins.
Cluster Analysis - The practice of discretizing data frequently takes the form of cluster analysis. It is possible to create a clustering method by first isolating a computational characteristic of A and then separating the values of A into clusters or classes.
It is possible to further break down each original cluster or division into a large number of subcultures, producing a hierarchy level that is lower than the first one.
Data Discretization Using Correlation Analysis - After discretizing the data using linear regression, the best neighboring intervals are identified, and then the big intervals are joined to produce larger overlaps in order to generate the final set of 20 overlapping intervals. It is a technique that requires supervision.
Generation Concept Hierarchy for Nominal Data - The nominal data or nominal attribute is one that has a limited number of distinct values, but there is no ordering between the values. Nominal qualities include things like employment category, age category, geographic location, item category, and so on and so forth. The definition hierarchy is formed by the nominal attributes, which are created by adding a collection of attributes. It is able to establish a hierarchy of definitions, such as a road, a region, a state, and a nation all at once.
The data are transformed into several levels thanks to the concept hierarchy. The definition hierarchy may be constructed, and this can be accomplished at the level of the schema, by adding partial or absolute ordering between the attributes.
If you are determined to learn Data Science, go ahead & follow this complete guide to Data Science Career Path.
There are mathematical challenges associated with continuous data for an unlimited number of degrees of freedom (DoF). Implementing discretization is necessary for data scientists to do their work for a variety of reasons.
Features Interpretation - Continuous functions, which have unlimited degrees of freedom, have a reduced likelihood of correlating with the target variable and can have a complicated non-linear interaction. This is because the degrees of freedom are endless. As a result, having a proper comprehension of such a function can prove to be more difficult. Following the discretization of a variable, it is possible to see groups that correspond to the goal.
Ratio Signal-to-Noise - When we discretize a model, we may fit it into bins and lessen the impact of tiny data variations in the process. Sometimes, the term "noise" is used to refer to slight deviations. This noise will be reduced as a result of discretization. This is known as the "smoothing" approach, and it involves lowering the amount of noise in the data by smoothing out the variations that come from each bin.
The process of transforming continuous qualities into discrete attributes is referred to as "data discretization" in the field of data mining.This technique may also be used to create binary attributes from other data types.
Example:
# demonstration of the discretization transform from numpy.random import randn from sklearn.preprocessing import KBinsDiscretizer from matplotlib import pyplot # generate gaussian data sample data = randn(1000) # histogram of the raw data pyplot.hist(data, bins=25) pyplot.show() # reshape data to have rows and columns data = data.reshape((len(data),1)) # discretization transform the raw data kbins = KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='uniform') data_trans = kbins.fit_transform(data) # summarize first few rows print(data_trans[:10, :]) # histogram of the transformed data pyplot.hist(data_trans, bins=10) pyplot.show()
The discretisation method chosen is determined by the nature of the data and the planned application of the discretized data. It is critical to carefully analyze the trade-offs between the lost degree of information and the benefits gained in terms of easier analysis or reduced data complexity.
To summarize, data discretisation is a useful approach for simplifying and summarizing data; nevertheless, it should be used sparingly and with careful evaluation of the data and research aims. You can check out the data science certification guide to understand more about the skills and expertise that can help you boost your career with data science certification and data discretization in data mining.

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  12k
12k
What is Model Evaluation and Selection in Data Mining?
Mar 28, 2023 12k

Rule-Based Classification in Data Mining
Mar 27, 2023 11.6k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







