Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
In machine learning, the term "multi feature classification" refers to a classification problem that involves more than two classes or outputs. It makes no difference whether you spell it with one word or two, multiclass or multi class classification; the fundamental premise is the same either way. It is the most frequently used algorithm used in machine learning problems.
It is an example of multi-class classification to use a machine learning model to identify animal species in encyclopaedia photographs. This is because each image may be classed as multiple different animal categories, thus the model must be able to distinguish between them. It is essential to use just one class in the sample while doing multiclass classification. Understanding multi class algorithm in data mining begins with understanding data science; you can get an insight into the same through our Data Science training.
In order to determine which of K classes certain data that has not been seen yet belongs to, we train the model using a set of samples that have been categorised according to K different criteria. The model takes into account the patterns that are specific to each class in the training dataset. It then uses these patterns to make predictions regarding the class membership of data that has not yet been seen.
The act of organising data into separate groups according to the properties they share is what we mean when we talk about classification. The characteristics of a dataset, often known as its independent variables, are extremely important to our data categorization. The concept of "multi class classification" refers to a scenario in which the dependent or target variable consists of more than two distinct categories. This is something that can be easily recognised.
The building of the categorization model makes use of a technique known as the decision tree approach, which employs the use of a tree-like structure known as a decision tree. Because the principles of if-then that it employs to classify objects are comprehensive and exclusive, nothing can be placed in more than one of those boxes at a time. After that, the information is split up into subgroups and an incremental decision tree is used to link the nodes in those subsets. The end product is something that resembles the limbs and leaves of a tree. The training data are what are utilised in order to learn the rules one at a time.
When a rule is discovered, the tuples that are discovered to come inside its purview are eliminated. On the training set, the procedure is carried out repeatedly until the desired end point is reached. Neighbors who are within k metres of you - This method of learning is known as "lazy learning," and it use an n-dimensional space and remembers the totality of the space even when it includes training data. It is lazy because it cannot generalise since it just retains snippets of the training data and not the complete thing. This prevents it from being able to learn new things. A majority vote from a point's k nearest neighbours is required in order to designate that point to a category.
The approach is supervised and makes use of a collection of labelled points in order to create additional labels for points that have not been tagged. Finding a point's nearest neighbours, also known as neighbouring labelled points, is the first step in the process of labelling a new point. The people in the area around the new point are surveyed, and the winning label is applied to the location. There are many approaches to multiclass classification algorithm in machine learning. You can learn the six stages of data science processing to better grasp the above topic.
Let’s have a look at some of the most used multiclass cliassfication algorithm in machine learning.
In order to expedite the generation process, parametric learning algorithms such as Naive Bayes make use of a set of assumptions or parameters that have been specified in advance. There is no correlation between the quantity of the training data and the number of parameters that are utilised in parametric algorithms.
Application of The Naive Bayes Assumption in An Incorrect Manner
It is based on the assumption that any individual attribute in a dataset may be analysed independently of the others. On the other hand, given how infrequently this occurs, we sometimes refer to this approach as "naive."
The model is a conditional probability classification technique that makes use of Bayes' theorem to create predictions about the kind of data set that is currently unknown. These predictions may be used to inform future research. This model is often utilised for large datasets as a result of its user-friendliness and its lightning-fast training and prediction times, respectively. In addition to this, it is possible for it to outperform rival algorithms without any hyperparameter tweaking being required.
Naive Bayes has also been shown to be a good text classifier in other contexts, such as the spam ham dataset.
The following is a formal representation of Bayes's theorem:
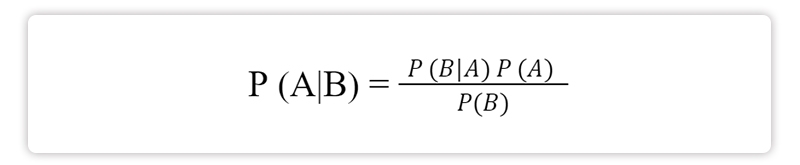
P (A|B) is the likelihood of event A occurring given the reality of event B. This is abbreviated as the probability. This idea is sometimes referred to as "posterior probability," which is a word that explains the notion.
The second category of evidence is called "event B."
P (A) is the likelihood of occurrence of A antecedent to any evidence of A having been observed; hence, the term "a priori of A" describes this concept.
The connection between two occurrences is sometimes referred to using the terms conditional probability and likelihood, which are abbreviated as P (B|A).
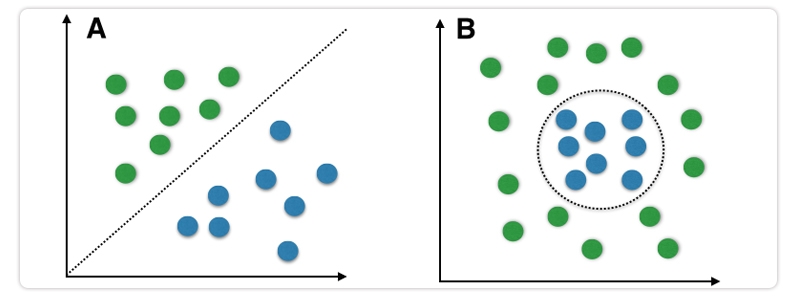
It is important to keep in mind that Naive Bayes is a linear classifier; as a result, it is possible that it will not operate effectively with data sets the classes of which are not linearly separated.
When it comes to non-linear classification, however, the Naive Bayes algorithm may be replaced with alternative classifiers like the KNN algorithm.
KNN is a supervised machine learning algorithm that may be used to address problems with classification as well as regression. The algorithm is powerful despite being one of the easiest to understand. It just memorises the information rather than forming an accurate discriminative function based on the training data. It is referred to as a "lazy algorithm" for the same same reason, which is why it is sometimes called that.
The Question Now is, How Does it Work?
The K-nearest neighbour method first determines whether or not two data points are comparable by utilising a distance measure between them to establish a baseline, and then generates a majority vote based on the K instances that are the most comparable to one another. The Euclidean distance, which may be represented using the formula, is by far the most common choice.
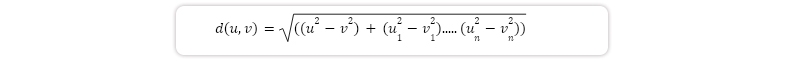

The letter "K" in "K-Nearest Neighbors" refers to a hyperparameter that may be modified in order to get the best possible dataset fit. If we continue with the smallest feasible value for K, which would be K=1, then the model will demonstrate low bias but large variance. This is due to the fact that our model would be too perfect. Our decision border, on the other hand, will become smoother if we select a bigger value for K—assume let's we choose k=10—which will result in less variety and more bias. As a consequence of this, we endeavour to strike a balance between the two, sometimes known as a bias-variance trade-off.
In data mining, the supervised learning technique of Decision Tree is utilised for classification and regression. There's a tree there that aids with selecting choices. Tree-like models for classification or regression can be generated using the decision tree. While the decision tree is being created, the data set is partitioned into smaller subgroups. As a result, we get a decision tree with leaf nodes upon its completion. At the very least, a decision node will have two forks. Classification or a final verdict is represented by the leaf nodes. Leaf nodes are the topmost decision nodes in a tree and are connected to the best predictor, also known as the root node. Decision trees are flexible enough to handle both numerical and categorical information.
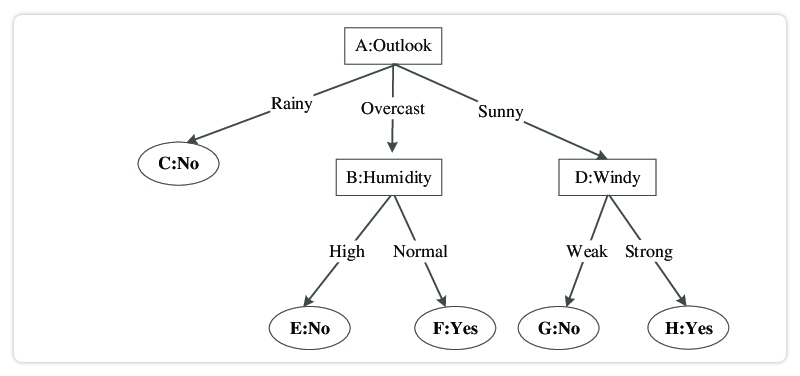
Support vector machines are a popular and powerful machine learning algorithm that has been used in various applications such as image classification, text classification, and bioinformatics. One of the main advantages of support vector machines is its ability to handle high-dimensional data with a small number of samples. This is achieved by finding the hyperplane that maximally separates the classes while minimizing the margin between them as shown in figure. Support vector machines have also been shown to outperform other algorithms such as logistic regression and decision trees in certain scenarios.
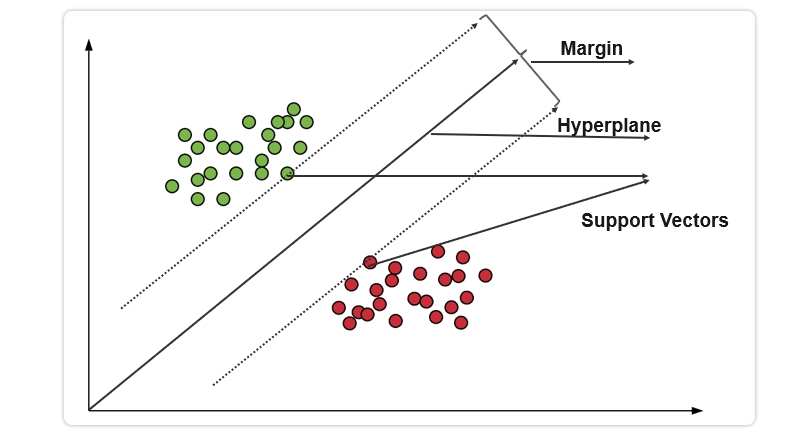
For example, a study conducted by Chen et al. (2016) compared different machine learning algorithms for predicting breast cancer recurrence using gene expression data. The results showed that support vector machines had the highest accuracy among all tested models with an area under the curve (AUC) value of 0.77.Another advantage of support vector machines is their ability to handle non-linearly separable data by using kernel functions such as radial basis function or polynomial kernels. This allows for more flexible decision boundaries that can better capture complex relationships between input features.However, one limitation of support vector machines is their sensitivity to outliers which can affect model performance and lead to overfitting if not properly addressed. Additionally, training time can be slow for large datasets due to their computational complexity.Overall, support vector machines are a versatile and effective algorithm for various machine learning tasks but require careful consideration when dealing with outliers or large datasets.
Random Forest is a popular machine learning algorithm that has gained significant attention in recent years due to its ability to handle complex datasets and improve prediction accuracy. The algorithm works by combining multiple decision trees, each trained on a subset of the data, to create an ensemble model. This approach reduces overfitting and increases generalization performance, making it suitable for various applications such as image classification, fraud detection, and customer segmentation. Research shows that Random Forest outperforms other algorithms in several domains and can achieve high accuracy with smaller sample sizes compared to traditional statistical methods. For instance, a study comparing different classifiers for breast cancer diagnosis found that Random Forest had the highest sensitivity (97%) and specificity (94%), indicating its potential use in clinical settings. Additionally, another research demonstrated the effectiveness of Random Forest in predicting stock prices using financial indicators with an accuracy of 83%. Therefore, Random Forest presents itself as a promising tool for solving real-world problems where accurate predictions are essential.
In machine learning, unlike binary classification algorithms, that can only predict one of two classes, multiclass algorithms are capable of predicting and distinguishing several classes. Multiclass classification algorithm are used when the data set has more than two classes that need to be predicted. This type of algorithm is particularly used when dealing with complex data sets with multiple categories or classes. The following are some of the most popular uses of multiclass classification:
Data Science Training For Administrators & Developers

Multiclass classification is a powerful tool that enables us to classify data into multiple categories. We have discussed how it differs from binary classification and the various algorithms used in this process. With the growing need for more accurate predictions in a wide range of industries, mastering multiclass classification is becoming increasingly important. As you embark on your journey to become an expert in this field, remember to choose the appropriate algorithm based on your dataset and problem at hand. Keep experimenting with different techniques until you find one that works best for your specific needs. To sum up, whether you're working with image recognition or natural language processing, mastering multiclass classification can give you an edge over others and help drive better results for your business or research project. You can also learn about neural network guides and python for data science if you are interested in further career prospects in data science.

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  12k
12k
What is Model Evaluation and Selection in Data Mining?
Mar 28, 2023 12k

Rule-Based Classification in Data Mining
Mar 27, 2023 11.6k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







