Grab Deal : Upto 30% off on live classes + 2 free self-paced courses - SCHEDULE CALL
In the field of data science, classification is a common task that involves categorizing data into different classes or groups. Supervised classification is one approach where labeled training data is used to train a model to classify new, unseen data. However, this method requires a large amount of labeled data which can be expensive and time-consuming to obtain. This is where a semi-supervised classification is an alternative approach that utilizes labeled and unlabeled data for training models. Let's dive more into the topic of semi-supervised classification and learn more about its importance in data science and key takeaways. You should check out the data science tutorial guide to brush up your basic concepts. This blog post will explore what semi-supervised classification entails and provide some examples.
Cluster analysis is a data-partitioning technique that puts together sets of data that have similarities while being distinct. Unsupervised approaches are typically used while performing clustering. Finding patterns of similarity and dissimilarity among data points can be done without prior knowledge of the relationships among the data items.
However, there are cases where at least part of the data's cluster labels, outcome variables, or information about linkages are already known. To solve this problem, we may use a technique called semi-supervised clustering. Just like semi supervised machine learning, semi supervised clustering makes use of both labeled and unlabeled data to categorize new data.
Semi-supervised classification refers to the process of using both labeled and unlabeled datasets for training machine learning models. The goal is to leverage the information contained within the unlabeled dataset while utilizing the limited number of labels available in supervised learning scenarios.
The idea behind semisupervised learning stems from the fact that obtaining labeled datasets can be very costly and time-consuming, especially when dealing with complex problems such as image recognition or natural language processing (NLP). By leveraging large amounts of unlabelled data alongside small labeled sets, it becomes possible to build more robust models with better generalization capabilities.
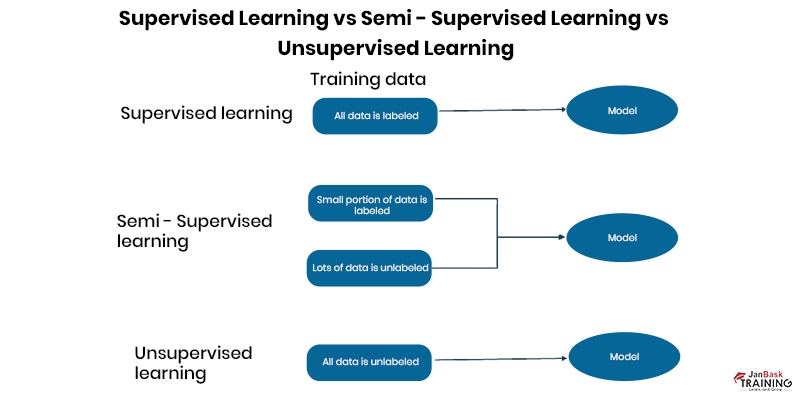
Understanding the difference between supervised and unsupervised learning is helpful for grasping semi-supervised learning.
Learning from data is essential for any machine learning model or algorithm. Models for supervised learning are often trained using labeled datasets. However, coming across sufficient amounts of labeled data for training can be challenging. Because of this, labeled data is used to make predictions about the label and then reduce the difference between the forecast and the label.Because unsupervised models learn to recognize patterns and trends or to categorize data without labeling it, unsupervised learning does not require labeled data. Since most data isn't labeled, this expands the pool of information that may be used for unsupervised learning.
Semisupervised learning combines unsupervised methods like clustering or dimensionality reduction techniques with supervised algorithms such as decision trees or neural networks. The first step involves partitioning all available samples into two categories; those with known labels (supervision) and those without labels (unsupervision).
Next, unsupervised algorithms are applied to these unlabelled samples so as to extract meaningful features from them, which are then used together with labeled samples during the model-building phase.During training, the algorithm predicts class membership based on the available labels and features extracted from unlabelled data. The algorithm then updates its model based on how well it predicts class membership for labeled and unlabelled samples.
Both labeled and unlabeled data are utilized in the process of building a classifier using the semi-supervised classification strategy.The labeled data set may be thought of as Xl = (x1, y1),..., xl, yl), while the unlabeled data set can be thought of as Xu = (xl+1,...,xn). This is a useful way to think about the data sets. This article will describe several ways this educational style can be used.
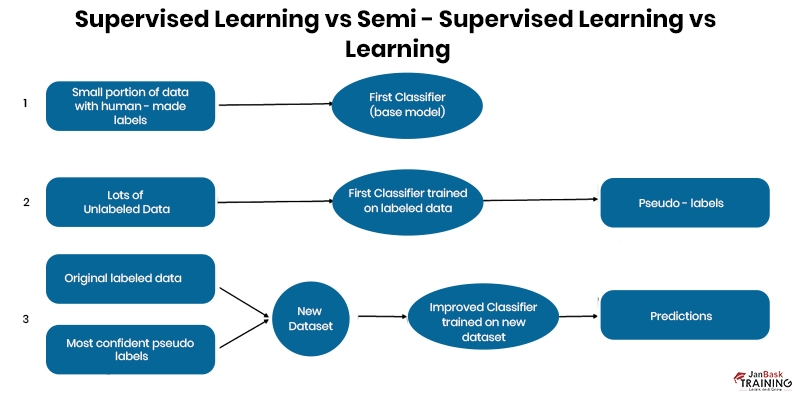
When it comes to classification that is just semi-supervised, self-training is the minimum required. At first, a classifier is built by employing the annotated data as a building block. The classifier will then try to ascribe labels to the raw data. The tuple whose label prediction is the most certain at each iteration is the one that is added to the pool of labeled data. The method is uncomplicated, but there is a risk that it will encourage the development of undesirable routines.
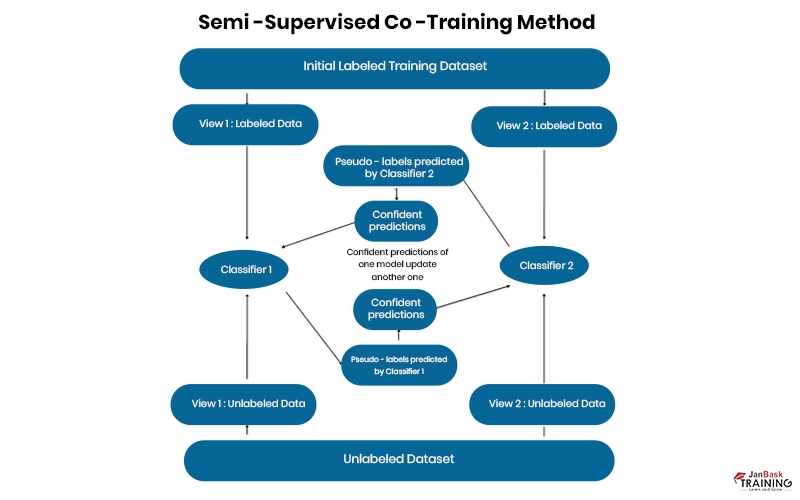
Co-Training is another kind of semi-supervised classification. In this method, two or more classifiers teach one another about the categorized data. Each learner uses their own one-of-a-kind set of attributes for each tuple, which should ideally not be connected to one another. Take, for instance, the data on a web page as an illustration; one set of features may be tied to the images on the website, whilst another set of features may be related to the text on the page. Every one of those sets in its entirety.
Let's pretend we do this and train two classifiers, f1 and f2, where each is trained on a subset of the feature set. Then, the class labels for Xu's unlabeled data are predicted using f1 and f2. As a result, the two classifiers are able to learn from one another, as the tuple with the highest confidence prediction from f1 is added to the collection of labeled data for f2 (along with its label).
Similarly, we append the tuple with the highest confidence prediction from f2 to our f1 annotated data collection. The procedure has been outlined above. When compared to self-training, co-training is more forgiving of slip-ups. One potential issue is that it may not be feasible to partition the features into independent and class-conditional sets, which is a precondition for their use.Some methods of semi-supervision can be used for learning. For instance, the combined probability distribution of characteristics and labels can be modeled. As such, the labels can be disregarded while working with the unlabeled data. If you want to increase your model's reliability, use the EM algorithm. Additionally, methods based on support vector machines have been presented.
Python example of semi supervised text classification code:
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.preprocessing import FunctionTransformer
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.semi_supervised import SelfTrainingClassifier
from sklearn.semi_supervised import LabelSpreading
from sklearn.metrics import f1_score
# Loading dataset containing first five categories
data = fetch_20newsgroups(
subset="train",
categories=[
"alt.atheism",
"comp.graphics",
"comp.os.ms-windows.misc",
"comp.sys.ibm.pc.hardware",
"comp.sys.mac.hardware",
],
)
print("%d documents" % len(data.filenames))
print("%d categories" % len(data.target_names))
print()
# Parameters
sdg_params = dict(alpha=1e-5, penalty="l2", loss="log_loss")
vectorizer_params = dict(ngram_range=(1, 2), min_df=5, max_df=0.8)
# Supervised Pipeline
pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", SGDClassifier(**sdg_params)),
]
)
# SelfTraining Pipeline
st_pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", SelfTrainingClassifier(SGDClassifier(**sdg_params), verbose=True)),
]
)
# LabelSpreading Pipeline
ls_pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
# LabelSpreading does not support dense matrices
("toarray", FunctionTransformer(lambda x: x.toarray())),
("clf", LabelSpreading()),
]
)
def eval_and_print_metrics(clf, X_train, y_train, X_test, y_test):
print("Number of training samples:", len(X_train))
print("Unlabeled samples in training set:", sum(1 for x in y_train if x == -1))
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(
"Micro-averaged F1 score on test set: %0.3f"
% f1_score(y_test, y_pred, average="micro")
)
print("-" * 10)
print()
if __name__ == "__main__":
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
print("Supervised SGDClassifier on 100% of the data:")
eval_and_print_metrics(pipeline, X_train, y_train, X_test, y_test)
# select a mask of 20% of the train dataset
y_mask = np.random.rand(len(y_train)) < 0.2
# X_20 and y_20 are the subset of the train dataset indicated by the mask
X_20, y_20 = map(
list, zip(*((x, y) for x, y, m in zip(X_train, y_train, y_mask) if m))
)
print("Supervised SGDClassifier on 20% of the training data:")
eval_and_print_metrics(pipeline, X_20, y_20, X_test, y_test)
# set the non-masked subset to be unlabeled
y_train[~y_mask] = -1
print("SelfTrainingClassifier on 20% of the training data (rest is unlabeled):")
eval_and_print_metrics(st_pipeline, X_train, y_train, X_test, y_test)
print("LabelSpreading on 20% of the data (rest is unlabeled):")
eval_and_print_metrics(ls_pipeline, X_train, y_train, X_test, y_test)
Semi-supervised learning has been applied to various fields such as image recognition, natural language processing, speech recognition, anomaly detection, and more. Here are some applications of semi supervised learning examples:
Semi-supervised classification is an alternative approach to supervised learning that utilizes labeled and unlabeled datasets to train machine learning models. By combining unsupervised techniques with supervised algorithms, semi-supervised methods help improve generalization capabilities while reducing the need for expensive labeling processes. With numerous successful applications across different domains like image recognition, NLP, etc., it's clear that semi-supervised approaches will continue playing an important role in advancing machine learning research going forward. Understanding semi supervised classification in machine learning begins with understanding data science; you can get an insight into the same through our data science training.
Data Science Training For Administrators & Developers

FAQ’s
Q.1. What are Supervised and Unsupervised Classifications?
Ans. Supervised classification is a machine learning technique where the algorithm learns from labeled training data to classify new, unseen data. On the other hand, unsupervised classification involves clustering or grouping data without prior knowledge or labels.
Q.2. What is an Example of Supervised Classification?
Ans. An example of supervised classification is spam email detection. By training a classifier with a labeled dataset of emails (spam or not spam), the algorithm can learn patterns and features to accurately classify new, unseen emails as either spam or legitimate.
Q.3. What is Supervised Classification Used for?
Ans. Supervised classification is widely used in various domains, including image recognition, sentiment analysis, fraud detection, and medical diagnosis. It allows data scientists to build models to classify and predict outcomes based on known patterns and labeled data.
Q.4. How can I learn supervised classification? Is there a Data Scientist Course Online?
Ans. Yes, there are several online data science courses available that cover supervised classification techniques. These courses typically provide a comprehensive understanding of machine learning algorithms, including supervised classification, and teach you how to apply them to real-world problems.
Q.5. Can Semi-Supervised Learning be Considered a Form of Supervised Classification?
Ans. Semi-supervised learning combines aspects of both supervised and unsupervised learning. While it utilizes labeled data for training, it also leverages unlabeled data to improve classification accuracy. So, while it shares similarities with supervised classification, it is considered a distinct approach that extends beyond the traditional supervised learning paradigm.

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  10.9k
10.9k Mar 03, 2023 10.5k
Mar 03, 2023 10.5k

Rule-Based Classification in Data Mining
Mar 27, 2023 10.3k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







