Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
As data scientists, we are always on the lookout for ways to make sense of large and complex datasets. One popular technique used for this purpose is agglomerative hierarchical clustering. This blog post will explore agglomerative clustering, its definition, how it works in Python, and why it's important. Understanding agglomerative hierarchical clustering in data mining begins with understanding data science; you can get an insight into the same through our Data Science training.

Agglomerative clustering is a type of hierarchical clustering that involves grouping similar objects together based on their distance. The process starts with each object being treated as its own cluster and then iteratively merging the two closest clusters until all objects belong to one cluster.In simple terms, imagine you have a group of people standing apart from each other. You want to form groups based on who stands close to whom. You start by pairing up the two closest people into a group and continue doing so until everyone belongs to one big group.
Agglomerative clustering is a bottom-up approach where each object initially forms its own cluster and then gradually merges with other clusters based on some distance metric until all the objects belong to one large cluster. This process creates a hierarchy of nested clusters that a dendrogram can represent.
The basic steps involved in agglomerative clustering are:
1) Assign each object to its own initial cluster
2) Compute pairwise distances between all pairs of clusters
3) Merge the two closest clusters into one new larger cluster
4) Recompute pairwise distances between this newly merged cluster and all other remaining ones.
5) Repeat steps 3-4 until all objects belong to one large final cluster.
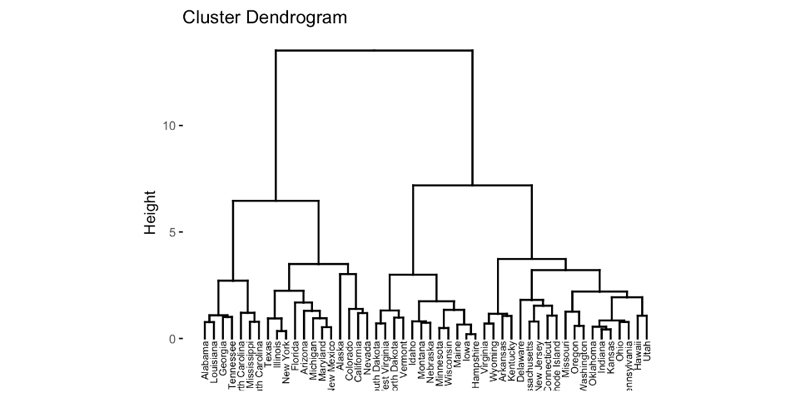
A dendrogram is a tree-like diagram that displays the hierarchical relationships between different levels of nested clusters created during agglomerative clustering. Each level represents a different stage of merging smaller sub-clusters into larger ones until reaching the final big cluster at the root node.
Dendrograms provide visual representations for understanding how closely related different groups or subgroups are within your dataset by showing which items share common characteristics or attributes over time as they merge together through successive iterations using various linkage methods such as complete-linkage, single-linkage, or average-linkage.
Agglomerative linkage refers to the method used to calculate distances between clusters during agglomerative clustering. There are several types of linkage methods, such as complete, single, and average.
Complete-Linkage: This method computes the distance between two clusters by taking the maximum pairwise distance between any two points in each cluster. It tends to produce compact and well-separated clusters but can be sensitive to outliers.
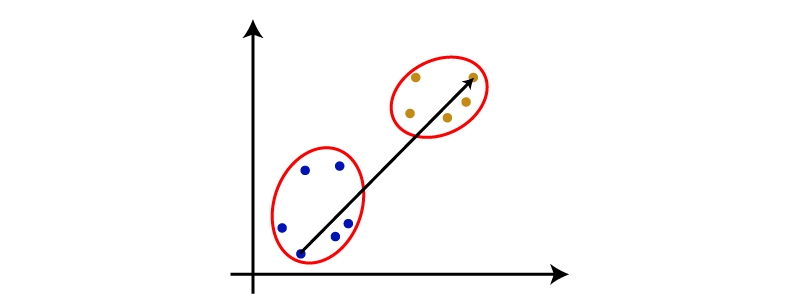
Single-Linkage: This method computes the distance between two clusters by taking the minimum pairwise distance between any two points in each cluster. It tends to produce long chains of connected objects that may not be very meaningful for some datasets.

Average-Linkage: This method computes the distance between two clusters by averaging all pairwise distances among their members. It balances out both extremes of complete and single linkages and produces more balanced dendrograms with moderate-length branches.
Centroid Linkage: The distance between the centroids is calculated in this type of linkage.
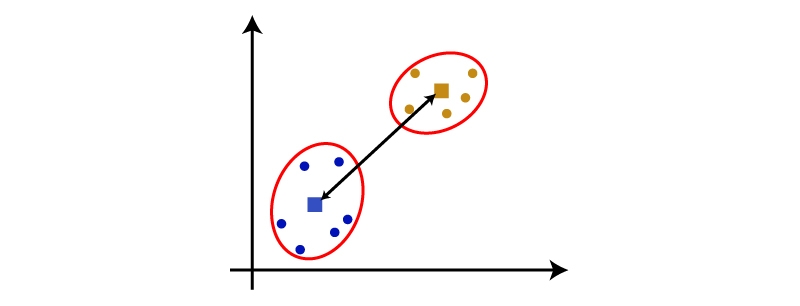
You can choose any of the above approaches as per the types of problem or business requirement. It's a key component of the machine learning cycle's data processing and preparation stages.
Python has several libraries that can perform agglomerative hierarchical clusterings, such as Scikit-learn, SciPy, or PyClustering. Here's an example using Scikit-learn:
```python from sklearn.cluster import AgglomerativeClustering import numpy as np # create sample data X = np.array([[1,2],[3,4],[5,6]]) # perform agglomeration with 2 clusters agg_clust = AggolomerartiveClustering(n_clusters=2) agg_clust.fit(X) # print resulting labels print(agg_clust.labels_) ```
In this example, we create a sample dataset with three points and then perform agglomerative clustering to group them into two clusters. The resulting labels tell us which cluster each point belongs to.
Agglomerative clustering has several advantages over clustering techniques such as k-means or DBSCAN. Firstly, it can handle non-linearly separable data - that is, data that cannot be separated by a straight line or plane. Secondly, it does not require the number of clusters to be specified beforehand - the algorithm determines the optimal number of clusters based on the data itself.
Furthermore, agglomerative clustering can provide valuable insights into how different groups within a dataset are related. By visualizing the dendrogram (a tree-like diagram showing how objects are grouped together), we can see which are most similar and which are least similar.
Applications of Agglomerative Hierarchial Clustering
The term "agglomerative" comes from the Latin word "agglomero," which means "to gather into a ball." This accurately describes what happens during agglomerative clustering - individual points are gathered into larger groups or clusters.
Customer Segmentation
One common application of agglomerative clustering is customer segmentation. By grouping customers based on similarities, businesses can tailor their marketing strategies and improve customer satisfaction. For example, an e-commerce company may use demographic information such as age, gender, income level, and location to segment its customers into different groups. Using Python's scikit-learn library for agglomerative clustering allows for easy implementation of this technique.
Image Segmentation
Another application of agglomerative clustering is image segmentation. This involves dividing an image into regions with similar characteristics, such as color or texture. Agglomerative clustering can be used to group pixels together based on these characteristics and create distinct segments within the image.
Gene Expression Analysis
Agglomerative hierarchical clustering can also be applied in gene expression analysis, where researchers aim to identify co-expressed genes across different samples or conditions. By analyzing patterns in gene expression levels across samples using linkage methods like Ward's minimum variance criterion or complete linkage criteria, scientists can identify groups of highly correlated genes.
Anomaly Detection
Agglomerative hierarchical clustering can also be useful for anomaly detection by identifying outliers within a dataset that do not fit well with any existing clusters. These anomalies could represent errors or unusual behavior within the dataset that require further investigation. By using Python's scikit-learn library for agglomerative clustering, it is possible to detect these anomalies and take appropriate action.
Data Science Training For Administrators & Developers

Agglomerative hierarchical clustering is an important technique in data science for grouping similar objects based on their distance. It involves iteratively merging the two closest clusters until all objects belong to one cluster. Python has several libraries that can perform agglomerative hierarchical clusterings, such as Scikit-learn, SciPy, or PyClustering. Agglomerative clustering has several advantages over other techniques, such as k-means or DBSCAN. It provides valuable insights into how different groups within a dataset are related to each other through dendrograms visualization.
Overall, understanding agglomerative hierarchical clustering is essential for any data scientist looking to effectively make sense of large and complex datasets. You can also learn about neural network guides and python for data science if you are interested in further career prospects in data science.

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  12.1k
12.1k
What is Model Evaluation and Selection in Data Mining?
Mar 28, 2023 12.1k

Rule-Based Classification in Data Mining
Mar 27, 2023 11.7k
Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







