Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Data from internal records, customer service encounters, and the worldwide web are just a few of the many avenues open to businesses for making educated decisions and growing their operations. But, you must first perform data preprocessing before using it.
Because you can't just take unprocessed data and start feeding it into machine learning, data science, and analytics tools, before machines can "read" or comprehend your data, you must preprocess it.
Find out what preprocessing data is, why it's so important, and how to do it in this step-by-step tutorial for data mining.
Data preprocessing is a phase in the process of data mining and data analysis that involves transforming raw data into a format that can be understood by computers and analyzed using machine learning. This step takes raw data and changes it into a format that can be used.Raw data, which comes from the actual world and might be in the form of text, photographs, video, and so on, is untidy. It is not only possible to have mistakes and inconsistencies, but it also frequently lacks a regular, consistent design and may contain faults and inconsistencies.Information that is neat and organized is easier for machines to process since they read data as a series of ones and zeros. Therefore, it is not difficult to do calculations using structured data, such as whole numbers and percentages. However, in order to conduct an analysis, the unstructured data, which might be in the form of text or images, must first be cleaned and prepared.
When it comes to training machine learning models using data sets, the adage "garbage in, garbage out" is one that you'll hear quite a little. This implies that if you train your model using inaccurate or "dirty" data, the resulting model will be inaccurate and incorrectly trained, and it will not contribute anything useful to your research.As you know, ML is a data analysis technique, and data scientists need to know ML. If you lack clarity on the role of a data scientist, refer to data science career path.It is even more vital to have good, preprocessed data than it is to have the most powerful algorithms. In fact, machine learning models that are trained with bad data might potentially be destructive to the analysis you are attempting to accomplish - giving you "junk" findings.
You can wind up with data that is outside of the range you were expecting, or that has an erroneous feature due to the methods and sources you used to collect the data. For example, the family income might be below zero, or an image from a collection of "zoo animals" might really be a tree. It's possible that some of the fields or values in your set are missing. Or, take textual data as an example; it will frequently contain misspelled words and symbols, URLs, and the like that are useless.If you take the time to preprocess and clean your data correctly, you'll put yourself in a position to perform downstream procedures with much more precision. We frequently hear about the significance of "data-driven decision making," but if incorrect data drive the judgments being made, then those decisions are just terrible.
Data preprocessing is a method used to tidy up unstructured data. In other words, the data is always captured in a raw format, which makes further analysis impossible.
Understanding Machine Learning Data Features
It is possible to transmit information about data sets by referring to the "features" that constitute them. This may be done based on size, location, age, time, color, and so on. Features are sometimes referred to as attributes, variables, fields, and characteristics and are organized in datasets in the form of columns.
When preprocessing data, it is crucial to have a solid understanding of what "features" are since you will need to pick which ones to concentrate on based on the objectives you wish to achieve for your company. In the following sections, we will describe how you may increase the quality of your dataset's features and the insights you acquire via techniques such as feature selection.
To begin, let's go through the two distinct types of features that are used to characterize data: categorical and numerical features:
Data Preprocessing is a data mining technique used to transform the raw data into a useful and efficient format. There are different tasks of data preprocessing.

In order to gauge the general quality, applicability to your project, and consistency of the data, you need to examine it closely. There are a variety of outliers and other issues that might crop up in any data set.
"Data Cleaning" refers to completing a data collection by filling in any gaps and fixing or deleting any mistakes or extraneous information. Cleaning your data is the most crucial part of preprocessing since it ensures your information is used for further processing.
All inconsistencies in your data quality evaluation may be fixed with a thorough data cleansing. There are a variety of cleansers you may need to apply to your data, and the ones you choose will depend on the specifics of your situation.
There are a number of ways to correct missing data, but the two most common are:
Resolving "noisy" data is another part of the data cleansing process. These details lack context, are irrelevant, and are more difficult to categorize.
If you’re working with text data, for example, some things you should consider when cleaning your data are:
It's possible that after cleansing the data, you'll find that there isn't enough of it for your purpose. You may now execute data wrangling or enrichment to include additional data sets into your existing data, after which you can rerun quality assessment and cleaning on the combined dataset. If you are interested in a career path for data science, we have a complete guide to help you with your new career opportunities and growth.
Data transformation is the next step after data cleansing, and it involves converting the data into the format(s) needed for analysis and other subsequent procedures..
This generally happens in one or more of the below:
1. Aggregation
2. Normalization
3. Feature selection
4. Discretization
5. Concept hierarchy generation
Aggregation: When you aggregate data, you compile all of your data into one standardized set.
Normalization: Data normalization aims to provide a consistent scale for comparisons across datasets. If you want to compare organizations of varying sizes (some may have a dozen workers, while others may have 200+), you'll need to scale their employee loss or growth within a certain range, such as -1.0 to 1.0 or 0.0 to 1.0.
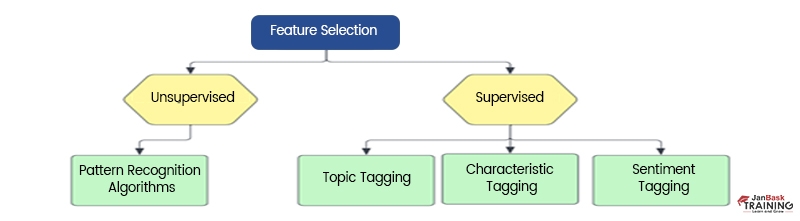
Feature selection: Feature selection refers to determining which variables (features, characteristics, categories, etc.) will have the most impact on analysis. Machine learning (ML) models will be trained with these characteristics. Keep in mind that some feature qualities may overlap or be less prominent in the data if you employ too many features, which can make the training process longer and occasionally produce less accurate results.
Discretization: Discrediting collects information into more manageable chunks. It's a lot like binning, although it often takes place after data cleansing. Instead of utilizing the precise number of minutes and seconds, for instance, you may aggregate data to form categories like "exercised between 0 and 15 minutes per day," "exercised between 15 and 30 minutes per day," etc.
Concept Hierarchy Generation: With the help of concept hierarchy creation, you may create a structure for your features that wasn't there before. Include the genus hierarchy if your study includes canids like wolves and coyotes. canis.
After data cleansing and transformation, analyzing larger datasets becomes more challenging. Sometimes there might be too much information rather than too little, depending on the task at hand. Some of what people often say is unnecessary or unimportant to the research at hand, especially when dealing with text analysis. By eliminating unnecessary information, data reduction facilitates a more precise analysis and reduces the volume of data that must be stored.
It will also aid in determining which aspects of the process are most crucial.
Data Science Training For Administrators & Developers

To enable the machine learning model to read and learn from the data set, data must first be preprocessed. A machine-learning model can learn when the input has no repetition, no noise (outliers), and only numerical values.So, we spoke about how to train a machine learning model to use the kind of data it can best understand, learn from, and perform each time. Are you still feeling undecided about whether to pursue a Data Science career? What does a data scientist do? Or are you looking for more detailed Data science career advice? Schedule a free Data science career counseling with us.
FAQ’s
What are Major Tasks of Data Preprocessing?
Answer: Data quality assessment, data cleaning, data transforming and data reduction.
Importance of Data Preprocessing?
Answer: The primary goal of data preprocessing is quality assurance. All of the following serve as quality indicators:
Accuracy:
Credibility:
What Data Transformation Techniques in Data Mining?
Answer: Aggregation
Normalization
Feature selection
Discretization
Concept hierarchy generalization

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  12.2k
12.2k
What is Model Evaluation and Selection in Data Mining?
Mar 28, 2023 12.2k

Rule-Based Classification in Data Mining
Mar 27, 2023 11.8k
Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







