Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Gradient-based learning is the backbone of many deep learning algorithms. This approach involves iteratively adjusting model parameters to minimize the loss function, which measures the difference between the actual and predicted outputs. At its core, Gradient-based learning leverages the gradient of the loss function to navigate the complex landscape of parameters. In this blog, let’s discuss the essentials of Gradient-Based Learning, and if this blog excites you for more, you can always dive into our Deep Learning Courses with Certificates online.
Learning Conditional Distributions with Max Likelihood
Maximizing likelihood is finding parameter values that make the observed data most probable. This is often expressed as

This involves understanding the relationships between variables and focusing on the conditional expectation. The goal is to minimize the difference between predicted and actual values, often using mean squared error (MSE) as a cost function.
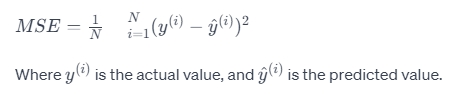
The linear unit is used for outputs resembling a Gaussian distribution. The output is a linear combination of inputs:

These units are used for binary outcomes, modeled as
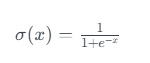
This function maps any input to a value between 0 and 1, ideal for binary classification.
For multi-class classification, the softmax function, which generalizes the sigmoid function for multiple classes, is used.
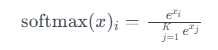
Deep learning can handle various output types, with specific functions tailored to different data distributions.
Role of an Optimizer in Deep Learning

Optimizers are algorithms designed to minimize the cost function. They play a critical role in Gradient-based learning by updating the weights and biases of the network based on the calculated gradients.
Consider a hiker trying to find the lowest point in a valley. They take steps proportional to the steepness of the slope. In deep learning, the optimizer works similarly, taking steps in the parameter space proportional to the gradient of the loss function.
Instances of Gradient Descent Optimizers
This optimizer calculates the gradient using the entire dataset, ensuring a smooth descent but at a computational cost. The update rule is

SGD updates parameters for each training example, leading to faster but less stable convergence. The update rule is:
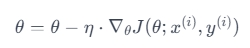
MB-GD strikes a balance between GD and SGD by using mini-batches of the dataset. It combines efficiency with a smoother convergence than SGD.
Challenges with All Types of Gradient-Based Optimizers
The journey of mastering Gradient-based learning in deep learning has its challenges. Each optimizer in deep learning faces unique hurdles that can impact the learning process:
Learning Rate Dilemmas: One of the foremost challenges in Gradient-based learning is selecting the optimal learning rate. A rate too high can cause the model to oscillate or even diverge, missing the minimum—conversely, a rate too low leads to painfully slow convergence, increasing computational costs.
Local Minima and Saddle Points: These are areas in the cost function where the gradient is zero, but they are not the global minimum. In high-dimensional spaces, common in deep learning, these points become more prevalent and problematic. This issue is particularly challenging for certain types of optimizers in deep learning, as some may get stuck in these points, hindering effective learning.
Vanishing and Exploding Gradients: A notorious problem in deeper networks. With vanishing gradients, as the error is back-propagated to earlier layers, the gradient can become so small that it has virtually no effect, stopping the network from learning further. Exploding gradients occur when large error gradients accumulate, causing large updates to the network weights, leading to an unstable network. These issues are a significant concern for Gradient-based learning.
Plateaus: A plateau is a flat region of the cost function. When using Gradient-based learning, the learning process can slow down significantly on plateaus, making it difficult to reach the minimum.
Choosing the Right Optimizer: With various types of optimizers in deep learning, such as Batch Gradient Descent, Stochastic Gradient Descent (SGD), and Mini-batch Gradient Descent (MB-GD), selecting the right one for a specific problem can be challenging. Each optimizer has its strengths and weaknesses, and the choice can significantly impact the efficiency and effectiveness of the learning process.
Hyperparameter Tuning: In Gradient-based learning, hyperparameters like learning rate, batch size, and the number of epochs need careful tuning. This process can be time-consuming and requires both experience and experimentation.
Computational Constraints: Deep learning models can be computationally intensive, particularly those that leverage complex Gradient-based learning techniques. This challenge becomes more pronounced when dealing with large datasets or real-time data processing.
Adapting to New Data Types and Structures: As deep learning evolves, new data types and structures emerge, requiring adaptability and innovation in Gradient-based learning methods.
These challenges highlight the complexity and dynamic nature of Gradient-based learning in deep learning. Overcoming them requires a deep understanding of both theoretical concepts and practical implementations, often covered in depth in our Certified Deep Learning Course.
Mastering Gradient-based learning in deep learning requires a deep understanding of these concepts. Enrolling in Deep Learning Courses with Certificates Online from JanBask Training can provide structured, comprehensive insights into these complex topics. These courses combine theoretical knowledge with practical applications, equipping learners with the skills needed to innovate in deep learning.

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  12.1k
12.1k
What is Model Evaluation and Selection in Data Mining?
Mar 28, 2023 12.1k

Rule-Based Classification in Data Mining
Mar 27, 2023 11.7k
Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment










