 Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
It's no secret that the present job market is extremely cutthroat, and overcoming the first obstacle of job application could be a challenge in itself. Once you cross this first hurdle, the hard way toward finding a new job career has now barely begun. The RDBMS field is among the highly competitive fields, specifically because so many job hunters are vying for such limited job openings. You must be at your best to emerge from the crest of the competitors. The easiest way to achieve this is to be well-versed using RDBMS interview questions.
In this blog post, we’ll review the 117 RDBMS viva questions you will likely be asked during an interview and how to answer them. Also, consider joining a credible data management courses to sharpen your skill sets.
Let’s get started with the RDBMS questions and answers. This series of RDBMS basic interview questions and RDBMS technical interview questions will cover in-depth information about relational DBMS.
RDBMS stand for a relational database management system that stores the data in tables, and you can easily access it even through another database. It is the basis for sql, oracle, Microsoft Access, and IBM DB2. excellent RDBMS knowledge is required for RDBMS-related job roles.
Below is a quick list of RDBMS interview questions and answers:
RDBMS refers to storing or managing data across numerous database tables. The most advantageous part of relational database management is that you can state relationships between various data entries with the help of tables. These relationships can usually be expressed using values and not pointers.
It defines the relationship among different databases and how they are connected. When multiple databases are connected, it creates flexibility and can be used within a software app as needed.
Each relation in an RDBMS is given a “Name” that will be unique. In each relation, rows and columns represent attributes, and rows are Tuples. Other RDBMS components include RDBMS table, tuple, column, domain, schema and RDBMS constraints.
Name => Attriutes => Tuples
It is a data organization process where data is organized in such a way that it can minimize redundancy. It divides the database into multiple tables and defines logical relationships among them.
Learn SQL Server in the Following Easiest Ways. For example,
Enroll in our SQL DBA training if you wish to become an expert in SQL DBA and work in this industry.
SQL Server Training & Certification

Each has its objectives and purpose. So, you must understand them individually before implementing them with the database. The following are the different normalization types:
1NF , 2NF, 3NF, 4NF, 5NF, BCNF, ONF, DKNF
Yes, I know about the SPs and worked on them during my training. An SP is a group of SQL statements that can be used together to act. It accepts input parameters to be used with different scenarios. SPs are considered an added advantage to ensure a database's integrity.
E-R model stands for entity-relationship model, which explains closely related things in a particular knowledge domain. A fundamental ER model comprises of different entity types and mentions the relationships which could exist among the entities.
It consists of entities and relational objects. Entities can be understood by the collection of attributes in the database.
In RDBMS, data can be abstracted at three different levels. They are given below -.
Physical Level -> Logical Level -> View 1, View 2 & View 3
The physical level is available at the bottom, giving you a detailed idea of the data storage. The Logical level at the next stage finds the logic among data tables and how to group similar data for easy access. At the top, there is a view level that gives information about the complete database and various views of a database.
It is a stored procedure that acts as soon as some event occurs. The programmers do not call events but are invoked automatically as soon as edits are made systematically.
Check out how to create stored procedure & trigger in SQL server. Further, obtaining SQL Training from JanBask Training will provide you access to various work prospects in database management and administration.
A “view” is a subset of a database used to retrieve, delete, or combine the data. As soon as you edit a view, the original data also changes in the table. Find out the difference between tables vs. views in SQL by clicking here.
For creating pointers to the data, SQL server indexes are used. They help in finding rows in a table quickly. Indexes can be defined for multiple columns together with a different name. Users cannot see or access them but helps improve the database performance. For small tables, impacts can be negligible. In the case of complex data tables, the impact of indices is clearly visible.
Yes, there are two methods for index storage in RDBMS. These are given below.
Clustered indexes can give information about the physical storage of the data and non-clustered indexes will give you an idea of logical ordering. Read an all-inclusive guide on the difference between clustered vs non-clustered indexes.
It minimizes redundancy, and integrity can be maintained. It maintains data consistency and allows data sharing with other databases. It follows a set of rules to satisfy storage standards and maintains security.
A buffer manager in database management system is responsible for allocating buffer space in the main memory in order to store temporary data. It transfers the data from third-party storage devices to the memory and puts some data into the cache for easy access.
The buffer manager transfers the block address when a user requests specific data and the data block is available in the table buffer in the primary memory.
A key is a constraint added to a database to restrict data access requirements. These are important for any database to maintain maximum data integrity.
If you are heading for the next MySql interview, check out our MySql interview questions and Answers.
Different types of keys can be applied to databases as needed. Here we have listed the names of popular ones that are used frequently.

One of the most common key that could be applied to almost all databases is called a Primary Key and there is only one Primary key in one table. Primary key is an unique identifier like driver license number, or phone no. together with area code, etc. A RDBMS should have just one primary key.
When you want to use multiple columns as a primary key, then it is called a Candidate Key. Here’s a comprehensive guide on what is SQL candidate key. In a table a composite key is a candidate key which contains 2 or more attributes, i.e., columns that simultaneously identifies a table row or an entity’s occurrence.
On the contrary, a compound key is a composite key for which every attribute that forms a key is a foreign key distinctly.
When you’re using a primary key from any other table, then it is called a Foreign key, and it is used to maintain referential Integrity. A foreign key is a column or a set of columns utilized to develop a link between the data in 2 database tables to monitor the data that could be saved in a foreign key database.
The following are the drawbacks of the File Processing System:
Refer to our SQL tutorial and get an overview of SQL Server, Microsoft's relational database platform. Learn how to connect to an SQL Server database and perform basic operations such as creating tables, indexes, and stored procedures.
Database integrity is determined by two rules.
The number of tuples in a table at any time is an extension. This is time sensitive. Intention is a constant value that specifies the table's name, structure, and restrictions.
It is a prototype, and its goal was to show that a Relational System can be built that can be used in a real-world setting to address real-world issues, with a performance at least equivalent to that of existing systems.
It has two subsystems. They are
Physical Data Independence defines that Physical data changes should not influence logical data. Whereas logical data independence defines that modifications at the logical level should have an impact on the view level.
Test your knowledge of SQL by taking our SQL Quiz and grab the best opportunity for your career.
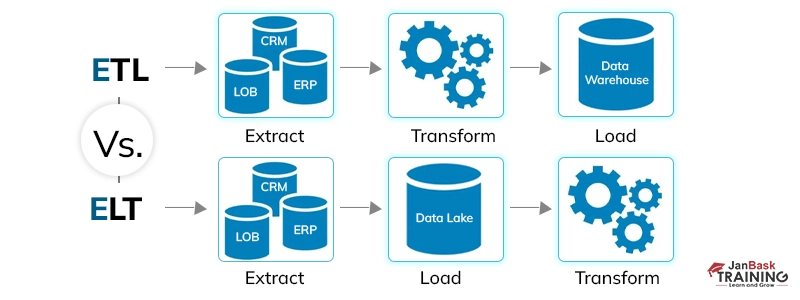
Data is processed by ETL on a separate server, whereas ELT processes data within the data warehouse. Raw data is not moved into the data warehouse via ETL; instead, raw data is sent directly to the data warehouse using ELT.
The foundation of this concept is a collection of objects. Within an object, values are stored in instance variables. A collection of code that operates on an object is also known as an object. Certain sections of code are referred to as methods.
Are you preparing for your upcoming database interview questions? Check out our top DBMS interview questions and answers for freshers and experienced.
An entity type is a group of things with similar attributes. Whereas, an entity set is a collection of all entities in the database that belong to a specific entity type.
The degree of a relation is defined as the no of occurrences in 1 entity which is related to no of occurrences in another entity. The following are the 3 degrees of relationships:
Each record from a group of records can be specified and retrieved using Low Level or Procedural DML. Record-at-a-time retrieval is the name for this method.
The High level or Non-procedural DML can define and retrieve several records in a single DML statement. This type of record retrieval is known as Set-at-a-time or Set-oriented.
Learn how to handle relational databases and gain a thorough understanding of SQL queries by reading our comprehensive guide on what does SQL stands for.
Relational algebra uses procedural query language. It comprises a collection of procedures that accept one or two relations as input and output a new one. Whereas relational calculus is particularly optimized for relational databases.
X Y indicates a functional dependency between two sets of attributes X and Y that are subsets of R, and it constrains the potential tuple that could result in a R relation state r.
The restriction is that if t1[X] = t2[X], then t1[Y] = t2[Y] for any two tuples t1 and t2 in r. This means that the value of the X component of a tuple determines the value of the Y component.
In F, each right-hand side dependency has just one attribute.
We can't replace any dependency X A in F with a dependency Y A and still have a collection of dependencies identical to F. We can't remove any of F's dependencies while maintaining an identical set of dependencies.
The constraint on any relation r of R is described by the multivalued dependence represented by X Y stated on relation schema R, where X and Y are both subsets of R: If two tuples t1 and t2 exist in r with the attributes t1[X] = t2[X], then t3 and t4 should likewise exist in r with the properties t1[X] = t2[X].
It ensures that misleading tuple formation does not occur with relation schemas after decomposition.
If you want to boost your SQL knowledge and advance your career, enrol in our online SQL server training courses & get certified!
It is based on the concept of total functional dependency, in which the dependent attributes are evaluated by the deciding attributes. If removing any attribute A from X causes the dependency to break, it is called a fully functional dependency.
A relation schema R is in BCNF if it is in 3NF and meets the extra restriction that X must be a candidate key for every FD X A.
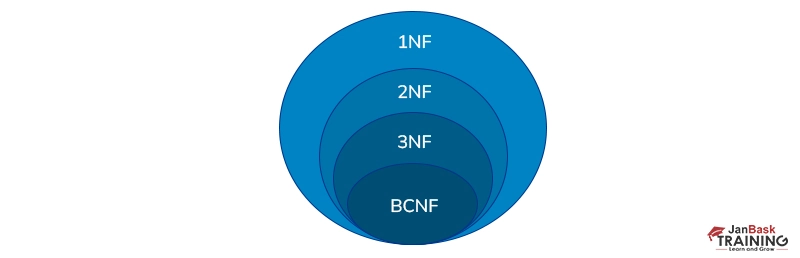
A relational model R is in 3NF if it is in 2NF, and one of the following is true for every FD X A.
For more clarity, learn about database normalization 1NF, 2NF, 3NF, 4NF forms.
The relation is considered to be in DKNF if all constraints and dependencies that should hold on the constraint can be enforced by merely imposing the domain constraint and key constraint on the relation.
A partial key is a set of qualities that may be used to distinguish weak entities belonging to the same owner.
An Alternate Key is a Candidate Key other than the Primary Key. There are different types of SQL keys and their examples and uses. You must know how to use them in database applications.
Query optimization is the process of determining an efficient execution plan for assessing a query with the lowest estimated cost. The aim of query optimization is to identify a plan of execution that minimizes the time needed to process a query.
A checkpoint is a snapshot of the database management system's current state. By employing checkpoints, DBMS can reduce the amount of work required upon restart in the event of many crashes.
It means a database management system should provide a transparent distribution to the user. In other words, a transparent DBMS keeps the data hidden from the user. There are 4 kinds of database transparencies: distribution, translation, performance and DBMS transparency.
The Hierarchical Schema utilizes a tree-like structure to arrange data. Here are the components of a hierarchical model:
Network Schema -
Network Schema is the hierarchical data model in its advanced form. It organizes data using directed graphs rather than a tree structure. A child can have more than one parent in this situation. It makes use of the two data structures known as Records and Sets.
The above figures can differentiate between hierarchical and network schema in DBMS.
For each row of an outer query, these are SQL subqueries that run. Each subquery is done just once for each row in the outer query.
A correlated subquery in a database management system is a subquery that applies to a database column that is not in the “FROM” clause. This database column could be in the Projection clause or inside the WHERE clause. Mostly, correlated sub-queries decline performance.
When the projections of the connected tables are ordered on the join columns, a merge join is used. Hash joins are slower and consume more memory than merge joins. A hash join is used when the projections of the connected tables are not already sorted on the join columns.
Deadlock happens when two transactions wait for a locked resource or while another transaction is held. Deadlocks can be avoided by enabling all transactions to acquire all locks at the same time.
A super key is a single key or a set of keys that helps identify a table record. Super keys can have one or more properties, even if all of them aren't required for the records to be identified. A candidate key is a subset of a Super Key that can identify records in a database using one or more attributes.
When preparing for RDBMS job interviews, one of the most prominent ways to maximize your chances of cracking the interview is anticipating RDBMS questions and answers.
Let’s examine the most frequently asked RDBMS intermediate-level interview questions and answers.
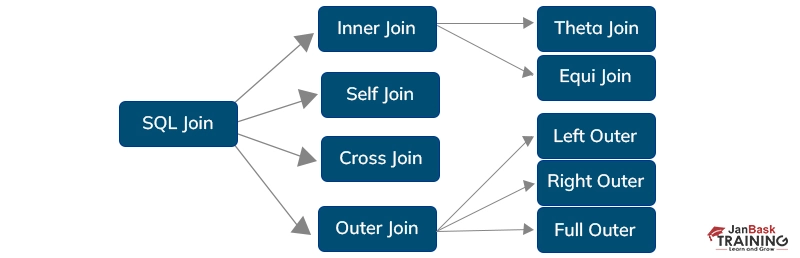
There are different types of SQL joins. The logical operation JOIN is used to get data from many tables. Only when there is a logical link between two tables can it be used? Moreover, the JOIN operator uses data from one table to extract data from another.
Also, gain comprehensive knowledge about SQL Schema and find out how to create, alter and drop a schema in SQL.
Running through the highly awaited RDBMS interview questions is important for cracking your interview and determining your existing preparation. Also, in-depth knowledge of RDBMS opens doors to a lot of job opportunities in top MNCs like Pioneer, Bank of America, IBM, Accenture, and so on. So let’s get started with the next section, where we’ve shared interview questions in RDBMS.
The list of RDBMS interview questions and answers for experienced candidates.
A database is a logical, organized, and consistent collection of data that can be easily accessed, managed, as well as managed. It is designed to let you create, insert and update the data efficiently. Database mostly contains objects and tables, including records and fields.
The abbreviation of Relational Database Management Systems, RDBMS, helps maintain table data records and indices. It is the form of DBMS that utilizes the structure to find and access data concerning the other pieces of data in the database. RDBMS is basically a system that allows you to perform numerous operations like update, insert, delete, manipulate, and administrator a relational database with minimal difficulties.
Here is the list of major advantages of RDBMS:
Here is the list of different languages present in DBMS:
An index is a performance-tuning method that allows the faster retrieval of records from the table. An Index helps in creating an entry for every value. There are three types of SQL server indexes:
Database partitioning is about partitioning tables and indexing them into smaller pieces to maintain and access the data at a better level. So, does table partitioning improve the performance of SQL servers? Yes! This process decreases the price of storing a huge amount of data and improves performance and manageability.
It is a set of information explaining the content and structure of the tables and database objects. This information controls, manipulates, and access the relationship between database elements.
Database Trigger is a set of commands that get executed when an event such as Before Insert, After Insert, On Update, and On Delete of row occurs in a table.
An entity can be taken as an object or thing with independent existence. An entity set is a collection of all entities within a database. Sometimes, if an entity set does not have all the necessary attributes to define key constraints and other logical relationships, then it is termed as a weak entity set. If an entity set has all the necessary attributes to define the primary key and other constraints, it is termed a strong entity set.
A wider range of relational operators that can be applied to a database can be given as: SQL Server operators.
These four properties are considered highly important for any database. These properties make a database easy to access and use. It is possible to share data among tables conveniently. Also, it focuses on data accuracy and avoids redundancy.
DBMS tells about data storage and data creation. RDBMS explains relations among tables and data values. DBMS operations can be used for a specific database, but RDBMS can work on multiple databases together. Find more points of differences in how to differentiate between DBMS and RDBMS.
When designing a database, three types of relationships can be defined. These are:
In the 4NF, it should satisfy the 3NF and not contain two or more views about an entity. In the 5NF, we can reconstruct the information from small pieces of content so that they can be maintained with maximum consistency.
Whenever you are working on big data problems, it should be handled with care. Let us understand the concept with three technical terms Data Ingestion, Transformations, Storage & Analytics.
Data Ingestion uses technologies like Apache Kafka and gracefully streamlines the data across different targets. The second term is transformation, where data is reconstructed and transformed into a meaningful real-time solution.
The last term is Storage & analytics, where No SQL database can be utilized to manage all data issues and works on consistency problems eventually. Once you are done with it, these three features can give you more flexibility, high throughput, and low-latency benefits. In brief, we should replace the traditional batch-oriented approach with modern streaming solutions. If you are a beginner, then you can learn more about No SQL through a comprehensive No SQL tutorial for beginners.
A “view” is defined as a subset of a database or tables stored in it. It can be used to retrieve, delete, or combine the data. Each View can be taken as a separate table and accessed for the application. When changes are made to a specific VIEW, it will not impact others. This is the reason why VIEWS should be learned first to understand the concept of Data Independence in detail.
An entity can be taken as an object or thing with independent existence. An entity set is a collection of all entities within a database. Sometimes, if an entity set does not have all the necessary attributes to define key constraints and other logical relationships, then it is termed a weak entity set. If an entity set has all the necessary attributes to define the primary key and other constraints, it is termed a strong entity set.
There is a major difference between cluster and non-cluster indexes. Clustered indexes make changes in the table and reorder how records are stored there. Nonclustered indexes also make changes in the data stored in the tablet, but it makes a completely different object within the table.
There are three types of user-defined functions.
OLTP is used to manage transaction-based applications; it is used for data entry, data retrieval, and data processing. It makes data management efficient. The purpose of the OLTP system is to serve real-time transactions.
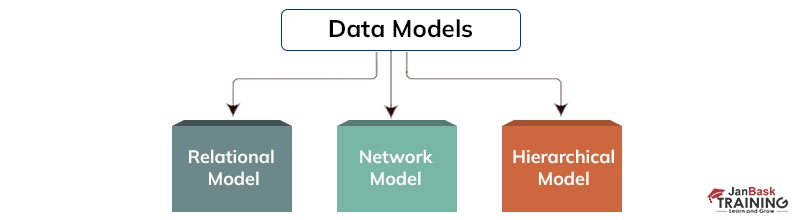
Here is the list of three different data models that are available for various purpose of database systems:
Character manipulation functions effectively extract, edit, format, or modify in some way a character string. Character manipulation functions can be used to manipulate char. Strings. Different types of character manipulation functions are as follows:
CONCAT, SUBSTR, INSTR, LPAd, RPAD, TRIM and REPLACE.
Different types of SQL:
The primary key is the combination of fields that uniquely specify a row. It is a unique key that has an implicit NOT NULL constraint. It means its values cannot be NULL.
The form of the candidate key is referred to as a composite key, a set of columns that uniquely figure out every brown in the tablet.
Also, know why Oracle is the perfect choice for the success of an organization; holding an Oracle Database Certification will help you validate your proficiency & grow your career in this field.
Cardinality is defined as its equivalence class under equinumerosity. Simply, it is described as a fundamental relationship between two entities or objects. There are three types of cardinalities- one-to-one, one-to-many, and many-to-many.
It basically represents the data structure in the form of a tree for external memory that reads and writes large data blocks. It is generally used in databases and file systems where all the insertions, deletions, sorting, etc., are done in logarithmic time.
The work of a DML compiler is to convert the DML statements into a query language that the query evaluation engineer can understand and process. The DML Compiler is needed since the DML is a family of syntax elements that are quite similar to the other programming language that needs compilation. That is why compiling the code in a language the query evaluation engine can understand is important.
Online transaction processing is referred to as OLTP, whereas online analytical processing is called OLAP. OLTP stands for online database modification, while OLAP stands for online database query response.
Q83). What is the use of the NVL() function?
Null values can be replaced with default values using the NVL function. If the first parameter is null, the function returns the second parameter's value. If the first parameter is anything other than null, it is ignored. This function is only accessible in Oracle; SQL and MySQL are not supported.
Check out our top SQL server interview questions and answers to prepare well for your upcoming SQL developer interviews.
Here are the differences between DENSE_RANK vs RANK functions in SQL.
The rank of each row within your sorted partition is determined by the RANK() function in the result set. The DENSE RANK() method assigns a unique rank to each row inside a partition based on the provided column value, with no gaps.
NoSQL databases are designed for certain data models, such as graphs, documents, key-pairs, and wide-column tables. Unlike relational databases, they feature flexible schemas. NoSQL databases are popular because of their ease of use, functionality, and scalability. Unlike SQL databases, they can be expanded horizontally across hundreds or thousands of servers.
Did Al set to grow in SQL? To help you navigate through the journey successfully, here is a guide on How to Become a SQL Professional.
Concurrency control is a database management system process that ensures that concurrent activities do not clash.
Locks are commonly used to ensure that only one user/session can modify a certain piece of data.
There are different types of database locks:
Q88). What do you understand by Data Warehousing?
Data Warehouse is the process of gathering data from several sources (extracting, converting, and loading) and storing it in a single database. The data warehouse can be considered a central repository where data flows from transactional systems and other relational databases.
Lock escalation occurs when a system combines numerous locks into a single higher-level lock, usually to free up resources taken up by many fine-grained locks.
Lock contention arises when numerous operations request an exclusive lock on the same table. Operations must wait in a queue in this situation. If you have ongoing lock contention, you must divide those data blocks further so multiple processes can gain exclusive lock simultaneously.
Hashing is a search method. A method of mapping keys to values. Hash functions take a string of characters and turn it into a fixed-length value that may be used as an index to find the original element.
Advantages of hashing:
The Write Ahead Log is a database system approach for maintaining the atomicity and durability of writes. The WAL's main principle is that before we make any actual changes to the database state, we must first log the whole set of activities we want to be atomic and durable for storage.
A table or column may be given an ALIAS name. Use this alias name in the WHERE clause to identify the table or column. Aliases are put to use in order to assign a table, or a column, a temporary name. They’re usually used for making column names more eBay to read.
Alias exists only for till the duration of that SQL query.
To assess mathematical calculations and return single values, we employ aggregate functions. From a table's columns, one can compute this. Based on the input value, scalar functions return a single value.
Phantom deadlock detection refers to the situation when a deadlock does not actually exist but is still detected by deadlock detection techniques as a result of a delay in the propagation of local information.
The inconsistent state is before the checkpoint, which is the point at which all the logs are permanently recorded on the storage drive. The system can restart from the checkpoint in the event of crashes, saving time and effort.
Database partitioning, or data partitioning, applies to the process of breaking the data present in the application’s table into distinct partitions. You can easily store, manage and access these data partitions independently.
In order to manage and access the data at a finer level, database partitioning involves dividing tables and indexes into smaller sections. Here‘s a guide on how to order and partition by multiple columns.
A stored procedure is a group of pre-compiled SQL queries that, when run, represent a program that accepts input, processes it, and outputs the results.
In other words, a stored procedure is a group of SQL statements with allocated name, that are saved in a RDBMS as a set, so that it could be recycled and shared using several programs.
The data can be recovered using the COMMIT and ROLLBACK statements after running the "DELETE" action.
Following the completion of the "TRUNCATE" operation, the statements "COMMIT" and "ROLLBACK" cannot be used to recover the deleted data.
Use the' DROP' command to remove a table or key, such as the primary key or foreign key. Find more points of difference between DELETE vs TRUNCATE SQL here.
A software testing technique called "black box testing" involves testing the functionality of software programs without being aware of the internal code structure, implementation specifics, or internal paths. Black Box Testing is a sort of software testing that is only motivated by software requirements and specifications and focuses on the input and output of software applications. An alternative term for it is behavioral testing.
Relational databases interview questions frequently include Oracle because it is the most widely used RDBMS. Its fully scalable relational database architecture accounts for its popularity. Oracle database products provide customers with versions that are both high-performing and economical.
The Oracle database provides a built-in network component that enables network communications. As a result, it has become the preferred option for leading international corporations that manage and process data across wide and local area networks.
A stored process that continuously invokes itself until it encounters a boundary condition Programmers can reuse the same code multiple times thanks to this recursive function or process.
The following is a list of collation sensitivity variations.
Local variables are those that can be utilized or already exist within a function. They cannot be referred to or used since the other functions are unaware of them. Every time that function is invoked, variables can be created.
The variables that can be used or are present throughout the entire program are known as global variables. No two variables that have been declared globally may be utilized in functions. When that function is called repeatedly, global variables cannot be generated.
SQL constraints are used to limit the table's data type options. It can be supplied when the table statement is being created or modified. The list of restrictions includes UNIQUE PRIMARY KEY, FOREIGN KEY, NOT NULL CHECK BY DEFAULT
The view is a fictitious table kept active so that users can view their data even if it doesn't exist.
1NF is known as the First Normal Form.
The domain of an attribute should only have atomic values in this kind of normalization, which is the simplest. The purpose of this is to eliminate any duplicate columns from the table.
This is a crucial RDBMS question and answer.
This is used in conjunction with SQL queries to retrieve specified data based on user requirements and SQL-defined constraints. This is particularly useful for selecting specific records from the entire set of records. Find more information about SQL having clause functions to learn more about SQL clauses.
Following are some of the uses of DBMS:
A few examples of RDBMS include - Oracle, Microsoft SQLServer, MySQL, and PostgreSQL. RDBMS consists of numerous components like - tables, records, attributes, instances, schemas, keys, etc.
In a relational database management system, a buffer manager enables relational tasks, heap files, access methods to read/write, allocate and de-allocate pages, etc. These tasks are performed on disc pages by fundamental database class objects, which the buffer manager appeals to.
Understanding the dissimilarities between NULL and other values, like zero or fields with spaces. In a database, a NULL value is in a field containing no values. At the time of constructing a record, a field with a NULL value shows that it is empty.
Learn SQL Server in the Easiest Way

There are 3 levels of data abstraction:
This is one of the most commonly asked RDBMS important questions.
The e-r model is dependent on the real world that contains fundamental objects referred to a entities and of the relationship between them. Entities are explained in a table by using a group of attributes.
Check Out Other Data Management Courses Offered by JanBask Training:
|
Course Title |
Details |
|
Microsoft BI |
|
|
Data Analytics |
|
|
Oracle Database Admin |
|
|
Big Data Hadoop Master |
These Oracle RDBMS interview questions are designed as per the protocol of Oracle Inc.
The blog gives you a sound idea of RDBMS interview questions and answers that you may encounter in your next interview. The discussion during interview questions on RDBMS always starts with basics like RDBMS, Normalization, Triggers, Views, etc. After this, the interviewer will check your practical knowledge through different examples. So, the blog is enough to practice theoretical RDBMS concepts. To learn the practical aspects of RDBMS and how it is used by Companies, join our online SQL server training program to master the concepts of databases from scratch! At JanBask Training, and start exploring the world-class RDBMS systems now.
Ans:- DBMS stands for Database Management System, and RDBMS stands for Relational Database Management System. RDBMS stores data in tables, whereas DBMS stores data as a file. Make sure to get it right in your interview questions on dbms.
Ans:- SQL is a standard database language, i.e., Structured Query Language in RDBMS which is used to create, update, and retrieve data. These questions are a must when it comes to dbms viva questions. One must be prepared for dbms viva questions and answers.
Ans: The following are the types of DBMS:
These are some of the common rdbms interview questions. One can opt for a data scientist course online if they see a potential career in this field.
Ans:- An RDBMS comprises several components like - tables, records, attributes, instances, schemas, keys, etc., which create a relational database. This is quite a common dbms viva question. Learn all about rdbms full form in computer and the purpose of database systems via data scientist training.
Ans:- RDBMS offers 4 major functions as follows −
Ans:- A few examples of RDBMS are- Oracle, Microsoft SQLServer, MySQL, and PostgreSQL.
Ans:- The major objective of our online SQL server training is to offer an SQL online course that provides the experience same as offline classrooms and saves students time traveling to the physical classes, including their finances, energy & time. Learn in depth about sql training by joining a data science certification online.
Ans:- Following are the important skills you’ll learn through our comprehensive data management courses.
Q9. What All Topics Will Be Covered in the Beginner’s Level Online SQL Server Training?
Ans:- Our online SQL server training covers topics from the basics of the SQL discipline to the advanced level. The instructors will teach the following theoretical SQL concepts at the beginner level.
SQL Server, DDL, DML
Ans:- To present you with a quick roadmap of our online SQL server training program, we do provide a free demo class. The goal of this class is to make you familiar with everything that we’ll cover in our course. You can even opt for a data scientist course online.

SQL Server MERGE Statement: Question and Answer
 Jul 11, 2023
Jul 11, 2023  4k
4k
Top SSRS Interview Questions And Answers
Jul 30, 2024 3.8k

Mastering SQL Server Security: Question and Answer
Aug 09, 2023 3.4k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment








