
Does table partitioning improve the performance of SQL Server?
I have just been involved in a project on which I will have to develop a data migration process and a web interface that uses an already existing SQL Server DB. This DB was developed by another person several years ago, it has around 100 GB of data and it is increasing every 10 minutes (it stores 10 min data from several units -> 144 records per day per device). Several tables have around 10 milion rows. The point is that I think the main tables have been designed in a way that is not the most efficient or appropriate for the kind of queries that will be usually executed. Now I need to prove if what I say is better than what it is already implemented. The DB is extensive in number of tables, but the structure can be simplified by the following diagram:
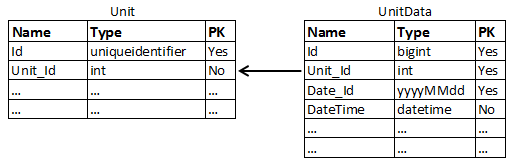
The Date_Id field is generated automatically by a function using the DateTime field. There are two indexes in both tables. The cluster index for each table contains the PK fields in the same order. The second index for the Unit table contains only the Unit_Id field, while the second index in UnitData contains the Unit_Id and DateTime fields in this order.
However, I think the design should be this one:

In this case only a clustered index for the PK fields will be needed. For this DB design the usual query would be something like:
SELECT ud.* FROM Unit u, UnitData ud WHERE u.Unit_Id = ud.Unit_Id and ud.DateTime >= 'dd-MM-yyyy' ORDER BY ud.Unit_Id, ud.DateTime
Now comes the thing that I really don't understand: I've been told that the only reason for having a Date_Id column is to use it as a partitioning column for this table. I've asked about the real necessity of having this table partitioned and the answer was "to run queries more efficiently when wanting daily or monthly data". I didn't know to much about partitioning before this, so I checked these links:
http://msdn.microsoft.com/en-us/library/ms190787.aspx
How Does Table Partitioning Help?
Improve performance by partitioning
Considering that the ideal query would be filtering by device and datetime, the questions are: What do you think would be the most efficient and ideal query for the first DB design (with partitioning)? Do you really think that the most efficient query against the first DB design is better than the second one (the one I wrote above)? If the previous one was affirmative, do you really think the improvement is worth having two extra fields (Id and Date-Id) and an extra index?
Thank you very much!!
SQL Server Partitioning is the database process where very large tables are divided into multiple smaller parts. The main goal of partitioning is to aid in the maintenance of large tables and to reduce the overall response time to read and load data for particular SQL operations. Partitioning is a SQL Server feature often implemented to alleviate challenges related to manageability, maintenance tasks, or locking and blocking. In addition, a by-product of partitioning can be improved query performance. Using partitioning is only going to help your query performance if the partitioning scheme is built to serve your specific queries. You're going to have to review your query patterns and see how they are accessing the table in order to identify the best approach. The reason for this is you can only partition on a single column (the partitioning key) and this is what will be used for partition elimination.
There are two factors that affect if partition elimination can occur and how well it will perform:
Partition Key -Partitioning can only occur on a single column and your query must include that column. For example, if your table is partitioned on date and your query uses that date column, then partition elimination should occur. However, if you don’t include the partition key within the query predicate, the engine can not perform elimination. Granularity - If your partitions are too big, you won’t gain any benefit from elimination because it will still pull back more data than it needs to. However, make it too small and it becomes difficult to manage.
make it too small and it becomes difficult to manage.
In many ways, partitioning is just like using any other index, with some added benefits. However, you don’t realize those benefits unless you're dealing with incredibly large tables. Personally, I don't even consider partitioning until my table is over 250 GB in size. Most of the time, well defined indexing will cover many of the use cases on tables smaller than that. Based on your description, you're not seeing huge data growth, so it could be that a properly indexed table will perform just fine for your table. I would strongly recommend that you review whether partitioning is actually necessary to solve your issues. One would usually partition a very large table for the purpose of:
- Distributing data between different types of disk so that more “active” data can be placed on faster, more expensive storage while less active data is placed on cheaper, slower storage. This is mostly a cost savings measure.
- Assisting in index maintenance for extremely large tables. Since you can rebuild partitions individually, this can assist in keeping indexes properly maintained with minimal impact.
- Leveraging partitioning for improved archival process. See sliding windows.