Tired of piecing together information about SQL? This guide answers all your questions:
What does SQL stand for? It stands for Structured Query Language and is a powerful tool used to manage and analyze data in relational databases.
Why is it important? SQL is a standardized language, making it versatile and compatible with various database systems. Its efficiency allows for smooth handling of large data volumes, crucial for modern businesses.
Considering a career in SQL? Enroll in a professional online SQL server training program to master SQL from beginner to advanced levels.
What is SQL Full Form?
SQL, which stands for Structured Query Language, is a powerful and widely-used programming language specifically designed for relational databases. Initially, some developers and researchers questioned its versatility beyond production databases. However, SQL's efficiency and ease of use have proven them wrong. Today, SQL is a cornerstone of data management, offering exceptional runtime performance across various applications.
Major Elements of SQL Programming Language
SQL, or Structured Query Language, is a powerful language for working with relational databases. It uses statements that start with keywords (like JOIN or VIEW) and end with semicolons. Let's explore some key elements that make SQL tick:
Keywords: These are the workhorses of SQL, instructing the database on what actions to take (e.g., SELECT, UPDATE, DELETE).
Search Conditions: Imagine a filter for your data. Search conditions allow you to pick specific rows based on criteria, like using IF statements to check if a condition holds true for a row.
Expressions: Think of these as formulas you build with symbols and operators (like +, -, *) to perform calculations on your data.
Identifiers: These are labels assigned to database objects like tables, columns, or views, making them easy to reference.
Data Types: This defines the kind of information a column can hold (e.g., text, numbers, dates).
Nulls: A way to represent missing or unknown values within a column.
Comments: Just like notes in your code, comments explain specific sections of your SQL statements, improving readability.
Mastering these elements is essential for anyone aspiring to work with SQL. In the next section, we'll delve into various learning opportunities to help you conquer the world of SQL!
Why is SQL So Popular?
Structured Query Language (SQL) isn't just a database language; it's a powerhouse tool that fuels many industries. Here's how SQL takes center stage:
Data Management Master: SQL excels at organizing and storing vast amounts of data. Users can effortlessly create, modify, and query databases, making it an indispensable component of data management.
Unveiling Data Insights: SQL empowers users to extract valuable knowledge from data troves. It facilitates quick and easy analysis, making it a cornerstone for data analysts and scientists.
Business Intelligence Guru: Companies leverage SQL in business intelligence systems to make data-driven decisions. By analyzing massive datasets, businesses can identify trends, predict outcomes, and gain a deeper understanding of their operations.
Web Development Hero: Dynamic websites rely on SQL for data management. Web developers leverage SQL to create web pages that pull information from databases in real-time, keeping websites fresh and interactive.
The Ultimate Connector: SQL seamlessly integrates with various technologies. This versatility allows for connecting databases, automating data transfers, and fostering a smooth flow of information across different systems.
What Are The Key Features of SQL?
As was previously mentioned, SQL enables command-based communication with databases. Here are a few characteristics of the SQL Database:
Users can extract data from the relational database using SQL
Users can make databases and tables
It permits changing databases and tables by inserting, removing, and moving them around
Security is offered, and permissions can be configured
It enables new data handling techniques
These are the key features of SQL, perfectly explaining its significance, SQL definition and what SQL stands for.
What is a Database?
A well-organized group of data that is kept in an electronic format is called a database. An electronic system that makes it simple for users to access, modify and update data is known as a SQL database. Master the fundamentals of SQL programming with our Data Management Courses. Stay up-to-date with the top SQL skills offered by industry professionals today!
What is a Database Management System?
Consider a school SQL database that contains information about current students as well as students who have previously studied in the Student Details table. Similar information may be found there regarding the faculty, management, staff, and many more groups, depending on the needs of the school. We need a database management system to manage the vast volumes of data.
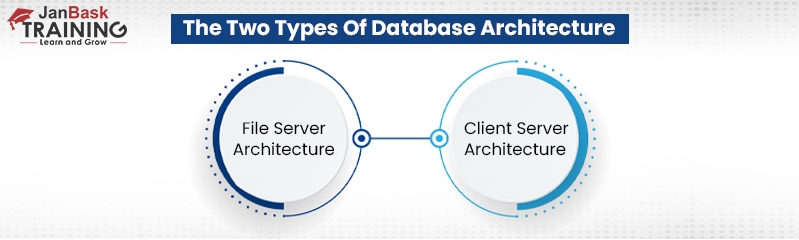
What are the Different Types of Database Architecture?
1). Client-Server Architecture
Any application that consumes the data is a client in a client-server architecture, while the database serves as the server. Here is an illustration that shows how this server functions. Think about three client systems or OLE DB components that are simultaneously accessing the database. The systems have accessed the IRCTC website to learn how many trains are traveling from X to Y destinations.
2). File Server Architecture
The local system is where files are located in the file server architecture. It is helpful for network-wide information sharing. This is thought to be the most basic data service available for information exchange over a network. Remote server processors can also access the file server. That’s it on the explanation of different SQL terms and SQL full form or what SQL stands for. In the next section, we will discuss the primary queries of SQL.
Learn More About SQL – A Relational Database
Do you know the reason behind the discovery of SQL? At IBM, there was a scientist who was majorly working on relational model theory and how to publish it. Soon, the IBM team also started supporting the scientist, and there was a programming language called SQL, which was integrated with the Oracle database too. In 1980, SQL became an international trademark and started getting applied everywhere.
Now, Oracle and IBM have both started supporting the development of SQL. Soon, the language got support from customers as well. Initially, it was not easy to hire or train Codasyl programmers or developers, so SQL (SQL full form or SQL stands for Structured Query Language) became a highly attractive option in this situation. In the late 1980s, developers stapled a SQL query processor on the top of Codasyl databases, where they realized that relational databases should be designed from scratch to make them more relational.
Since that time, the inception of relational databases came into existence. This was a purely relational database system where tuples were grouped into relations, and they were consistent with first-order predicate logic too. For real-world relational databases, there are tables, fields, triggers, constraints, primary keys, foreign keys, etc. SQL helps you in playing with the data, where you can filter data and access desired outputs at your fingertips. Further, there is one SQL query processor and the query optimizer to turn SQL declarations into a query plan that can be executed with the database engine. Here, SQL is the sub-language defining schemas, DDL (Data definition language), helps in modifying data, DML (Data Manipulation Language), etc. You could understand the concept closely with SQL declare queries, SELECT statements or relational joins, etc. In the next section, we will focus on the Select statement and how to use the SELECT statement in the SQL.
Find out more about SQL injection and attacks. Go through our guide to learn the basic concepts, SQL syntax, and the most common vulnerabilities and attacks.
How to Use SQL
Generally, an application is programmed in any language such as PHP, Python but the database is not configured to understand these. Databases understand only Sequel. That's why working through SQL is important if you intend to work in web development or app development.
Just like any other programming language, SQL has its own markup that makes it mandatory for a programmer to learn SQL ((SQL full form or SQL stands for Structured Query Language) before they can use it in the right way.
Apart from the markup, another feature of database programming is the table concept. A database may be represented as a number of tables. Each table contains its own number of columns and browns and presents a set of data.
What is a SELECT Statement in SQL?
SELECT statement is an important query after what SQL stands for or SQL full form. The SELECT statement in SQL tells the query optimizer what output could be returned, what should be found in tables, what relations should be followed, or what order should be followed for the return data. The query optimizer can figure out what indexes should be used for an excellent table scan and achieve the maximum query performance unless the particular database supports index hints.
The major part of the relational databases is designed on the judicial usage of indexes. If you want to use an index to perform frequent queries then database performance will slow down under heavy road loads. In case you had too many indexes, then again database performance will get affected due to heavy write and update loads.
Another fact to focus on here is deciding on the unique primary key for each table. The Primary key is a set of columns having unique values and it should not be NULL. The impact of primary keys should be considered in common queries too but how to perform joins when it is used as the foreign key in any other table. Also, you need to check how it will affect the data locality of references.
The case of advanced database tables that are broken down into multiple fields also depends on the value of the primary key either horizontally or vertically. For example, when you want to distribute the particular primary key across volumes then you don't have to use data stamps or consecutive integers as primary keys. The SELECT statement in SQL may start simple but it may create confusion later even for expert SQL programmers too. Here, one simple syntax is given below for your reference.
The syntax seems quite easy and simple. Right? Here, it is asking to select all rows and columns from the customer table. Consider, the customer table has millions of records and each row has a large text field for comments. So, how it will pull down over 10-megabit data every second over the network connection when the row is constrained for an average of 1 kilobyte of data. Perhaps, you must limit the data that can be exchanged over a wire.
For example, you could name a particular row, column, or field that you wanted to extract. You can also filter records for a particular region. In this way, you can make your queries more optimized and they are easy to fetch over a network as well. Also, check out for top 100 clauses like where and order by, etc. that can be clubbed with SELECT query in SQL to optimize the overall database performance.
Every time you are writing a query in SQL ((SQL full form or SQL stands for Structured Query Language), certain rules and regulations should be followed by programmers and developers deeply. There are pre-defined ANSI SQL standards that should be checked by SQL professionals before they start with database programming.
In the next section, we will go through a list of SQL queries you should know when looking for a SQL career and to further explain what SQL stands for or SQL full form. If you want to grow your career as a DBA, check out the Roles and Responsibilities of a SQL Server DBA to gain a complete insight of this domain.
What are Relational Joins in SQL?
Till the time, we were discussing the SELECT syntax for single tables. What to do when you want to join multiple tables together. Here, we need to join clauses to make things easier for you. For this purpose, you need to understand foreign keys and relationships among tables well. It can be explained by a set of examples in DDL with the help of SQL server syntax. With relational joins, understanding relations in SQL are quite simple. For every table, there is one primary key constraint that could be taken as the single field or combination of fields defined by the expression. When you want to connect tables then you need foreign keys too along with primary keys. Consider the example as given below:
The queries can be made longer with the CONSTRAINT keyword where you should give a proper name to the constraint. This is the format that is followed by all database tools. Primary keys are always unique and indexed. At the same time, other fields could be indexed optionally. Further, it is necessary to create indexes for foreign keys too by using the WHERE and ORDER BY clauses.
Further, there are four types of relational joins – INNER, OUTER, LEFT, or RIGHT, etc. The INNER join is taken by default that considers only rows containing matching values in both tables. If you wanted to list persons whether or not they have an order then you should use LEFT join in that case. If you want to join more than two tables then you can use expressions. Fortunately, there are database development tools that could always help you in designing a robust set of SQL queries just by dragging or dropping commands from the schema diagram to a query diagram.
So, now you know SQL full form or what SQL stands for? In today’s time, the database programming language SQL stands for getting popular and accepted widely worldwide. This post takes us back to the Codasyl database space and tells us how SQL came into existence. I hope you must have liked reading this post. To know more about queries that can be performed on database tables then, you should spend more time learning SQL queries from some reputed training providers online. You can also sign up for SQL courses where you will learn more than just what SQL stands for on Janbask Training.
Enrich your knowledge with a 2-minute SQL quiz to test your understanding of SQL and SQL definitions. You can improve your basic knowledge and get ready for the SQL Certification Exam by taking this online test.
What was the scenario before SQL?
When SQL ((SQL full form or SQL stands for Structured Query Language) was not introduced in the market, there were navigational programming interfaces that were typically designed around the network schema called the Codasyl data model.
This data model was responsible for the Cobol programming language and other database extensions too. In the case of Cobol, the records were navigated through sets to express one-to-many relationships. In the case of hierarchical databases, only one record is allowed to be attached to one data set only. In the case of network databases, you can enjoy working with one-to-many and many-to-many relationships.
Earlier, programming was quite boring and time-consuming too. The launch of SQL gives a new boost to database performance, and today skilled SQL professionals are needed everywhere. Almost every database programmer believes that SQL is used for different purposes, it is quite efficient during both execution and runtime. You can play with data as per your terms and conditions. Even memory consumption is very low compared to non-relational databases used in the past.
Master the fundamentals of SQL programming with our Data Management Certification. Stay up-to-date with the top SQL skills offered by industry professionals today!
How To Make a Carer in SQL: SQL Server Training & Certification
SQL is used for or as an easy-to-learn language that is specifically designed to work with the database. The demand for professionals who can handle databases is rapidly increasing. In the present day, every giant brand is working with SQL. This is the reason, the number of Google searches for what SQL stands for or SQL full form is rapidly going high. This language is used in different activities from banking to ticket booking to data sharing, eCommerce, etc. Overall, there is a great career scope available for the SQL developer.
Here’s a quick rundown of the steps, when it comes to learning opportunities in SQL language and making a better understanding of what SQL stands for:
Begin with the Basics - First, learn the basics of SQL syntax and what SQL stands for or SQL full form. There are various online tutorials available for free that can help you get familiar with the language.
Enrollment in a SQL Course - In the next step, you can take a proper SQL language course to build your knowledge and understand what SQL stands for in different ways.
Real-life Experience - Real-life experience is the most effective way to learn anything. To gain expertise in this language also, you need to practice with real data plus a database.
Best Resources to Learn SQL Online - Here are some good resources from where you can learn SQL, including course options, and video tutorials that can take you from beginner to expert professional in SQL.
Querying Databases And SQL Server Operators: This is a quick tutorial to learn about SQL servers. Since it is in video format, you can easily learn through the whole process easily without spending a lot of time. Check it out with a click to know everything about SQL Server.
SQL Server Tutorials For Beginners & Experienced: if you get intrigued by data and are considering exploring it SQL Server tutorial is a perfect option for you to completely understand the SQL definition.
Query Solutions and Techniques for Database Developers: It covers the complete functionality of famous databases like SQL Server, Oracle, and PostgreSQL and helps you to take your SQL skills to the next level.
Also, The data types in SQL Server tables are used to define the data values that are assigned to the columns of a table. Check out our blog on SQL data types for Oracle and their usage in SQL Server tables.
What is The Career Scope after Gaining Skills in Structured Query Language?
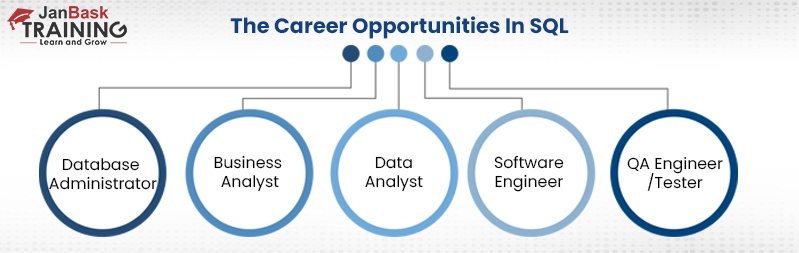
Present-day SQL is one of the most in-demand skills among jobs in data. SQL developer is probably the popular choice. In addition, here are some career options that generally need SQL skills:
Database Administrator: The data administrator is responsible for taking care of data, he ensures that data is stored, organized, and managed correctly to make it easier to retrieve data quickly and accurately. DBAs also oversee a team of developers and also analyze an organization’s data management, input, and security needs.
Business Analyst: A Business Analyst helps businesses to grow and make better processes, products, and solutions through analysis. They generally work to find the required steps to get from the current state of the business to a desired future state.
Data Analyst: Another popular career choice after the SQL program is becoming a Data Analyst and analyzing data. As a data analyst, one has to sort the massive amounts of data and find important business insights from it. Generally, data analysts take help from SQL to access data stores in a database, change it as per their choice and analyze.
Software Engineer: Software engineers are the brains behind computer programs. They make apps that allow people to do specific tasks. Knowing SQL is a fundamental skill to becoming a good Software Engineer. Software engineers have to work with databases either directly or indirectly. Here, having a good knowledge of SQL can be highly beneficial in terms of more payment than their peers.
QA Engineer/Tester: More like a penetration tester, QA engineers work to find, investigate, and report bugs in software. The knowledge of SQL helps them to verify if the databases are working properly.
Start Your Career in SQL
Now that you know SQL stands for Structured Query Language, let's explore its fascinating journey. This post delves back into the era of Codasyl databases and unveils the story behind SQL's rise to prominence.
From Codasyl to SQL: A Shift in Database Management
The world of databases has come a long way from the Codasyl model. SQL emerged as a more user-friendly and standardized language, gaining widespread adoption across the globe.
Ready to Master SQL Queries?
If you're eager to unlock the power of SQL queries, numerous reputable online training providers can equip you with the necessary skills.
Beyond the Basics: Hands-on Training and Real-World Projects
Enrolling in an online SQL training and certification program offers a comprehensive learning experience. You'll not only grasp the fundamentals and query writing, but also gain practical experience through real-world projects, preparing you to ace those SQL interview questions.
FAQs
1. What is a Query in SQL?
In the context of SQL, a query is a formal request for information from a database. It's like asking a question, but the answer comes from the database tables.
2. What Does SQL Stand For?
SQL stands for Structured Query Language. It's a standardized language for interacting with relational databases.
3. How Do You Pronounce SQL?
The standard pronunciation is "ess-cue-ell."
4. Is SQL a Programming Language?
Yes, SQL is a programming language specifically designed for communicating with relational databases.
5. What Can You Do with SQL?
SQL allows you to perform various operations on data in relational databases, including:
Creating, Modifying, and Deleting Data: You can manage the structure and contents of your database tables.
Extracting and Analyzing Data: SQL empowers you to retrieve specific data and perform analysis on it.
Data Management and Retrieval: It's the foundation for efficient data storage, organization, and access.
6. Is SQL Difficult to Learn?
The basics of SQL are relatively easy to grasp, especially if you have some programming experience. However, mastering advanced functionalities takes practice and ongoing learning.
7. What Jobs Can I Get with SQL Skills?
SQL proficiency opens doors to various careers, including:
Business Analyst
Data Scientist
Software Engineer
Database Administrator
Quality Assurance Tester
8. How Long Does it Take to Learn SQL?
It takes roughly two to three weeks to acquire the fundamentals of SQL and start working with databases. To become truly fluent and handle complex tasks, you'll need dedicated practice.
9. Can I Get a Job with Just SQL?
While SQL expertise is valuable, most employers seek well-rounded professionals with additional skills and experience. Combining SQL with other programming languages or data science knowledge strengthens your career prospects.
10. What is the Salary Range for SQL Developers?
SQL developer salaries vary depending on location, experience, certifications, and other factors. In the US, the average annual salary is around $88,180, with potential cash bonuses.
11. What's the Difference Between a Programming Language and SQL?
Traditional programming languages instruct computers to perform actions and solve problems. SQL, on the other hand, focuses specifically on interacting with relational databases for data management purposes.
12. What is a SQL Database?
An SQL database (also called a relational database) stores data in a structured format of tables with rows and columns. Each row represents a data entity, and each column represents a specific data attribute. SQL is the language used to interact with and manage this data.
13. Why is SQL Used?
SQL is the dominant language for interacting with relational databases. It allows you to create, store, retrieve, and manipulate data efficiently.
14. What Applications Use SQL?
Most relational database management systems, including popular options like MySQL and Microsoft Access, are compatible with SQL. This makes SQL a versatile tool for various database-driven applications.
I hope this comprehensive guide clarifies everything you wanted to know about SQL!
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.
I was seeking information related to SQL server, but was not getting satisfying information. Thanks to your blog, it includes basic to advanced level information for beginners as well as professionals. Keep it up!
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
I am still confused about how to SELECT statements in SQL? The answer that you have mentioned is not that satisfying, can you share some more links related to it?
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
The blog is really impressive, it includes all the information that should be included in any SQL article. My friend was also asking me about SQL, I would definitely recommend it to them.
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
As far as I know SQL is more relevant to database handling, is it possible to get the job of database administrator after learning SQL. and one thing i want to add about this post is, it is very helpful for people or SQL learners.

 Jun 06, 2025
Jun 06, 2025  461.1k
461.1k
























 Nov 28, 2019
Nov 28, 2019 7.3k
7.3k

Ali Price
I was seeking information related to SQL server, but was not getting satisfying information. Thanks to your blog, it includes basic to advanced level information for beginners as well as professionals. Keep it up!
JanbaskTraining
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
Eduardo Bennett
I am still confused about how to SELECT statements in SQL? The answer that you have mentioned is not that satisfying, can you share some more links related to it?
JanbaskTraining
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
Cruz Peterson
Overall a good article, I will definitely recommend this to my friends and colleagues. Thanks for the information!!
JanbaskTraining
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
Kairo Gray
The blog is really impressive, it includes all the information that should be included in any SQL article. My friend was also asking me about SQL, I would definitely recommend it to them.
JanbaskTraining
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
Dante Ramirez
As I am going to learn SQL classes, I thought of trying to explore a little bit about it. And this post helped well with that.
JanbaskTraining
Glad you found this useful! For more such insights on your favourite topics, do check out JanBask Training Blogs and keep learning with us!
Hendrix Howard
I have a question, after learning SQL what kind of job roles we can get and what is career growth possibility, what will be the salary package.
JanbaskTraining
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
Derek Ward
I have a question, after learning SQL what kind of job roles we can get and what is career growth possibility, what will be the salary package.
JanbaskTraining
Hello, JanBask Training offers online training to nurture your skills and make you ready for an amazing career run. Please write to us in detail at help@janbasktraining.com. Thanks!
Cristian Torres
I want to know if I do not have a professional degree but learn SQL , what is the possibility of getting a good job.
JanbaskTraining
Thank you so much for your comment, we appreciate your time. Keep coming back for more such informative insights. Cheers :)
Cruz Peterson
As far as I know SQL is more relevant to database handling, is it possible to get the job of database administrator after learning SQL. and one thing i want to add about this post is, it is very helpful for people or SQL learners.
JanbaskTraining
Thank you so much for your comment, we appreciate your time. Keep coming back for more such informative insights. Cheers :)
Kairo Gray
Looking for tutorials based on SQL coding, is there any coding based tutorial you have published or a community relevant to that.
JanbaskTraining
Thank you so much for your comment, we appreciate your time. Keep coming back for more such informative insights. Cheers :)