
 May 01, 2019
May 01, 2019  765.1k
765.1k

26
JunMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- SQL Server Blogs -
Traditionally, applications were using a standalone environment where a centralized server used to respond to multiple users and locations. The common issues reported by this centralized approach included performance issues, availability issues, and maintenance issues. To overcome all these problems, the concept of replication is used.
Replication allows using multiple copies of data at different locations together. Log shipping and mirroring usually result in database redundancy whereas replication allows maintaining selected parts of the database or a set of needed objects at different locations. Modifications made at different locations are synchronized later to the main server. In this way, it maintains high availability features when needed.
Read: Top 97 Data Modeling Interview Questions and How To Answer Them
According to experts, replication is a set of technologies to copy and distribute data and database objects from one database to another and maintain synchronization among databases to regulate the consistency. Like other replication techniques, SQL server replication does not distribute the entire database, but it distributes selected parts of the database only like tables or views, etc. SQL replication is quite useful and you must know how to do it right.
Here in this blog, we shall discuss the basics of SQL Server Replication.
Learn SQL Server in the Easiest Way

Here are some advantages of using SQL Server Replication-
In SQL Server 2005, replication was performed to introduce the custom business logic into the synchronization process. It allows web synchronization options to replicate data over the HTTP. In SQL Server 2005, replication had to be stopped to perform some actions like adding nodes, performing schema changes, etc. The SQL Server 2008 allows performing all these actions online. In SQL Server 2012, replication features were stronger and improved over time.
Read: What Is SQL Queries? List Of All SQL Queries With Examples

SQL Server Replication is based on the “Publish & Subscribe” metaphor. Let us discuss each SQL entity or SQL component in detail below.

An article is the basic unit of SQL Server consisting of tables, views, and stored procedures. With a filter option, the article in the SQL replication process can be scaled either vertically or horizontally. It is possible to create multiple articles on the same object with certain limitations or restrictions.
With the help of the New Publication Wizard, you can navigate the properties of an article and set permissions when needed. You can set permissions at the time of publication as well, and these are read-only permissions only.
SELECT
Pub.[publication] [PublicationName]
,Art.[publisher_db] [DatabaseName]
,Art.[article] [Article Name]
,Art.[source_owner] [Schema]
,Art.[source_object] [Object]
FROM
[distribution].[dbo].[MSarticles] Art
INNER JOIN [distribution].[dbo].[MSpublications] Pub
ON Art.[publication_id] = Pub.[publication_id]
ORDER BY
Pub.[publication], Art.[article]Once the article has been created successfully and you want to change some properties, then a new replication snapshot should be generated. If the article has one or more subscriptions, then all of them should be reinitialized independently. To list all the articles in SQL Server publication, you can use the following commands.
Read: How to Use Alter, Drop, Rename, Aggregate Function in SQL Server?
A publication is the logical collection of articles within a database. It allows us to define and configure articles’ properties at a higher level so that they can be inherited from to other articles in the group. An article cannot be distributed independently, but it needs publication.
EXEC sp_helppublication;
This is the source database where SQL replication starts and makes data available for the replication. Publishers define what they publish through a publication. A publisher can have one or more publications where each publisher defines a data propagation mechanism by creating multiple replications stored procedures together.
USE Distribution
GO
select * from MSpublications
A distributor is a storehouse for replication data associated with one or more publishers. In a few cases, it acts as the publisher and distributor both. In the case of SQL Server replication, it can be termed as the local distributor. If it is distributed on a different server, then it is termed as the remote distributor. Each publisher is associated with a distribution database and a distributor.
SQL Server Training & Certification

The distribution database identifies and stores the SQL replication status data, publication metadata and acts as a queue sometimes to move the data from Publisher to Subscribers. Based on the replication model, the distributor is responsible for notifying Subscriber that the user has subscribed to a publication and article properties are changed. Also, distribution databases help to maintain data integrity. Each distributor should have a distribution database consisting of article details, replication metadata, and the data. One distributor can have multiple distribution databases. However, all publications defined on a single Publisher should use the same distribution database. Here is the command to check whether a database is a distributor or not.
SELECT @@ServerName Servername, case when is_distributor=1 then 'Yes' else 'No' end status FROM sys.servers WHERE name='repl_distributor' AND data_source=@@servername;
Here is the command to check either a distribution database is installed or not.
SELECT name FROM sys.databases WHERE is_distributor = 1
Here is the command to check either a publisher is using Distributor or not.
EXEC sp_get_distributor
This is the destination database where replication ends. A subscriber can subscribe to multiple publications from multiple publishers. A subscriber can send back the data to the publisher and publish data to other subscribers based on the replication model and the design.
EXEC sp_helpsubscriberinfo;
| Pull Subscriptions | Push Subscriptions |
| This subscription is created at the Subscriber server. | This subscription is created at the Publisher server. |
| In this subscription, the subscriber initiates the replication instead of a publisher. | In this subscription, the publisher is responsible for updating all changes to the subscriber. |
Take our Live Training on SQL Server and master the concepts of SQL with ease!
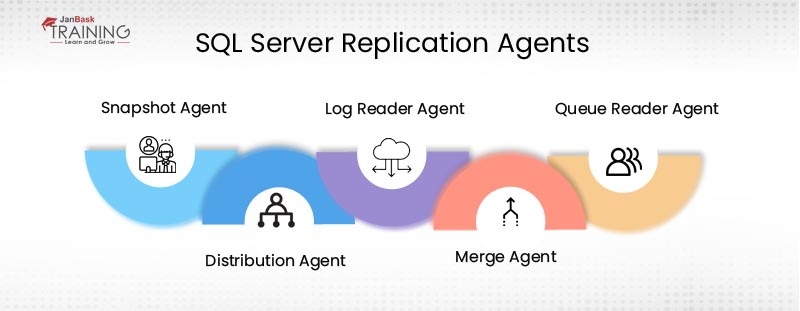
The replication process works in the background with the help of jobs, and these jobs are termed as agents as well. The information of agents is generally present in the distribution database. The replication agents in SQL Server are divided into five major categories:
Read: View vs Table In SQL: A Comprehensive Insight You Have To Know
Read: How to Use Like Operator in SQL Server?
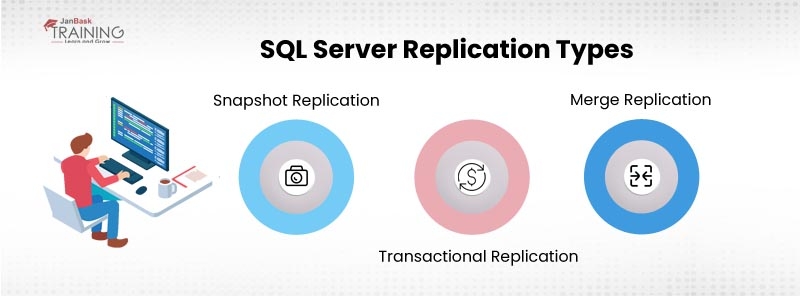
Here is a list of the SQL Server Replication types-
For example, if there is one product Company that is changing the price of its whole products frequently once or twice a year, replicating the complete snapshot of data, in this case, is highly recommended.

How does snapshot replication work?
In simple words, snapshot replication behaves the same way as the name suggests. The publisher simply takes the snapshot of the entire database and shares it with subscribers change. This is basically a resource-intensive process and doesn’t use by administrators frequently for databases that frequently. It is mostly used in two scenarios:
Read: What is a Candidate Key in SQL? Understanding the Difference Between Primary and Candidate Keys
SQL Server Transactional replication offers a more flexible solution for databases that change frequently. Here, the replication agent monitors the publisher for database changes and transmit those changes to the subscribers. You can schedule these transmissions in a transactional replication either periodically or regularly.
This replication allows publishers and subscribers to make changes to the database individually. It is possible to work together for both entities without any network connection. When they have connected again, the merge replication agent checks both entities for changes and modifies the database accordingly.
If there are some conflicts in changes, then the agent uses one predefined conflict resolution algorithm to check on the appropriate data. This type of replication is mainly used by laptop users and others who are not continually connected to the publisher.
Read: What is Primary Key in SQL? How to Add, Remove, Or Set Primary Key
Each of the replication types has its own benefits and needs. They are suitable for different database scenarios. You can choose any one of them based on your replication needs. It is clear at this point that the SQL Server replication process offers database administrator a powerful tool for managing or scaling databases in an enterprise environment.
Think for a while if there are five active subscribers who are allowed to make changes to database copies and send the same to the publisher. Subscriber A makes some changes and forwards the same to the publisher. Publisher will update changes to the database, and same changes are reflected by other subscribers as well B, C, D, and E. In the meantime, other subscribers are also making their own changes and sending transactions to the publisher.
For a complex or bust database application, it will create traffic immediately even if your network links are up to the date. You are exponentially increasing the workload on each SQL server, and each server system must keep changes and maintain the same on other servers too. At the same time, the publisher is also consolidating changes.
SQL Server Training & Certification

Why don’t you take a free demo of our online SQL Server Training to assess the high level of remote training that we provide? Sign up here and book your spot!
Replication is a magical process, but it does not work well everywhere. You have to figure out scenarios where SQL server replication can deliver the best performance.
Once you have read this blog thoroughly, you will understand the much needed basics of SQL Server Replication.
When it is integrated with more powerful cloud platforms like Microsoft Azure or AWS, SQL Server Replication becomes stronger and designs the best business solutions. If you are still confused, join our SQL certification program and understand practical aspects of the database and how to use them for tough business scenarios.
Read: Top SQL Commands to Improve Your Database Skills
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Top 75 SSAS Interview Questions and Answers For Beginners & Experts
 906.4k
906.4k
What Does It Take To Become a Successful SQL DBA Expert?
20k
A Complete Overview Of SQL Not Equal Operator with Examples
10.9k
SQL Certification Guide: Become a Certified SQL Expert with the Right Certification
8.2k
Online SQL Queries for Practice Questions with Answers
543.4k
Receive Latest Materials and Offers on SQL Server Course
Interviews












 Jul 22, 2025
Jul 22, 2025 906.4k
906.4k
