 Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Deep Learning is one of the emerging fields of information technology. It comprises a combination of techniques that allow the machines for prediction of outputs which are derived from a layered set of inputs. Deep learning is increasingly accepted by companies around the world.
Deep learning has moved up the hierarchy of the data science world by way of astonishing innovations and path-breaking discoveries. A few examples in the field are speech recognition, finding various patterns and trends in datasets, character text generation, recognition of images, classification of objects in photographs, etc. The best part of the whole story is that this is just the beginning.
Any person who is skilled in software and data skills can easily find jobs in the niche. But all good things never came easy and nor is the job in this area. However, cracking the interview requires sound preparation of the most commonly asked questions about Deep Learning. Remember, every interview is different and requires company-specific preparation in addition to the basic know-how of the interview questions. So, let us get started with all the exciting advanced deep learning interview questions.
Deep learning is basically a paradigm of machine learning, which is highly promising in recent years. It is primarily because deep learning shares an immense analogy with the human brain functioning. It is evident that the human brain is superior and is considered to be highly dynamic, and it is definitely the most efficient model of learning which has taken shape. However, deep learning is made special by its ability to fetch meaningful information from huge datasets.
It has been seen that deep learning models get better with the increasing amount of data. Although deep learning has been present for many years, it is only recently that breakthroughs have occurred, due to increase in data through various sources and also a steep growth recorded in the number of hardware resources that are needed for running these models.
Aspiring to become a Deep Learning professional? Follow this link!
Deep learning is the latest buzzword in the field of data science. It definitely has many practical applications in the recent past ranging from the system of movie recommendations to the self-driving cars of Google. It will bring about a revolution in most industries. It will be used from diagnoses of cancer to winning of Presidential elections, to the creation of art, making real life money, etc. Some of the primary applications of data science range from:
Data Science Training - Using R and Python

The comparison between the two can be based on three broad parameters.
Neural networks are the ones which duplicate the techniques used by humans to learn. They are based on the same pattern as our neurons operate in our brains. The most prevalent neural network consists of three network layers, namely:

Each layer has neurons known as ‘nodes’ for performing different operations. Neural networks are employed in many deep learning algorithms like CNN, GAN, RNN, etc.
An MLP or a multi-layer perceptron has an input layer, a hidden layer, and even an output layer like a neural network. It shares the structure with a single layer perceptron with more than one hidden layer. While the latter can be used for classification of only linear separable classes which have binary output, the MLP can be used for classification of non-linear classes. It makes use of backpropagation, which is a supervised propagation method.
Data normalization means standardization and reforming of data for removing data redundancy. As the data enters and you can get the same information in different formats. You have to rescale, thus the values for making them fit into a specific range for better convergence.
Boltzmann Machines is one of the most elementary models of deep learning, which looks like a simplified version of the Multi-Layer Perceptron. There is a visible input layer along with a hidden layer which helps to make stochastic decisions if the neuron should be on or off. Although there are nodes which are connected across the layers in the same layer, no two nodes are connected.
An activation function operates at the basic level and goes on to decide if the neuron should be fired or not. It accepts both a weighted sum of inputs and even a bias as an input — E.G., step function, sigmoid, ReLU, Tanh, Softmax, etc.
A cost function is also known as a loss or error function and is a measure for evaluation of the performance of your model. It is used for computation of the error during backpropagation. The error is pushed backward via the neural networks and is further used during different training functions.
A Gradient Descent is an optimal algorithm for minimizing a cost function and also minimizing the error. The primary aim is to look for the local global minima of a function. It also helps in deciding the direction which should be taken by the model for reduction of error.
Backpropagation is a technique for improving the performance of a network. It helps to backpropagate or push the error and even allows updating of the weights for reduction of the error.
Feedforward Neural Network: This network allows traveling of signals only in one direction, i.e. from input to output without any feedback loops. The network considers only the current input as the previous ones cannot be remembered by it.
Recurrent Neural Network: This network allows the signals to travel in both the directions leading to the creation of a network of loops. Unlike the feedforward networks, this considers the current input with the previously received inputs for the generation of the output of layers. It has an internal memory which helps it to memorize the data.
Data Science Training - Using R and Python

These are those parameters whose value is decided before the beginning of the learning process. It helps to find out about the training pattern of the network and also the structure of the network.
In case you have a variable learning rate, i.e. it is too high or too low, the training of the model will see very slow progress as only small updates to the weights are being made. Many updates are needed for reaching the minimum point. If the learning rate is kept too high, it leads to unwanted divergent behavior to the loss function because of drastic updates in weights. It is possible that it leads to failed convergence or divergence.
Overfitting results with non-linear models are endowed with enhanced flexibility to learn a target function. It often happens when the model learns the details and noise in the training data to the extent that it affects the execution of the same on new information.
Underfitting takes place when there is less or improper data for training a model. It is endowed with poor performance and accuracy. For combatting both, data can be resampled for estimating the accuracy of the model.
Q20). How are the weights initialized in a network?
Weights in a network are initialized by two methods broadly i.e. either the weights can be initialized to zero or assigned randomly.
Data Science Training - Using R and Python

CNN has four layers, namely:
TensorFlow provides both the C++ and the Python APIs hence making working on it much easier. Also, the compilation time is faster when compared to various Deep Learning libraries like the Keras and the Torch. Both CPU and GPU are supported by TensorFlow.
Tensor represents a mathematical object depicted by higher dimension arrays. It is these data arrays which come in different dimensions and ranks which are fed as inputs to the neural networks, known as Tensors.
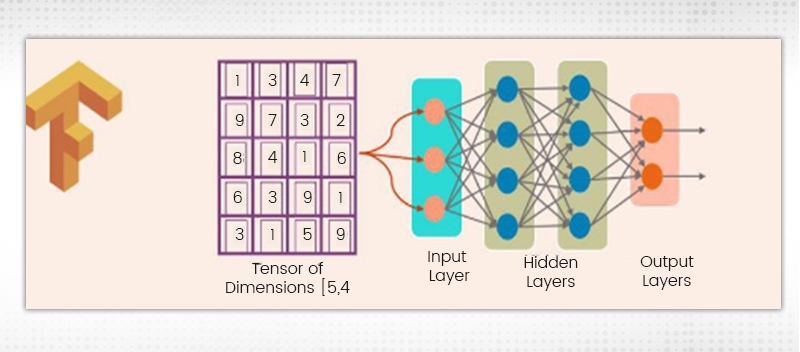
Computational Graph is needed for creating anything in TensorFlow. There is a network of nodes, each of which performs a particular operation. The nodes in the graph represent the mathematical operations while the tensors are represented by the edges. It is also called a DataFlow Graph.
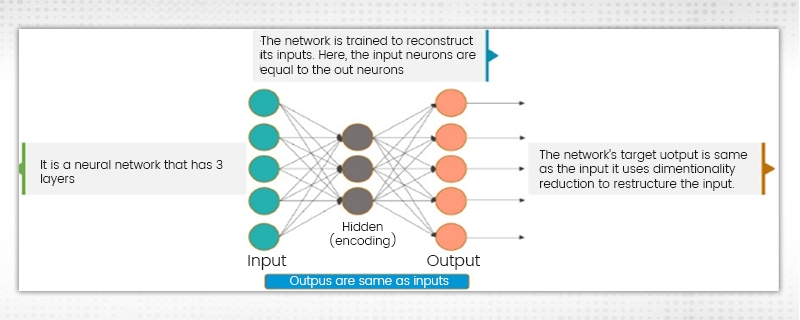
There are three layers in the Neural Network where the input neurons are just equal to the output neurons. The target of the network outside is similar to the input. A reduction in dimensionality is used for restructuring the input. The image input is compressed to a hidden space representation, and the output is then reconstructed using this representation.
Both bagging and boosting are ensemble techniques which are used to train multiple models by making use of the same learning algorithms. In the case of bagging, a dataset is taken and later split into training data and test data. The data is then randomly selected for placing into the bags and the model is trained separately. On the other hand, in case of boosting, the stress is on the selection of data points which give incorrect output for improving the accuracy.
Bagging:

Boosting:

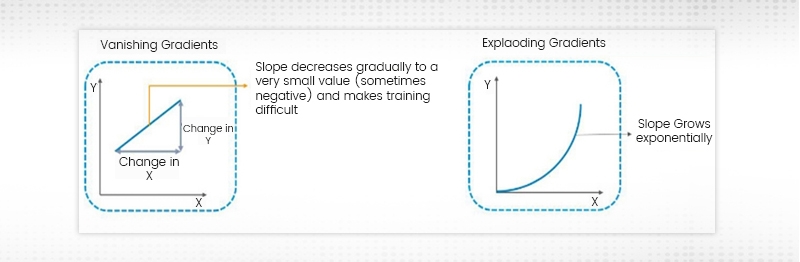
During RNN Training, the slope can either be too small or too large. When the slope is too small the problem is called the “Vanishing Gradient” while when the slope grows exponentially it is called the “Exploding Gradient”. The problems regarding the gradients often result in longer training times and decreased accuracy.
Several important machine learning and deep learning interview questions have been touched and discussed in this blog. These are the most probable ones and if done carefully can help you land in your dream job. The career prospects of Deep Learning are immense, so one has to do the right kind of preparation for moving further in the interview. Prepare well and take heart that everything will work in your favor. You can also carry out a search on google to know more such questions, put in keywords like “nvidia deep learning interview questions” or “advanced deep learning interview questions”. Once you read them all, make sure to download a deep learning interview questions pdf so that you can keep revising the concepts on your way to the interview.
Deep learning is an evolving technology and it is already showing a great demand. So, involving yourself into right now would be the best option. Sign up for the Deep learning tutorial to become better at it.

Statistics Interview Question and Answers
 May 16, 2024
May 16, 2024  3.6k
3.6k
Data Warehouse Interview Question And Answers in 2024
May 22, 2024 3k

Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment

![Scikit-Learn Interview Questions You Must Know [With Sample Answers] image](https://www.janbasktraining.com/interview-questions/uploads/images/banner_img_4_2.jpg)







