 Grab Deal : Upto 30% off on live classes + 2 free self-paced courses - SCHEDULE CALL
Grab Deal : Upto 30% off on live classes + 2 free self-paced courses - SCHEDULE CALL
Grab Deal : Upto 30% off on live classes + 2 free self-paced courses - SCHEDULE CALL
Distance metrics play an important role in data science by helping us measure the similarity or dissimilarity between data points. This is important because it helps algorithms make decisions based on how close or far apart data points are from each other. For beginners, distance metrics help grasp critical concepts in machine learning and data analysis, whereas for advanced practitioners, it can help optimize models, fine-tune parameters, and solve complex data science problems more effectively.
These distance metrics questions and answers for data science interviews will help you grasp fundamental concepts and problem-solving skills essential in data science practice.
A: Distance metrics are a big part of how computers learn patterns. They're like rules that help the computer decide how similar things are. These rules are used in different learning tasks, like sorting things into groups or predicting new things.
For example, imagine you have many points on a graph and want to group them together based on how close they are to each other. To do this, you need a way to measure how similar the two points are. If their characteristics are alike, we say they're similar. When you plot these points, the closer they are, the more similar they are.
A: Some common ways computers measure distance in learning tasks are:
Hamming Distance
Euclidean Distance
Manhattan Distance
Minkowski Distance
A: There are four main methods to measure distances in space:
Radar
Parallax
Standard Candles
Hubble Law
Each method works best at different distances. For example, radar works well for nearby distances, while the Hubble Law is best for far distances.
A: K-Means is a method for grouping data points into clusters. It mainly uses Euclidean distances between points to determine their similarity. It calculates the distance between each point and a central point (called a centroid) in the cluster. The "centroid" idea comes from geometry, specifically Euclidean geometry.
A: Distance metrics are super important in machine learning because they help algorithms like K-Nearest Neighbors, K-Means Clustering, and Self-Organizing Maps figure out how similar or different data points are. Think of them as rules that guide these algorithms in making decisions. Understanding these rules is crucial because they affect how well our algorithms perform. We prefer one rule over another depending on the data and our algorithm. So, it's good to know what each rule does.
A: Manhattan distance is a way to measure how far apart two points are in a grid-like space, like navigating city blocks in Manhattan. Instead of going in a straight line, you move along the grid's paths, adding up the distances between the coordinates of the points. It's called "Manhattan" distance because it's like travelling through the streets of Manhattan, where you can't just move straight from point A to point B.
A: Hamming distance is handy when dealing with data that has binary features, meaning they're either 0 or 1. It's like comparing binary strings, looking at where they differ. For example, if you're analyzing telecom customer data with features like gender (0 or 1), marital status (0 or 1), age range (0 or 1), etc., Hamming distance helps measure how similar two customers are. You just count how many feature values are different between them
A: An embedding is a point representation of the vertices of a graph that captures some aspect of its structure. Performing a feature compression like eigenvalue or singular value decomposition on the adjacency matrix of a graph produces a lower-dimensional representation that serves as a point representation of each vertex. Other approaches to graph embeddings include DeepWalk.
A: Locality-sensitive hashing (LSH) is defined by a hash function h(p) that takes a point or vector as input and produces a number or code as output such that it is likely that h(a) = h(b) if a and b are close to each other, and h(a) 6= h(b) if they are far apart.
Such locality-sensitive hash functions readily serve the same role as the grid index without the fuss. We can simply maintain a table of points bucketed by this one-dimensional hash value and then look up potential matches for query point q by searching for h(q).
A: A graph G = (V, E) is undirected if edge (x, y) ∈. E implies that (y, x) is also in E. If not, we say that the graph is directed. Road networks between cities are typically undirected since any large road has lanes in both directions.
Street networks within cities are almost always directed because at least a few one-way streets are lurking somewhere. Webpage graphs are typically directed because the link from page x to page y need not be reciprocated.
A: We say a distance measure is a metric if it satisfies the following properties:
Positivity: d(x, y) ≥ 0 for all x and y.
Identity: d(x, y) = 0 if and only if x = y.
Symmetry: d(x, y) = d(y, x) for all x and y.
Triangle inequality: d(x, y) ≤ d(x, z) + d(z, y) for all x, y, and z.
These properties are important for reasoning about data. Indeed, many algorithms work correctly only when the distance function is a metric.
A: Graphs are sparse when only a small fraction of the total possible vertex pairs 
for a simple, undirected graph on n vertices) actually have edges defined between them. Graphs where a large fraction of the vertex pairs define edges are called dense. There is no official boundary between what is called sparse and what is called dense, but typically dense graphs have a quadratic number of edges, while sparse graphs are linear in size.
Sparse graphs are usually sparse for application-specific reasons. Road networks must be sparse graphs because of road junctions. The most ghastly intersection I’ve ever heard of was the endpoint of only nine different roads. k-nearest neighbor graphs have vertex degrees of exactly k. Sparse graphs make possible much more space efficient representations than adjacency matrices, allowing the representation of much larger networks.
A: PageRank is best understood in the context of random walks along a network. Suppose we start from an arbitrary vertex and then randomly select an outgoing link uniformly from the set of possibilities. Now repeat the process from here, jumping to a random neighbor of our current location at each step. The PageRank of vertex v is a measure of probability that, starting from a random vertex, you will arrive at v after a long series of such random steps. The basic formula for the PageRank of v (P R(v)) is:

This is a recursive formula, with j as the iteration number. We initialize P R0(vi) = 1/n for each vertex vi in the network, where 1 ≤ i ≤ n. The PageRank values will change in each iteration, but converge surprisingly quickly to stable values. For undirected graphs, this probability is essentially the same as each vertex in-degree, but much more interesting things happen with directed graphs.
A: The Lk distance metric or norm is a general family of distance functions represented by the formula dk(p, q) = (Σᵢ|pi - qi|^k)^(1/k), where k is a parameter that determines the trade-off between the largest and total dimensional differences. This metric encompasses various popular distance metrics, including:
Manhattan distance (k = 1): Also known as L1 distance, it calculates the total sum of deviations between dimensions. In urban analogy, it reflects the distance travelled along city blocks, where movement is constrained to north-south and east-west directions, with no diagonal shortcuts. This makes it suitable for linear dimensions, treating differences equally regardless of direction.
Euclidean distance (k = 2): This is the traditional distance metric, favouring larger dimensional deviations while still considering lesser dimensions. It calculates the straight-line or "as-the-crow-flies" distance between two points, commonly used in various fields such as machine learning and geometry.
Maximum component (k = ∞): As k approaches infinity, smaller dimensional differences become negligible, and the distance calculation focuses solely on the largest deviation among dimensions. This is akin to selecting the maximum difference between corresponding components in multidimensional space.
A: Vectors and points are both defined by arrays of numbers, but they are conceptually different beasts for representing items in feature space. Vectors decouple direction from magnitude, and so can be thought of as defining points on the surface of a unit sphere.
Vectors are essentially normalized points, where we divide the value of each dimension of p by its L2-norm L2(p), which is the distance between p and the origin O:
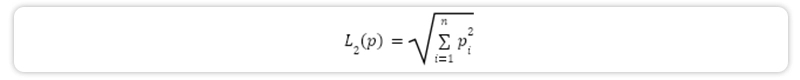
After such normalization, the length of each vector will be 1, turning it into a point on the unit sphere about the origin.
A: The Kullback-Leibler (KL) divergence measures the uncertainty gained or information lost when replacing distribution P with Q. Specifically,
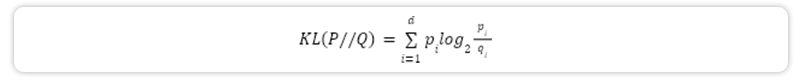
Suppose P = Q. Then nothing should be gained or lost, and KL(P, P) = 0 because lg(1) = 0. But the worse a replacement Q is for P, the larger KL(P||Q) gets, blowing up to ∞ when pi > qi = 0.
The KL divergence resembles a distance measure, but is not a metric, because it is not symmetric (KL(P||Q) 6= KL(Q||P)) and does not satisfy the triangle inequality. However, it forms the basis of the Jensen-Shannon divergence JS(P, Q):
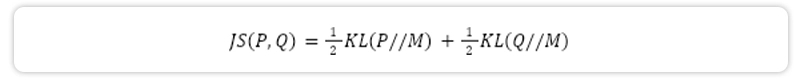
where the distribution M is the average of P and Q, i.e. mi = (pi + qi)/2.
JS(P, Q) is clearly symmetric while preserving the other properties of KL divergence. Further JS(P, Q) magically satisfies the triangle inequality, turning it into a true metric. This is the right function to use for measuring the distance between probability distributions.
A: There are three big advantages to nearest neighbour methods for classification:
Simplicity: Nearest neighbour methods are not rocket science; there is no math here more intimidating than a distance metric. This is important because it means we can know exactly what is happening and avoid being the victim of bugs or misconceptions.
Interpretability: Studying the nearest neighbors of a given query point q explains exactly why the classifier made the decision it did. If you disagree with this outcome, you can systematically debug things. Were the neighboring points incorrectly labeled? Did your distance function fail to pick out the items that were the logical peer group for q?
Non-linearity: Nearest neighbor classifiers have decision boundaries that are piecewise linear. From calculus, we know that piecewise linear functions approach smooth curves once the pieces get small enough. Thus, nearest neighbor classifiers enable us to realize very complicated decision boundaries, indeed surfaces so complex that they have no concise representation.
A: One approach to speeding up the search involves using geometric data structures. Popular choices include:
Voronoi diagrams: For a set of target points, we would like to partition the space around them into cells such that each cell contains exactly one target point. Further, we want each cell's target point to be the nearest target neighbour for all locations in the cell. Such a partition is called a Voronoi diagram.
Grid indexes: We can carve up space into d-dimensional boxes by dividing the range of each dimension into r intervals or buckets. For example, consider a two-dimensional space where each axis was a probability, thus ranging from 0 to 1. This range can be divided into r equal-sized intervals, such that the ith interval ranges between [(i − 1)/r, i/r].
Kd-trees: There are a large class of tree-based data structures which partition space using a hierarchy of divisions that facilitates search. Starting from an arbitrary dimension as the root, each node in the kd-tree defines a median line/plane that splits the points equally according to that dimension. The construction recurs on each side using a different dimension, and so on until the region defined by a node contains just one training point.
A: A graph G = (V, E) is defined on a set of vertices V and contains a set of edges E of ordered or unordered pairs of vertices from V. In modelling a road network, the vertices may represent the cities or junctions, certain pairs of which are directly connected by roads/edges. In analyzing human interactions, the vertices typically represent people, with edges connecting pairs of related souls.
Many other modern data sets are naturally modelled in terms of graphs or networks:
The Worldwide Web (WWW): Here, there is a vertex in the graph for each webpage, with a directed edge (x, y) if webpage x contains a hyperlink to webpage y.
Product/customer networks arise in any company with many customers and types of products, such as Amazon, Netflix, or even the corner grocery store. There are two types of vertices: one set for customers and another for products. Edge (x, y) denotes a product y purchased by customer x
Genetic networks: Here, the vertices represent a particular organism's different genes/proteins. Think of this as a parts list for the beast. Edge (x, y) denotes interactions between parts x and y. Perhaps gene x regulates gene y, or proteins x and y bind together to make a larger complex. Such interaction networks encode considerable
information about how the underlying system works.
A: Agglomerative clustering returns a tree on top of the groupings of items. After cutting the longest edges in this tree, what remains are the disjoint groups of items produced by clustering algorithms like k-means. But this tree is a marvellous thing, with powers well beyond the item partitioning:
Organization of clusters and subclusters: Each internal node in the tree defines a particular cluster composed of all the leaf-node elements below it. But the tree describes the hierarchy among these clusters, from the most refined/specific clusters near the leaves to the most general clusters near the root.
Ideally, tree nodes define nameable concepts: natural groupings that a domain expert could explain if asked. These various levels of granularity are important because they define structural concepts we might not have noticed before doing clustering.
A natural measure of cluster distance: An interesting property of any tree T is that there is exactly one path in T between any two nodes, x and y. Each internal vertex in an agglomerative clustering tree has a weight associated with the cost of merging the two subtrees below it.
We can compute a "cluster distance" between any two leaves by the sum of the merger costs on the path between them. If the tree is good, this can be more meaningful than the Euclidean distance between the records associated with x and y.
A: Clustering is perhaps the first thing to do with any interesting data set. Applications include:
Hypothesis development: Learning that there appear to be (say) four distinct populations represented in your data set should spark the question of why they are there. If these clusters are compact and well-separated enough, there has to be a reason, and it is your business to find it.
Once you have assigned each element a cluster label, you can study multiple representatives of the same cluster to determine what they have in common or look at pairs of items from different clusters to identify why they are different.
Data reduction: Dealing with millions or billions of records can be overwhelming for processing or visualization. Consider the computational cost of identifying the nearest neighbor to a given query point or trying to understand a dot plot with a million points.
One technique is to cluster the points by similarity and then appoint the centroid of each cluster to represent the entire cluster. Such nearest-neighbor models can be quite robust because you are reporting the consensus label of the cluster, and it comes with a natural measure of confidence: the accuracy of this consensus over the full cluster.
Outlier detection: Certain items resulting from any data collection procedure will be unlike all the others. Perhaps they reflect data entry errors or bad measurements. Perhaps they signal lies or other misconduct. Or maybe they result from the unexpected mixture of populations, a few strange apples potentially spoiling the entire basket.
Data Science Training - Using R and Python

In data science interviews, showcasing knowledge of distance metrics demonstrates your ability to analyze and interpret data effectively, giving you an edge in landing your dream job. JanBask Training's data science courses can be immensely helpful in this journey. With their comprehensive curriculum and expert instructors, you'll learn about distance metrics and gain practical experience through hands-on projects.

Statistics Interview Question and Answers
 May 16, 2024
May 16, 2024  2.4k
2.4k

Data Warehouse Interview Question And Answers in 2024
May 22, 2024 1.5k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment

![Scikit-Learn Interview Questions You Must Know [With Sample Answers] image](https://www.janbasktraining.com/interview-questions/uploads/images/banner_img_4_2.jpg)







