Hadoop is running like a storm in the era of technology. Hadoop is said to be the new age of Big Data. When you Google Hadoop, you will get approximately 28 million results. One of the primary reasons for the popularity of Hadoop is the phenomenal growth of the cloud. In this blog post, we will have a closer look at the architecture and methods of Hadoop clusters to understand the internal working of Hadoop.
What does Hadoop Mean?
Hadoop is actually an open-source software framework that stores the data in parallel. Hadoop consists of a collection of libraries which are used to process large data sets; (large here means 4 million search queries per minute on Google) across thousands of computers in the form of smaller data sets. These machines will then process these small amounts of data and give the results which are finally aggregated, and the final result is reached. This is what exactly Hadoop does, and this is the problem Hadoop is designed to solve. If we calculate data of one large organization on the server, it will cross thousands! What will happen if we collaborate data of all the search engines, it’s beyond imagination! Thus to overcome this situation, companies like Google, Yahoo, and Bing looked for the solutions to manage all data that their servers were gathering in an efficient and cost-effective manner. Hadoop was created by a Yahoo! Engineer- Doug Cutting, as a counter-weight to Google’s BigTable. Hadoop was Yahoo!’s attempt to break down the big data problem into small pieces that could be processed in parallel. Hadoop is now anopen source project available under Apache License 2.0.
What does Hadoop do?
The origin behind the Hadoop is to solve the problem to process a large amount of data which can’t be processed by single machines within acceptable time limits to get desired outcomes. The power of Hadoop lies in its framework, as virtually most of the software can be plugged into it and can be used for data visualization. It can be extended from one system to thousands of systems in a cluster, and these systems could be low-end commodity systems. Hadoop does not depend upon hardware for high availability. The two primary reasons to support the question “Why use Hadoop” –
- The cost savings with Hadoop are dramatic when compared to the legacy systems.
- It has robust community support that is evolving over time with novel advancements.
Going forward, if you are thinking under what is Hadoop used for or the circumstances under which using Hadoop is helpful then here’s the answer-
- Hadoop is used in big data applications that gather data from disparate data sources in different formats. HDFS is flexible in storing diverse data types, irrespective of the fact that your data contains audio or video files (unstructured), or contain record level data just as in an ERP system (structured), log file or XML files (semi-structured). Hadoop is used in big data applications that have to merge and join data - clickstream data, social media data, transaction data or any other data format.
- Large scale enterprise projects that require clusters of servers where specialized data management and programming skills are limited, implementations are a costly affair- Hadoop can be used to build an enterprise data hub for the future.
- Do not make the mistake of using Hadoop when your data is just too small, say in MB’s or GB’s. To achieve high scalability and to save both money and time- Hadoop should be used only when the datasets are in petabytes or terabytes; otherwise, it is better to use Postgres or Microsoft Excel.
How does Hadoop Work?/Hadoop components and domains
To process any data, the client submits data and program to Hadoop. HDFS stores the data whereas, MapReduce process the data and Hadoop YARN divide the tasks. Hadoop has the following major layers: Let us go through each of these blocks superficially.
Read: Apache Flink Tutorial Guide for Beginner
- Hadoop Common – The role of this component of Hadoop is to provide common utilities that can be used across all modules
- Hadoop MapReduce – The role of this component f Hadoop is to carry out the work which is assigned to it. That is, it does the work of scheduling and processing across the data clusters. Thus, it is said to be the right hand of Hadoop. As whole data of the company’s server has to be stored in the cloud; thus, Hadoop acts as a data warehousing system. So, it needs a library like MapReduce to process the data in an actual manner. MapReduce runs a series of jobs, with each job specifically a separate Java application that goes out into the data and starts pulling out information as required. Using MapReduce instead of a query (Structured Query Language - SQL) gives data seekers a lot of power and flexibility, but also adds a lot of complexity. There are several tools available that make this job easier: Hive, which is another Apache application that helps in the conversion of the query language into MapReduce jobs. But MapReduce’s complexity and its limitation to one-job-at-a-time batch processing tend to result in Hadoop getting used more often as a data warehousing than as a data analysis tool.
- Hadoop distributed file system (HDFS) – HDFS is said to be the left hand of Hadoop. The job of HDFS is to maintain all the records, that is, file system management across the cluster. Files in HDFS are split into blocks before they are stored into a cluster. The typical size of a block is 64 MB or 128 MB. HDFS is like a bucket of the Hadoop system: you dump in your data and sit back until you want to do something with it. The running of an analysis on it within Hadoop or exporting and capturing a set of data to another tool and performing the analysis there.
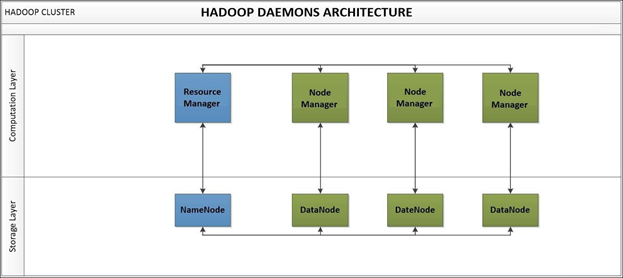
- Hadoop YARN – Hadoop YARN came the update of Hadoop. It is the newer version and important version (2-0) of MapReduce and does the same work as MapReduce. There are two daemons running for YARN. One is NodeManager on the slave machine, and the other is Resource Manager on the master node. YARN takes care of the allocation of the resources among various slaves competing for it.
Daemons are basically the processes that run in the background. There are a total of 5 daemons in Hadoop. These daemons run for Hadoop to make it functional. These are listed below:-
- Name the node: It stores the Metadata about the data that are stored in DataNodes, and it runs on a master node for HDFS. It contains information such as the blocks that made a file and the location of those blocks in the cluster.
- Data node: It stores the actual data, and it runs on a slave node for HDFS. It reports information about the blocks which contains the Name node in a periodic fashion.
- Secondary Data node: It is the backup of the name node, and it only contains entire Metadata node properties, address, and block report of each data node. It keeps a copy of the image which can be used in case of failure of the name node.
- Resource manager: It runs on YARN slave node for MapReduce
- Node manager: It runs on YARN slave node for MapReduce
 Other than daemons, some components are adjoined to HDFS:-
Other than daemons, some components are adjoined to HDFS:-
- Writing files on the cluster
- Reading a file from the cluster
- Fault tolerance Strategy
- Replication Strategy
Writing files on the cluster
- The user through a client requests to write data on a Hadoop cluster.
- The user sets the replication factor (default 3) and blocks size through the configuration options.
- The client splits the file into blocks and contacts the NameNode.
- The NameNode returns the DataNodes (in increasing order of the distance from the client node).
- The Client sends the data to the first DataNode, which while receiving the data, transfers the same to the next DataNode (which does the same and this forms the replication pipeline).
- The DataNodes send acknowledgments to the NameNode on successfully receiving the data.
- The Client repeats the same process for all the other blocks that constitute the file.
- When all the blocks are written on the cluster, the NameNode closes the file and stores the meta-data information.
Reading data from the cluster
- The user provides the filename to the client.
- The Client passes the filename to the NameNode.
- The NameNode sends the name of the blocks that constitute the file. Its also sends the location (DataNode) where the blocks are available (again in increasing order of the distance from the client).
- The Client then downloads the data from the nearest DataNode.
Fault tolerance strategy
There are three types of failure that can occur, namely, node failure, communication failure, and data corruption.
- In the case of NameNode failure, the responsibility of the Secondary NameNode comes into play. The NameNode then has to restore with the help of the merged copy of the NameNode image.
- The DataNode sends a heartbeatmessage to the NameNode every 3 seconds to inform the NameNode that it is alive. If the NameNode doesn’t receive a heartbeat message from the DataNode in 10 mins (configurable), it considers the DataNode to be dead. It then stores the replica of the block in some other DataNode.
- The Client receives an ACK form the DataNode that it has received the data. If it doesn’t work after several tries, it is understood that either there is network failure or the DataNode has failed.
- A checksum is sent along with the data to look for data corruption.
- Periodically the DataNodes sends the report containing the list of blocks that are uncorrupted. The NameNode then updates the list of valid blocks a DataNode contains.
- For all such under-replicated blocks, the NameNode adds other DataNodes to the replication pipeline.
Replication strategy
The replication factor is set the three by default (can be configured). The cluster is split in terms of racks, where each rack contains DataNodes.
- The NameNode tries to make the client as the first DataNode replica. If it is not free, then any node in the same rack as that of the client is made the first replica.
- Then the other two replicas are stored on two different DataNodes on a rack different from the rack of the first replica.
Let us summarize how Hadoop works step by step:
Read: Scala VS Python: Which One to Choose for Big Data Projects
Step1: Input data is broken into blocks of size 64 Mb or 128 Mb, and then blocks are moved to different nodes.
Step 2: Once all the blocks of the data are stored on data-nodes, user can process the data.
Step 3: Resource Manager, then schedules the program (submitted by the user) on individual nodes.
Step 4: Once all the nodes process the data, the output is written back on HDFS.
Expert Tip: If you are also the one who get this- “Hadoop error: Input path does not exist”
Read: An Introduction to Apache Spark and Spark SQL
Solution: Upload the input files to HDFS and try the following command in the command prompt:- bin/hadoop fs –mkdir In
Closing remarks
In this blog, we have tried to cover the internal functionality and working of Hadoop. Hadoop is the out-of-the-box solution for every task related to Big Data, thus, it is likely to remain like an elephant in the Big Data room. We hope this would help you to learn about the working and fundamental aspects of Hadoop. If you are looking forward to the career in Hadoop, or you find Hadoop is the right career option for you, then go ahead and talk to our counselor on how to get started on the learning path of Hadoop. Share your views or queries below in the comments section below. Happy learning!
Hadoop Course
Upcoming Batches
Trending Courses
Cyber Security
- Introduction to cybersecurity
- Cryptography and Secure Communication
- Cloud Computing Architectural Framework
- Security Architectures and Models
Upcoming Class
1 day 12 Jun 2026
QA
- Introduction and Software Testing
- Software Test Life Cycle
- Automation Testing and API Testing
- Selenium framework development using Testing
Upcoming Class
2 days 13 Jun 2026
Salesforce
- Salesforce Configuration Introduction
- Security & Automation Process
- Sales & Service Cloud
- Apex Programming, SOQL & SOSL
Upcoming Class
1 day 12 Jun 2026
Business Analyst
- BA & Stakeholders Overview
- BPMN, Requirement Elicitation
- BA Tools & Design Documents
- Enterprise Analysis, Agile & Scrum
Upcoming Class
15 days 26 Jun 2026
MS SQL Server
- Introduction & Database Query
- Programming, Indexes & System Functions
- SSIS Package Development Procedures
- SSRS Report Design
Upcoming Class
1 day 12 Jun 2026
Data Science
- Data Science Introduction
- Hadoop and Spark Overview
- Python & Intro to R Programming
- Machine Learning
Upcoming Class
1 day 12 Jun 2026
DevOps
- Intro to DevOps
- GIT and Maven
- Jenkins & Ansible
- Docker and Cloud Computing
Upcoming Class
7 days 18 Jun 2026
Hadoop
- Architecture, HDFS & MapReduce
- Unix Shell & Apache Pig Installation
- HIVE Installation & User-Defined Functions
- SQOOP & Hbase Installation
Upcoming Class
8 days 19 Jun 2026
Python
- Features of Python
- Python Editors and IDEs
- Data types and Variables
- Python File Operation
Upcoming Class
9 days 20 Jun 2026
Artificial Intelligence
- Components of AI
- Categories of Machine Learning
- Recurrent Neural Networks
- Recurrent Neural Networks
Upcoming Class
2 days 13 Jun 2026
Machine Learning
- Introduction to Machine Learning & Python
- Machine Learning: Supervised Learning
- Machine Learning: Unsupervised Learning
Upcoming Class
15 days 26 Jun 2026
Tableau
- Introduction to Tableau Desktop
- Data Transformation Methods
- Configuring tableau server
- Integration with R & Hadoop
Upcoming Class
8 days 19 Jun 2026
 May 16, 2019
May 16, 2019  420.4k
420.4k

 Other than daemons, some components are adjoined to HDFS:-
Other than daemons, some components are adjoined to HDFS:-























 Mar 20, 2018
Mar 20, 2018 421.4k
421.4k
