Introduction
According to a survey by IBM-
“Approximately 80% of data created today comes from satellites utilized for gathering climate information, social media websites, digital pictures, videos, and GPS signals to name a few.”
As the volumes of data being generated are constantly growing, and hence data management becomes difficult. But having said that, this issue can be resolved if the data is stored across a network of machines, and these networks of machines/filesystems are referred to as distributed filesystems! Wherein “HADOOP” comes into play and offers a consistent file system, mostly referred to as HDFS, i.e., Hadoop Distributed File System. It’s a unique design that offers storage for exceedingly large files.
What is HDFS in Big Data?
HDFS is a highly trustworthy storage system worldwide that is used for storing a limited number of huge files rather than large numbers of small data files. It comes with an excellent data backup system that is helpful even during a situation of failure. HDFS provides a fault-tolerant storage layer for Hadoop and its components, including instant data access, simultaneously.

Now, let us begin with our HDFS tutorial guide, which covers what Hadoop distributed file system provides in detail from scratch.
This HDFS tutorial will cover the main topics related to HDFS like, what is HDFS in Big data and what Hadoop distributed file system provides, including HDFS nodes, Daemons, RACK, data storage, HDFS architecture, features and HDFS operations, benefits of learning HDFS, etc. Once you go through the blog carefully, you will get a perfect idea of the HDFS filesystem, and also, you will know whether getting Big Data Hadoop Certification is the right career choice for you or not.
For Big Data Hadoop Certification, get yourself signed in for a comprehensive, real-world project-led Hadoop Online Certification Training Program to master the skills and tools in the Hadoop ecosystem.
HDFS Nodes
HDFS is based on master-slave architecture and has two nodes;
- NameNode (Master) and
- DataNode (slave).
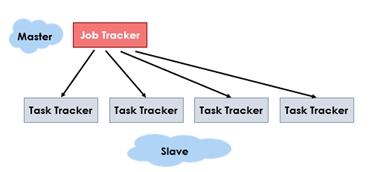
NameNode is also termed as the ‘master’ node that handles all slave nodes and assigns jobs to each of them. It is always deployed on reliable hardware only and taken as the heart of the HDFS framework. It executes the main namespace operations like reading, writing, and renaming a file. Here, in the image, there is an example of a master-slave relationship where the Job Tracker is the master node, and the Task trackers are the slave nodes.
- DataNode is also a ‘slave’ node deployed over different machines and responsible for the actual data storage. Further, the read-write operations in HDFS are also managed through the slave node. They block, delete, or replicate data from the master node.
Pro-Tip- Do you want to get Big Data Hadoop Certified and be future-ready? Then enroll today in an Online Data Management Course by JanBask Training and boost your career by mastering the database fundamentals and gaining industry knowledge to handle databases.
HDFS Daemons
There are two HDFS Daemons, as shown in the image above; one is NameNode, and the other is DataNode.
- NameNode – This daemon runs over all the master nodes and stores the complete metadata information like filenames, IDs, block details, etc. In the case of HDFS, data is stored in the form of physical blocks, and each has a unique ID assigned to it. The metadata backup is also available on the secondary name node and can be accessed in case of emergency. This is why the number of name nodes should be higher per the requirement.
- DataNode - This daemon runs over all the slave nodes that are actually responsible for the data storage.
Find out potential Hadoop Career Opportunities through our Big Data Hadoop Developer Career Path & Future Scope blog.
HDFS Data Storage Explained in Detail
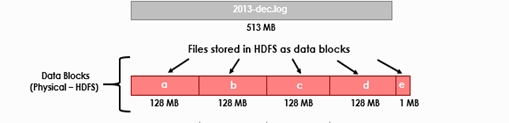
Every time a file is copied to the HDFS, it is first divided into small data chunks termed blocks. The default storage size in HDFS is 128 MB which can be optimized based on requirements.
Further, these data blocks are stored in the cluster in a distributed manner. With the help of MapReduce, data can be processed in parallel inside clusters. Multiple copies of data are replicated across different nodes with maximum fault-tolerant capacity, reliability, or availability, etc.
You will better understand the data storage process in HDFS by looking at the image given below -
Take a closer look at the best learning strategy to learn Hadoop quickly through our blog post -how long does it take to learn Hadoop?
What is RACK in HDFS?
Hadoop runs over clusters distributed across different racks. Also, the name node daemon places a replica of the data block on different racks to improve the fault-tolerant capabilities. The HDFS Daemons try to put a replica of the data block on every rack to prevent data loss in all possible cases. The objective of RACK in HDFS is to optimize data storage, network bandwidth, or data reliability, etc.
HDFS Architecture in Big Data
The following image gives you a detailed picture of HDFS architecture in Big Data, where there is only a single name node to store the metadata information. At the same time, n number of data nodes are responsible for actual storage work. Further, data nodes are arranged in racks, and replicas of data blocks are distributed across racks in the Hadoop cluster to provide data reliability, fault tolerance, or availability.
The client sends a request to the name node when he wants to write operations in the file. As soon as the request is processed, a file is created and cannot be edited again. For everything, the client needs to interact with the name node as it is taken to the heart of the HDFS framework.
HDFS Features Explained in Detail
As we know, data is stored in a distributed manner in HDFS. Data is distributed across small nodes of the cluster. HDFS is the best way to process large data files and parallel execution of data. You will be surprised to know that MapReduce is the centerpiece here that supports distributed data storage for HDFS.
Every time a file is copied to the HDFS, it is first divided into small data chunks termed blocks. The default storage size in HDFS is 128 MB which can be optimized based on requirements. Further, these data blocks are stored in the cluster in a distributed manner. With the help of MapReduce, data can be processed in parallel inside clusters.
For example, if one data chunk is 129 MB, it will create two blocks for the same. One for 128 MB and the other for 1MB. HDFS is intelligent enough to understand that disk space should not be wasted and arranges the blocks accordingly.
New features always get added to Hadoop. Check out our blog post on what are the new features in Hadoop 3.0, to learn more.
Further, a minimum of three replicas of each data node are created to make it available all the time in an emergency. In other words, we can say that data loss is not the issue in the case of HDFS. The name node daemon always decides the placement of blocks and its replica. It picks up the data from the data node that can be loaded in a minimum time.
The duplicate copies of data nodes are termed replicas. HDFS creates a minimum of three copies of each data node that are distributed across racks of the cluster. The framework tries to place at least one copy of the data node in each rack.
What Do You Mean By RACK Exactly?
The rack concept is already discussed in earlier sections, whose main objective here is availability, reliability, and network bandwidth utilization.
When data is distributed across multiple nodes, it promotes data availability across clusters. For example, if some hardware goes down, data can be accessed from the different replicated nodes, ultimately resulting in high availability.
HDSA has a fault-tolerant storage layer for HDFS and its components. The working of HDFS is based on commodity hardware with average configurations, and it has a high chance of failure if some hardware goes down. To tolerate this fault, HDFS replicates data in multiple places and accesses it from anywhere if a particular data node responds. Also, the chances of data loss are almost negligible, which helps HFDS to attain fault-tolerant features and is used by top MNCs to secure their large data files.
Scalability signifies here the contraction and expansion of data across the cluster. There are two options for how scalability can be achieved in HDFS
1. Add More Disks On Nodes Of Cluster
For this purpose; you need to change the configuration settings and add multiple disks based on the requirement. You need to set downtime here, but it is significantly less. If this is not the right choice of scaling for you, then you can opt for another option that is discussed below.
2. Horizontal Scaling
The other popular option is horizontal scaling, where more nodes are added to the clusters instead of disks. Virtually, we can add n number of nodes to the cluster required for the project. This is a very attractive feature that is used by almost all leading MNCs worldwide to manage large data files.
Based on our discussion, this is clear that replication increase both fault tolerance capabilities and data availability. The third noticeable feature is data reliability. We know that data is replicated a minimum of 3 times, but it should not be over-replicated; otherwise, storage space would be wasted. So, destroying over-replicated data is necessary here to store the data reliably.
Do you want to ace your Big Data Hadoop interview in first attempt? Check out our blog post on Top 20 Big Data Hadoop Interview Questions and Answers 2018.
Do you know the meaning of throughout here? Throughout is the total amount of work completed in a unit time. It improves the overall data accessibility from the system and helps measure the overall system performance. If you are planning to execute some task, it should be divided well and distributed among multiple systems to handle the workload. This will execute all tasks independently in parallel. This will only complete the task in a short time and reduce the overall time to read operations.
HDFS Read & Write Operations
To read or write any data file, the client must first interact with the name node. It will process the request, and the operation will be completed accordingly. For this purpose, you must follow the authentication process entirely and start reading or writing data as needed.
HDFS Command Line
Following are a few primary command lines of HDFS:
Benefits of learning HDFS and How it Boosts Your Career
It's very beneficial to learn HDFS because it’s by far the most reliable and fault-tolerant storage mechanism available and can be scaled up or down based on the requirements, making it really very hard to find any replacement for storing Big Data. So, after mastering this, you can get the upper hand when applying for Hadoop-related jobs. The majority of the world’s biggest MNCs are implementing Hadoop, such as Amazon, Facebook, Microsoft, Google, Yahoo, IBM, and General Electrics. They run substantial Hadoop clusters for storing and processing vast amounts of data. Hence, as a goal-seeking IT professional, learning HDFS can help you leave your competitors behind and make a giant leap in your career!
Want to know what are the benefits of learning Big Data Hadoop? Then click on the given link Top 10 Reasons Why Should You Learn Big Data Hadoop?
Final Words:
In this blog, we have discussed Hadoop HDFS in detail from scratch. The comprehensive tutorial guide is 100% suitable for beginners and gives a perfect framework idea. So, you might be willing to learn more about HDFS now. If yes, start your learning with the Big Data Hadoop Online Certification Training Course at JanBaskTraining and take your career to the new heights you have ever dreamt of.
FAQs
1. What is data management?
Ans :-Today, a massively valuable asset for organizations is - Data, and with the help of the data management process, this resource is collected, organized, stored, and accessed. Hence accurate data integration and Data management are the most critical parts of IT systems because they inform operational decision-making and strategic planning at the highest levels of an organization.
Database administration through DBMS (Database Management Systems) is one of the most essential responsibilities for professionals in this field.
2. What skills do I need to learn in data management?
Ans :-Professionals in Data management can have diverse educational backgrounds, like computer science, business administration, mathematics, and statistics. The most crucial skills required for them are organizational and interpersonal skills; also, they must be able to systematically collect, organize, and analyze large datasets while simultaneously communicating their relevance to both technical and non-technical audiences.
They also need to have strong computer science skills, including proficiency in programming languages like Python, and Java, database systems like SQL and NoSQL, and OSs like UNIX and LINUX. Data management professionals should know how to work with different cloud computing platforms such as Azure, IBM Cloud, and Google Cloud.
3. What are the different career opportunities in data management?
Ans :-Presently, big data in data management career has a significant opportunity for growth. Other wide ranges of roles requiring data management skills aside from database administrator are data managers, data management specialists, and IT project managers in order to build and manage data systems. On the more technical side, data scientists and engineers are responsible for building the data infrastructure required to efficiently collect massive datasets. Data mining and systems analysts, with the help of their expertise, turn these datasets into actionable business insights.
4. What skills or experience do I need before learning data management?
Ans :-You can have knowledge of at least basic computer skills before starting to learn data management. Having strong reading and math skills can also be helpful. furthermore, having the knowledge of spreadsheets can be useful for storing large amounts of data and organizing data sets for more accessible analysis and management.
5. What kind of people are best suited for roles in data management?
Ans :- People who like using computer technology for complex tasks are usually best suited for these roles. Because large organizations can collect vast amounts of data that can be organized into usable data sets, stored and retrieved by data managers when needed. People having strong critical thinking and analytical skills are also suitable for it.
6. What types of places hire people with a background in data management?
Ans :- Three places that typically hire people with a background in data management are -Laboratories, hospitals, and government agencies. Manufacturing businesses can also hire them to manage databases. Transportation and logistics firms can hire them to handle large data mining projects. Furthermore, organizations managing large amounts of data, like insurance companies and educational institutions, usually hire candidates with data management experience.
7. Which skills will I learn through your Data Management Courses?
Ans :-Skills you will learn through our competitive online data management course includes:
- Machine Learning
- Deep Learning
- Big Data
- Hadoop
- Oracle
- SQL
- Business Analytics
- Data Engineering & much more
8. What top management specializations can I achieve through your Data Management Courses?
Ans :- You can make your resume stand out from others and become career-ready with the following top data management specializations:
- Decision Scientist
- Data Scientist
- Data Analyst
- Data Engineer
- Machine Learning Engineer
- Data Architect
- Database Administrator
- Product Analyst
9. What are the benefits of Online Data Management Courses?
Ans :-Make the right move by enrolling in our Online Data Management Courses because it offers the following benefits.
- With these courses, you’ll get the undivided attention of instructors and mentors 24*7. You can connect anytime, from anywhere, to resolve your queries.
- These are flexible training sessions; study anytime you want without compromising your work schedule.
- You can earn lifetime access to top Data Management Beginner to Advanced courses customized to suit the changing industry needs.
- Online Data Management courses help the students to learn using different learning management systems, incorporate audio/video into assignments, participate in online training workshops and further enhance their technical skills.
10 . What are the features of these Online Data Management Courses?
Ans :-Features of our all-inclusive Online Data Management courses include:
- Build your skills to become job-ready.
- Live interaction classes from industry experts.
- Advanced-Data Management Course Completion Program.
- Access to live sessions and self-paced videos to refresh concepts.
- Real-life industry training using Big Data, Hadoop, Machine Learning, and much more.
Hadoop Course
Upcoming Batches
Trending Courses
Gen AI
- Introduction to Generative Models
- Generative Adversarial Networks (GANs)
- The Art and Science of Prompt Engineering
- MLOps: Deploying Generative AI Models
Upcoming Class
-1 day 28 Jul 2026
Agentic AI
- Introduction to Agentic AI
- Multi-Agent Setup with LangGraph Context Handling in Graphs
- Performance Benchmarking Advanced Prompt Engineering for Agents
- Agent Behavior Tuning Project and Mock Session
Upcoming Class
9 days 07 Aug 2026
AI in Automation Testing
- Intro to AI & ML in Automation
- Playwright + JS (JavaScript) + API Tesng
- Automaon with Using ChatGPT & Playwright MCP server
- GitHub Copilot, AI Tools & Interview preparation
Upcoming Class
2 days 31 Jul 2026
Cyber Security
- Introduction to cybersecurity
- Cryptography and Secure Communication
- Cloud Computing Architectural Framework
- Security Architectures and Models
Upcoming Class
10 days 08 Aug 2026
Data Science
- Data Science Introduction
- Hadoop and Spark Overview
- Python & Intro to R Programming
- Machine Learning
Upcoming Class
2 days 31 Jul 2026
QA
- Introduction and Software Testing
- Software Test Life Cycle
- Automation Testing and API Testing
- Selenium framework development using Testing
Upcoming Class
2 days 31 Jul 2026
Salesforce Service Cloud
- Industry Knowledge Introduction
- Adoption and Maintenance
- Interaction Channels Introduction
- Integration and Data Management
Upcoming Class
16 days 14 Aug 2026
AWS
- AWS & Fundamentals of Linux
- Amazon Simple Storage Service
- Elastic Compute Cloud
- Databases Overview & Amazon Route 53
Upcoming Class
2 days 31 Jul 2026

 Oct 13, 2022
Oct 13, 2022  119.9k
119.9k



























 Mar 10, 2019
Mar 10, 2019 319.3k
319.3k

Louis Anderson
Hi! Thanks for sharing such an informative blog!
Caden Thomas
In order to gain Hadoop Certification, do I need a degree?
Maximiliano Jackson
Hie, it's a lovely tutorial about Hadoop Distributed File System.
Holden White
It's a very informative tutorial and easy to understand for beginners.
Paxton Harris
How to choose the best data management course from the several courses mentioned above?
Nash Martin
I want to explore a few best courses for career growth, but confused about which one is better, I want to consult a Janbask Training consultant on this.
Bradley Thompso
This is a great opportunity to learn more about HDFS.
Bryan Garcia
Overall a nice blog, all topics are discussed elaborately.
Simon Martinez
I wish to take up this course…. But I want to know what is the duration and whether it’s affordable for me?