
 Sep 19, 2018
Sep 19, 2018  306.7k
306.7k

06
SepDon’t Miss Out : Join our live webinar on AI in Test Automation - Register Now
- Hadoop Blogs -
Today, Big Data is one of the most in-demand frameworks for data science professionals. A vast amount of data is present all over the internet due to social networking sites, so the organizations are using it in various ways and they are using it to resolve their organizational and business demands and needs.  Here, we have discussed big data Hadoop and Spark frameworks so that you can know about both. We will explain to you both the frameworks one by one and in the later section of this blog, we will compare both the frameworks so that you can know and choose the best one that suits your needs completely.
Here, we have discussed big data Hadoop and Spark frameworks so that you can know about both. We will explain to you both the frameworks one by one and in the later section of this blog, we will compare both the frameworks so that you can know and choose the best one that suits your needs completely.
Brief Introduction of Hadoop Framework
Hadoop allows users to store data in the distributed environment so that it can be processed parallel. The two major and essential components of Hadoop are HDFS and YARN: 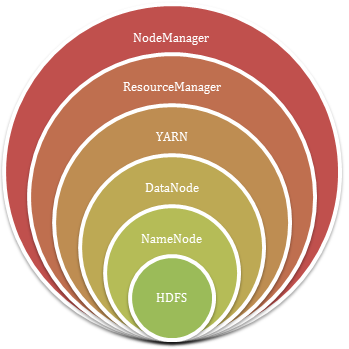
A). HDFS
HDFS is known as Hadoop file system, it creates resource abstraction. It is the core component of Hadoop Ecosystem and can store a vast amount of information that can be structured, unstructured and semi-structured. An abstract layer of entire data is created along with maintenance of various log files and data is stored through an effective file system.
Master-slave architecture is used in HDFS. Two key components of HDFS are NameNode and DataNode, where NameNode is the master node and DataNode is the slave node. Both are discussed below:
B). NameNode
These are known as master daemons that maintain and manage slave or data nodes. Metadata of every file that may include file size, file permission, file hierarchy is recorded. Each and every recorded change to the file system is also maintained here. Like in case of record deletion the change will be recorded in the EditLog of NameNode. The report and status of all nodes are received by the NameNode to get their status and the blocks are stored in these nodes.
C). DataNode
These are slave daemons that are run on every slave machine. Actual data is stored on DataNodes. All read and write requests of the clients are discussed and processed on DataNodes. Block deletion and replication operation is performed on DataNodes and the decision-making process is also being done on these nodes.
Read: Pig Vs Hive: Difference Two Key Components of Hadoop Big Data
D). YARN
All processing activities are performed by YARN like task scheduling or resource allocation. The two major daemons of YARN are ResourceManager and NodeManager that are discussed below: E). Resource Manager The Resource Manager is a cluster level component that runs on the master machine. It is responsible for resource management and application scheduling. Both are performed on top of YARN component.
F). NodeManager
This is a Node level component that is run on every slave machine. Container management and resource utilization monitoring are performed by NodeManager. Node health and log management are also processed by the NodeManager.
This was the introduction to Hadoop framework let’s move to our next blog discussion topic that is Spark Framework:
Brief Introduction of Spark Framework
To process real-time data analytics in the distributed computing environment we can use Spark framework. In-memory computations are performed to increase data-processing speed. Large-scale data processing is being performed by this as other optimizations and in-memory computations are being performed along with other optimizations by the Spark framework. To perform large computations high processing power is required. 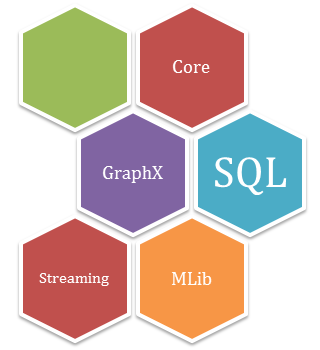
The fundamental data structure of Spark is Resilient Distributed Dataset. This is a collection of immutable objects, each dataset of RDD is divided into logical partitions that may be computed on different cluster nodes. Any type of Java, Python or Scala objects can be contained by the objects along with user-defined classes. Spark has the following components that make it fast and more reliable:
As you know that Spark comes with high libraries that include Spark, R, SQL, Java, and Scala etc. Seamless integration can be increased with the help of standard libraries. Various sets of services can also be integrated with MLib, GraphX, SQL, Data Frames, and service streaming, that increase its capabilities.
Difference between Apache Spark and Hadoop Frameworks
Read: YARN- Empowering The Hadoop Functionalities
Hadoop and Spark can be compared based on the following parameters:
1). Spark vs. Hadoop: Performance
Performance wise Spark is a fast framework as it can perform in-memory processing, Disks can be used to store and process data that fit in memory. Nearly real-time analytics can be delivered by Spark in-memory processing. Therefore, it is used for machine learning, security analytics, the Internet of things sensors and credit card processing systems.
On the other hand, Hadoop was originally set up to collect data from multiple resources without being worried about data source or origination. Even various types of data can be stored and processed in a distributed environment. MapReduce of Hadoop uses batch processing. It was not built for real-time processing, the main idea behind YARN is to perform parallel processing in a distributed environment. Both frameworks process data in a different manner and this is the problem that may be resolved as per your need.
2). Spark vs. Hadoop: Easy to Use
Spark is a user-friendly framework that has the languages like Scala, Java, Python and Spark SQL that is similar to SQL. SQL developers can easily learn SQL. An interactive shell is provided to the developers with which they can perform a query and get an immediate feedback.
Data can be ingested in Hadoop easily either by using shell or by using tools like Flume or Sqoop. YARN can be integrated with multiple tools like Pig or Hive. Here Hive is a data warehousing component that can perform reading, writing and managing of large data sets even in a distributed environment by using SQL –like interface. There are a number of tools that can be integrated with Hadoop.
3). Spark vs. Hadoop: Costs Spark and Hadoop both are open source frameworks so the user does not have to pay any cost to use and install the software. Here, the cost that the user has to pay is only for the infrastructure. The products are designed in the way so that they can be used and run on any commodity hardware even with low TCO.
In Hadoop, we may need faster disks with lots of disk space as in this storage and processing both are disk-based. To distribute the disk I/O Hadoop requires multiple systems.
In Apache Spark, we may require much memory as it follows in-memory processing and so can deal with standard speed and the number of disks. Spark may require a large amount of RAM and it incurs more cost. If you will compare both the technologies then you will notice that Spark technology reduces the number of required systems. Fewer systems are needed that may cost much, and here the cost per unit is reduced.
Read: Hadoop Developer And Architect: Roles and Responsibilities
4). Spark vs. Hadoop: Data Processing
There are, mainly two types of data processing one is batch processing and other is stream processing. Here, YARN is a batch-processing framework when many jobs are submitted to YARN. When a job is submitted to YARN, the data is read from the cluster and then operations are performed after that the results are written back to the clusters. Then the data is read and updates and next operations are performed.
Spark also performs similar operations, it uses in0-memory processing and steps are being optimized. Same data can be visualized as GraphX and collections both. Graphs can also be joined and transformed as and when required with RDDs.
5). Spark vs. Hadoop: Fault Tolerance
Fault tolerance is provided by both Spark and Hadoop but they have different approaches. HDFS and YARN have master daemons that may be NameNode and ResourceManager respectively in the systems and slave daemons that are DataNode and NodeManager in both Hadoop and Spark system respectively.
In case, when any slave daemon fails master daemon re-schedule or re-distribute all of the in-process or pending operations. The method is effective but can increase the completion time for a single failure or operation.
Final Words
We can say that Hadoop and Spark are not competing with each other in fact they are complementing each other. Hadoop uses a commodity system to control various datasets. Spark provides real-time and in-memory processing to support the real-time systems. Even when both of the systems are used together, they can be taken as the best solution for anyone.
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Search Posts
Related Posts
Receive Latest Materials and Offers on Hadoop Course
Interviews









 Jul 09, 2024
Jul 09, 2024 483.1k
483.1k

 483.1k
483.1k