
 Oct 31, 2017
Oct 31, 2017  670.1k
670.1k

27
JunMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Hadoop Blogs -
Apache Hadoop is an open source framework, which is used to store and process a huge amount of unstructured data in the distributed environment. Conceptually the unstructured data is distributed across a number of clusters and then there it is stored and processed. Means in Hadoop the unstructured data is processed in a concurrent manner in the distributed environment. Moreover, in Hadoop distributed system the data processing is not interrupted if one or several server or cluster fails, therefore, Hadoop provides a stable and robust data processing environment. This blog discusses about Hadoop Ecosystem architecture and its components.
Hadoop is mainly a framework and Hadoop ecosystem includes a set of official Apache open source projects and a number of commercial tools and solutions. Spark, Hive, Oozie, Pig, and Squoop are few of the popular open source tools, while the commercial tools are mainly provided by the vendors Cloudera, Hortonworks and MapR. Apart from this, a large number of Hadoop productions, maintenance, and development tools are also available from various vendors. These tools or solutions support one or two core elements of the Apache Hadoop system, which are known as HDFS, YARN, MapReduce, Common.
Apache Hadoop is used to process ahuge amount of data. The architecture of Apache Hadoop consists of various technologies and Hadoop components through which even the complex data problems can be solved easily. The following image represents the architecture of Hadoop Ecosystem: 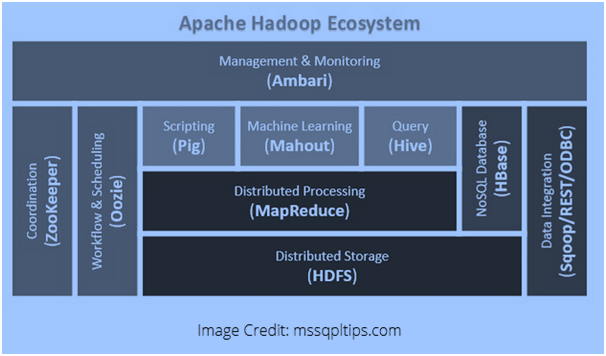 Hadoop architecture is based on master-slave design. In Hadoop when the data size is large the data files are stored on multiple servers and then the mapping is done to reduce further operations. Each server works as a node, so each node of the map has the computing power and are not dump like disk drives. The master-slave architecture is followed by the data processing in the Hadoop system, which looks like the following figure:
Hadoop architecture is based on master-slave design. In Hadoop when the data size is large the data files are stored on multiple servers and then the mapping is done to reduce further operations. Each server works as a node, so each node of the map has the computing power and are not dump like disk drives. The master-slave architecture is followed by the data processing in the Hadoop system, which looks like the following figure: 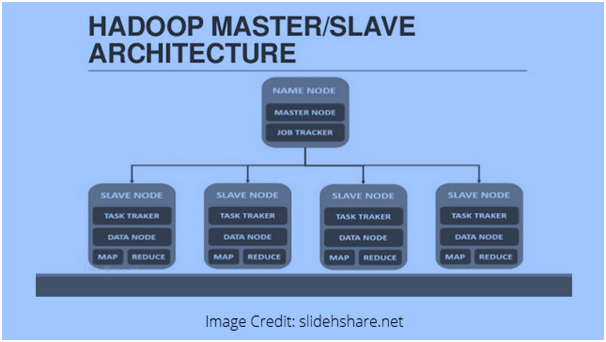 Following is the description of each component of this image:
Following is the description of each component of this image:
Namenode: It controls operation of data
Datanode: Datanodes writes the data to local storage. To store all data at a single place is not always recommended, as it may cause loss of data in case of outage situation.
Read: Your Complete Guide to Apache Hive Data Models
Task tracker: They accept tasks assigned to the slave node
Map:It takes data from a stream and each line is processed after splitting it into various fields
Reduce: Here the fields, obtained through Map are grouped together or concatenated with each other
The key components of Hadoop file system include following:
This is the core component of Hadoop Ecosystem and it can store a huge amount of structured, unstructured and semi-structured data. It can create an abstract layer of the entire data and a log file of data of various nodes can also be maintained and stored through this file system. Name Node and Data Node are two key components of HDFS [caption id="attachment_3455" align="aligncenter" width="516"] image source: wingnity.com[/caption] Here the Name Node stores meta data instead of original data and require less storage and computational resources. All data is stored in the Data Nodes and require more storage resources and it requires commodity hardware like laptops or desktops, which makes the Hadoop solution costlier.
image source: wingnity.com[/caption] Here the Name Node stores meta data instead of original data and require less storage and computational resources. All data is stored in the Data Nodes and require more storage resources and it requires commodity hardware like laptops or desktops, which makes the Hadoop solution costlier.
Read: What is Spark? Apache Spark Tutorials Guide for Beginner
YARN or Yet Another Resource Navigator is like the brain of the Hadoop ecosystem and all processing is performed right here, which may include resource allocation, job scheduling, and activity processing. The two major components of YARN are Node Manager and Resource Manager. Here the Resource Manager passes the parts of requests to the appropriate Node Manager. Every Data Node has a Node Manager, which is responsible for task execution. It has following architecture: 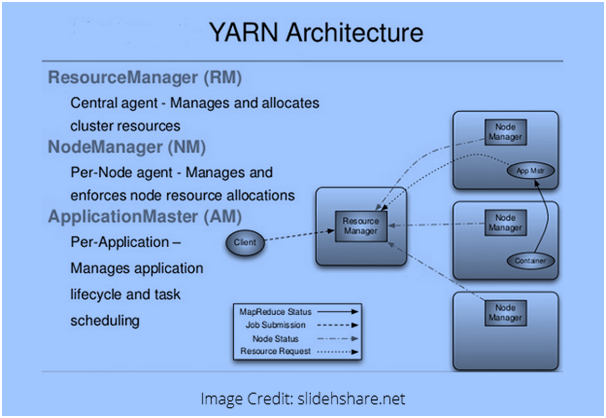 YARN is a dynamic resource utilization and the user can run various Hadoop applications, using YARN framework without increasing workloads. It offers high sociability, agility, new and unique programming models and improved utilization of the clusters.
YARN is a dynamic resource utilization and the user can run various Hadoop applications, using YARN framework without increasing workloads. It offers high sociability, agility, new and unique programming models and improved utilization of the clusters.
MapReduce is a combination of two operations, named as Map and Reduce.It also consists of core processing components and helps to write the large data sets using parallel and distributed algorithms inside the Hadoop environment. Map and Reduce are basically two functions, which are defined as: Map function performs grouping, sorting and filtering operations, while Reduce function summarizes and aggregates the result, produced by Map function. The result of these two functions is a Key-> Value pair, where the keys are mapped to the values to reduce the processing. Map Reduce framework of Hadoop is based on YARN architecture, which supports parallel processing of large data sets. The basic concept behind MapReduce is that the “Map” sends a query to various datanodes for processing and “Reduce” collects the result of these queries and output a single value 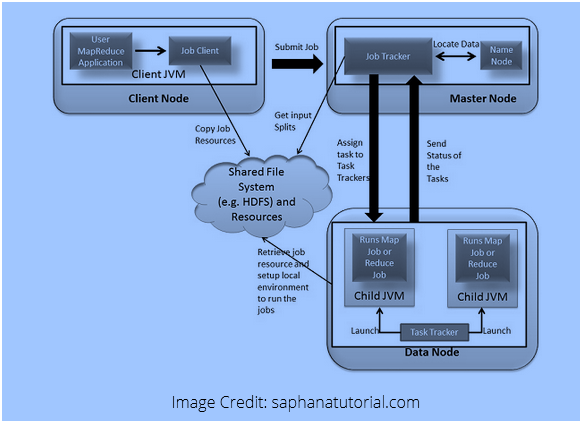 Here the Job Tracker and Task Tracker are two daemons, which tackles the task of job tracking in MapReduce processing.
Here the Job Tracker and Task Tracker are two daemons, which tackles the task of job tracking in MapReduce processing.
Apache PIG is a procedural language, which is used for parallel processing applications to process large data sets in Hadoop environment and this language is an alternative for the Java programming. Pig includes two components Pig Latin and the Pig run time, just like Java and JVM. Pig Latin has SQL like commands. Non-programmers can also use Pig Latin as it involves very less coding and SQL like commands. At the back-end of Pig Latin, the MapReduce job executes. The compiler converts the Latin into MapReduce and produces sequential job sets, which is called an abstraction. It is usually used for complex use-cases and require multiple data operations and is a processing language rather than a query language. Through Pig the applications for sorting and aggregation can be developed. Through this customizable platform, the user can write his own application. It supports all popular programming languages, including Ruby, Python, and Java. For those who love to write applications in these programming languages, it can be the best option.
HBase is an open source and non-relational or NoSQL database. It supports all data types and so can handle any data type inside a Hadoop system. It runs on HDFS and is just like Google’s BigTable, which is also a distributed storage system and can support large data sets. HBase itself is written in Java and its applications are written using REST, Thrift APIs and Avro. HBase is designed to solve the problems, where a small amount of data or information is to be searched in a huge amount of data or database. This NoSQL database was not designed to handle transnational or relational database. Instead, is designed to handle non-database related information or data. It does not support SQL queries, however, the SQL queries can run inside HBase using another tool from the Apache vendor like Hive, it can run inside HBase and can perform database operations. HBase is designed to store structured data, which may have billions of rows and columns. A large number of messaging applications like Facebook are designed using this technology.It has ODBC and JDBC drivers as well.
Mahout is used for machine learning and provides the environment for developing the machine learning applications. Through this, we can design self-learning machines, which can be used for explicit programming. Moreover, such machines can learn by the past experiences, user behavior and data patterns. Just like artificial intelligence it can learn from the past experience and take the decisions as well. Mahout can perform clustering, filtering and collaboration operations, the operations which can be performed by Mahout are discussed below:
Read: What Is The Hadoop Cluster? How Does It Work?
To manage the clusters, one can use Zookeeper, it is also known as the king of coordination, which can provide reliable, fast and organized operational services for the Hadoop clusters. Zookeeper can provide distributed configuration service, synchronization service and the feature of naming registry for the distributed environment. When Zookeeper was not there, the complete process of task coordination was quite difficult and time-consuming. The synchronization process was also problematic at the time of configuration and the changes in the configuration were also difficult. Zookeeper provides a speedy and manageable environment and saved a lot of time by performing grouping, maintenance, naming and synchronization operations in less time. It offers a powerful solution for the Hadoop use cases. Many big brands, like eBay, Yahoo and Rackspace are using Zookeeper for many of their use-cases. Therefore Zookeeper has become an important Hadoop tool.
Job scheduling is an important and unavoidable process for Hadoop system. Apache Oozie performs the job scheduling and works like an alarm and clock service inside the Hadoop Ecosystem. Oozie can schedule the Hadoop jobs and bind them together so that logically they can work together.The two kinds of jobs, which mainly Oozie performs, are:
Ambari is a project of Apache Software Foundation and it can make the Hadoop ecosystem more manageable. This project of Apache includes managing, monitoring, and provisioning of the Hadoop clusters. It is a web-based tool and supports HDFS, MapReduce, Hadoop, HCatalog, HBase, Hive, Oozie, Zookeeper, and Pig. Ambari wizard is very much helpful and provides a step-by-step set of instructions to install Hadoop ecosystem services and a metric alert framework to monitor the health status of Hadoop clusters. Following are the main services of Hadoop:
Hadoop is a successful ecosystem and the credit goes to its developer’s community. Many big companies like Google, Yahoo, Facebook, etc. are using Hadoop and have increased its capabilities as well. While learning Hadoop knowledge of just one or two tools may not be sufficient. It is important to learn all Hadoop components so that a complete solution can be obtained. Hadoop ecosystem involves a number of tools and day by day the new tools are also developed by the Hadoop experts. It has become an integral part of the organizations, which are involved in huge data processing. Haddop future is much bright in coming years and it can be the best IT course from acareer perspective as well.
Read: ELK vs. Splunk vs. Sumo Logic – Demystifying the Data Management Tools
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Interviews












 Sep 10, 2019
Sep 10, 2019 8.1k
8.1k
