 Jun 06, 2023
Jun 06, 2023  4.4k
4.4k

06
SepIndependence Day Deal : Upto 25% off on live classes - SCHEDULE CALL
- Hadoop Blogs -
In big data, Hadoop has emerged as a robust framework for processing and analyzing large volumes of structured and unstructured data. With its distributed computing model and scalability, Hadoop has become a go-to solution for organizations dealing with massive data sets. However, to effectively leverage the capabilities of Hadoop, various analytics tools have been developed to enhance data processing, visualization, and analysis.
In this blog post, we will explore the top Hadoop analytics tools for big data that are widely used in projects, covering their key features and use cases. But before going there, let's dive into the basics.
Hadoop is an open-source framework for processing and analyzing large volumes of data in a distributed computing environment. Apache Software Foundation initially developed it and has become a popular choice for big data analytics, and Hadoop developers widely use its Hadoop big data tools.
In big data analytics, Hadoop provides a scalable and fault-tolerant infrastructure that allows processing and analyzing massive datasets across clusters of commodity hardware. It comprises two main components: the Hadoop Distributed File System (HDFS) and the MapReduce processing framework.
1. Hadoop Distributed File System (HDFS): HDFS is a distributed file system that stores data across multiple machines in a cluster. It breaks large datasets into smaller blocks and distributes them across different nodes, ensuring high availability and fault tolerance. In addition, this distributed storage enables parallel processing of data across the cluster.
2. MapReduce: MapReduce is a programming model and processing framework that allows parallel distributed processing of large datasets. It divides data processing tasks into two main stages: the map stage and the reduce stage. Data is processed in parallel across multiple nodes in the map stage, and in the lower setting, the results are combined to generate the final output.
Hadoop plays a crucial role in Big Data analytics by providing powerful Hadoop analytics tools. These tools enable efficient processing, storage, and analysis of large and diverse data sets, empowering businesses to uncover valuable insights and make data-driven decisions. Discover the transformative potential of Hadoop analytics tools for your business.
Hadoop provides several benefits for big data analytics:
Hadoop Big Data analytics continues to be a necessary technology in 2023 for several reasons:
In summary, the ever-increasing data volume, diverse data types, real-time analytics needs, cost efficiency, advanced analytics capabilities, data security requirements, and cloud adoption make Hadoop Big Data analytics and Hadoop analytics tools for big data a necessary technology in 2023 and beyond. It empowers organizations to derive insights, drive innovation, and remain competitive in the data-driven era. It also establishes an excellent Hadoop developer career path.
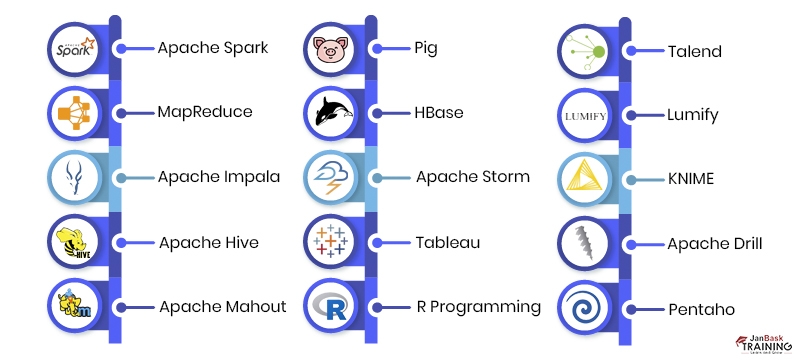
Here are a few examples of the Hadoop analytics tools commonly used by data analysts. The Hadoop ecosystem offers a rich set of big data analytics tools and frameworks that cater to various data analysis requirements and enable data analysts to extract insights from Big Data efficiently.
The following is a list of the leading Hadoop analytics tools for big data:
Apache Spark is a widely used analytics engine that is open-source and capable of handling big data and machine learning tasks.
The characteristics of Apache Spark are as follows:
MapReduce is a programming model and software framework for processing large amounts of data in a distributed computing environment. It involves two main phases: the map phase, which requires processing and transforming data into key-value pairs, and the reduce phase, which consists in aggregating and summarizing the key-value pairs to produce the final output.
MapReduce is commonly used in big data applications and is supported by various programming languages and distributed computing platforms.
The MapReduce framework serves as the core of the Hadoop distributed computing system. The software mentioned above framework is designed for composing applications that execute parallel processing of voluminous datasets across numerous nodes on the Hadoop cluster.
Hadoop partitions the MapReduce job of the client into multiple autonomous tasks that execute concurrently to achieve high throughput.
The MapReduce framework operates through a two-phase process, namely the Map and Reduce phases. Both phases receive key-value pairs as input.
The characteristics of Hadoop MapReduce are as follows:
Check out MapReduce interview questions to enhance your learning curve!
Apache Impala is an open-source distributed SQL query engine that allows users to process large datasets stored in Hadoop Distributed File System (HDFS) or Apache HBase in real time.
Apache Impala is a software application that utilizes open-source technology to address the slow performance issue in Apache Hive. This database is designed specifically for analytical purposes and integrated with the Apache Hadoop framework.
Apache Impala enables real-time querying of data stored in either the Hadoop Distributed File System (HDFS) or HBase.Impala leverages identical metadata, ODBC driver, SQL syntax, and user interface as Apache Hive, delivering a consistent and recognizable framework for executing batch or real-time queries. Integrating Apache Impala with Apache Hadoop and other prominent BI tools can furnish a cost-effective analytics platform.
The characteristics of Impala are as follows:
Apache Hive is an open-source data warehousing tool that facilitates querying and managing large datasets stored in distributed storage systems, such as Hadoop Distributed File System (HDFS). It provides a SQL-like interface to interact with data and supports various formats, including structured and semi-structured data. Hive uses a query language called HiveQL, which translates SQL-like queries into MapReduce jobs that can be executed on a Hadoop cluster. It also supports user-defined functions (UDFs) and custom MapReduce scripts for advanced data processing.
Apache Hive is a software application written in Java that serves as a data warehousing solution. Facebook developed it to facilitate the analysis and processing of large datasets.
Hive leverages HQL (Hive Query Language), which resembles SQL, to generate MapReduce jobs to process vast data. The system assists developers and analysts in querying and examining large datasets using SQL-like queries (HQL), eliminating the need to create intricate MapReduce jobs.
Users can access the Apache Hive using the command line tool (Beeline shell) and JDBC driver.
The Apache Hive platform can support client applications developed in various programming languages such as Python, Java, PHP, Ruby, and C++.
The system typically employs Relational Database Management Systems (RDBMS) to store metadata. This results in a notable reduction in the duration required for conducting semantic checks.
The implementation of Hive Partitioning and Bucketing can enhance the efficiency of query processing.
Features of Apache Hive comprise of:
Apache Mahout is an open-source machine-learning library that provides a framework for building scalable and distributed machine-learning algorithms.
Apache Mahout is an open-source framework with the Hadoop infrastructure to handle massive data.
The term "Mahout" is etymologically derived from the Hindi language, specifically from the word "Mahavat," which pertains to an individual who rides and manages an elephant.
Apache Mahout is a software framework that executes algorithms utilizing the Hadoop infrastructure, hence the name Mahout.
Apache Mahout can be utilized to deploy scalable machine-learning algorithms on Hadoop through the MapReduce paradigm.
The Apache Mahout platform is not limited to Hadoop-based implementation. It can execute algorithms in standalone mode.
Apache Mahout is a software framework that incorporates prevalent machine learning algorithms, including but not limited to Classification, Clustering, Recommendation, and Collaborative filtering.
Mahout is a software library designed to perform well in distributed environments. This is because its algorithms are built on top of Hadoop. The system leverages the Hadoop library for cloud-based scalability.
Mahout provides a pre-built framework for developers to conduct data mining operations on extensive datasets.
Apache Mahout features comprise
Pig is a software tool created by Yahoo to simplify MapReduce job execution through an alternative approach.
The platform facilitates the utilization of Pig Latin, a script-based language developed explicitly for the Pig framework that operates on the Pig runtime.
Pig Latin is a programming language that utilizes SQL-like syntax and is compiled into MapReduce programs by the compiler.
The system operates by initializing the requisite commands and data sources.
Subsequently, a series of operations are executed, including but not limited to sorting, filtering, and joining.
Finally, in accordance with the specified criteria, the outcomes are either displayed on the monitor or saved to the Hadoop Distributed File System (HDFS).
The characteristics of a Pig:
HBase is a column-oriented NoSQL database management system that runs on top of the Hadoop Distributed File System (HDFS). It is designed to handle large amounts of structured data and provides real-time read/write access. HBase is a distributed NoSQL database that is open-source and designed to store sparse data in tables that can consist of billions of rows and columns.
The software is developed using Java and designed based on Google's Big Table architecture.
HBase is a column-oriented NoSQL database that is utilized for efficient retrieval and querying of sparse data sets that are distributed across a large number of commodity servers. It is beneficial in scenarios where there is a requirement to search or retrieve a limited amount of data from massive data sets.
In the scenario where a vast amount of customer emails are present, and it is necessary to extract the name of the customer who has utilized the term "replace" in their email correspondence, HBase is employed.
The characteristics of HBase include:
Apache Storm is a distributed computational framework that operates in real-time. It is open-source software written in Clojure and Java programming languages.
Apache Storm enables the dependable processing of unbounded data streams, which refer to data that continues to grow without a predetermined endpoint.
Apache Storm is a distributed real-time computation system that can be utilized for various purposes, such as real-time analytics, continuous computation, online machine learning, ETL, and other related applications.
Apache Storm is utilized by various companies such as Yahoo, Alibaba, Groupon, Twitter, and Spotify.
Apache Storm possesses the following features:
Tableau is a robust software application utilized in the Business Intelligence and analytics sector for data visualization and analysis.
This tool effectively converts unprocessed data into an understandable format, requiring no technical expertise or coding proficiency.
Tableau facilitates live dataset manipulation, enabling users to dedicate additional time to data analysis while providing real-time analysis capabilities.
The system provides an expedited data analysis procedure that yields interactive dashboards and worksheets as visual representations. The tool operates in tandem with other Big Data tools.
R is a freely available programming language that is open-source and has been developed using C and Fortran programming languages.
The software enables statistical computing and graphical libraries. In addition, the software is designed to be compatible with various operating systems, making it platform-agnostic.
R comprises a comprehensive set of graphical libraries, including plotly, ggplotly, and others, designed to create visually attractive and sophisticated visualizations. The primary benefit of R lies in the extensive package ecosystem it offers.
Talend is a data integration platform that enables organizations to access, transform, and integrate data from various sources. It provides multiple tools and features for data management, including data quality, governance, and preparation. Talend supports multiple data formats and can be used for batch and real-time data processing. It also offers cloud-based solutions for data integration and management.
Talend is a software platform that utilizes open-source technology to streamline and automate the integration of large data sets.
The company offers a range of software and services that cater to data integration, big data, data management, data quality, and cloud storage.
Using real-time data aids businesses in making informed decisions and transitioning towards a more data-driven approach.
Talend provides a range of commercial offerings, including Talend Big Data, Talend Data Quality, Talend Data Integration, Talend Data Preparation, Talend Cloud, and additional products.
Talend is utilized by various corporations such as Groupon, Lenovo, and others.
Features of Talend are:
Lumify is a product or technology that needs to be further specified.
Lumify is a platform that facilitates the creation of actionable intelligence by enabling big data fusion, analysis, and visualization. It is an open-source solution.
Lumify offers a range of analytical tools, such as full-text faceted search, 2D and 3D graph visualizations, interactive geospatial views, dynamic histograms, and real-time collaborative workspaces, to enable users to uncover intricate connections and investigate relationships within their data.
Lumify boasts a highly flexible infrastructure that integrates novel analytical tools seamlessly in the background, facilitating change monitoring and aiding analysts.
Features & Functionalities of Lumify:
KNIME is an open-source data analytics platform that allows users to manipulate, analyze, and model data through a graphical interface.
KNIME is an acronym that stands for Konstanz Information Miner.
The aforementioned is a scalable data analytics platform that is open-source in nature. It facilitates extensive data analysis, enterprise reporting, data mining, text mining, research, and business intelligence.
The KNIME platform facilitates data analysis, manipulation, and modeling through visual programming techniques. As a result, KNIME can serve as a viable substitute for SAS.
Several corporations, such as Comcast, Johnson & Johnson, and Canadian Tire, utilize KNIME.
KNIME Features and Functionalities
Apache Drill is a distributed query engine that operates with low latency. Google Dremel inspires its design.
Apache Drill is a software application that enables users to perform data exploration, visualization, and querying on extensive datasets utilizing MapReduce or ETL without the need to adhere to a specific schema.
The system is engineered to achieve scalability to accommodate thousands of nodes and execute queries on petabytes of data.
Apache Drill enables querying of data by specifying the path in a SQL query to a Hadoop directory, NoSQL database, or Amazon S3 bucket.
Apache Drill eliminates the need for developers to engage in coding or application building.
Features of Apache Drill are:
Pentaho is a business intelligence software platform that provides tools for data integration, analytics, and reporting.
Pentaho is a software application designed to transform large volumes of data into valuable insights.
The platform is a comprehensive solution encompassing data integration, orchestration, and business analytics capabilities. It facilitates many tasks, including significant data aggregation, preparation, integration, analysis, prediction, and interactive visualization.
Features and Functionalities of Pentaho:
Harnessing the power of data analytics has become a vital aspect of business success in the era of Big Data. Data volume, variety, and velocity growth require robust tools and frameworks to unlock valuable insights. Hadoop Big Data tools have emerged as a game-changer in this landscape, offering scalability, cost-efficiency, and flexibility.
Data analysts can efficiently process, analyze, and derive meaningful insights from vast and diverse datasets through tools like Apache Hive, Pig, Spark, HBase, Mahout, Zeppelin, and Flink. These tools enable organizations to uncover hidden patterns, make data-driven decisions, and gain a competitive edge.
The ability of Hadoop Big Data tools to handle real-time analytics, support advanced machine learning algorithms, ensure data security, and adapt to cloud environments further solidifies their significance in 2023 and beyond. By leveraging these tools, businesses can navigate the complexities of Big Data analytics, explore new avenues of growth, and drive innovation.
In the age of data-driven decision-making, embracing Hadoop data analytics tools is no longer a luxury but a necessity. Organizations that use these tools' power can harness their data's true potential, gaining actionable insights and staying ahead in an increasingly competitive landscape. With Hadoop analytics tools, businesses can embark on a transformative journey, turning data into a valuable asset that drives success in the digital era. And professionals who wish to learn these tools and technology can see huge differences in their career paths, ofcourse learning them is not a cup of cake, it takes time but surely adds up to one's craft and an important skill to one’s resume.
Q1. What are Hadoop data analytics tools?
Ans:- Hadoop Big Data tools are software frameworks and applications that are specifically designed to analyze and process large volumes of data stored in the Hadoop ecosystem. These tools provide functionalities such as data querying, data transformation, data visualization, machine learning, and advanced analytics to extract valuable insights from Big Data.
Q2. Why should I consider Big Data Hadoop training?
Ans:- Big Data Hadoop training is highly beneficial for individuals who want to build a career in the field of Big Data analytics. It equips you with the necessary skills and knowledge to tackle complex data challenges, leverage Hadoop's capabilities, and extract valuable insights from vast data sets. With the increasing demand for Big Data professionals, Hadoop training can enhance your employability and open doors to lucrative career opportunities.
Q3. Where can I find Big Data Hadoop training and certification programs?
Ans:- Big Data Hadoop training and certification programs are offered by various online learning platforms, universities, training institutes, and technology vendors. You can explore reputable platforms and institutions that provide comprehensive and up-to-date training courses tailored to your needs. It is advisable to research and choose programs that align with your career goals and offer recognized certifications.
Q4. How is Apache Spark used as a Big Data Analytics tools?
Ans:- Apache Spark is a fast and distributed computing framework that provides in-memory processing capabilities. It offers various APIs, including Spark SQL, Spark Streaming, and MLlib, that enable data analysts to perform advanced analytics tasks such as data exploration, machine learning, and real-time processing. Spark's in-memory processing significantly speeds up data analysis compared to traditional disk-based processing.
Q5. Which industries can benefit from harnessing Hadoop analytics tools for Big Data?
Ans:- Virtually every industry can benefit from harnessing Hadoop analytics tools for Big Data. Industries such as finance, healthcare, retail, telecommunications, manufacturing, and e-commerce can leverage these tools to gain insights from their large and diverse datasets. From fraud detection and personalized marketing to supply chain optimization and predictive maintenance, the applications of Hadoop data analytics tools are vast and varied.
Q6. How do Hadoop analytics tools complement traditional data analytics methods?
Ans:- Hadoop Big Data tools complement traditional data analytics methods by providing a scalable and efficient solution for processing and analyzing large volumes of data. Traditional methods often struggle to handle the complexity and scale of Big Data, while Hadoop analytics tools, with their distributed computing capabilities, enable organizations to tackle these challenges effectively.
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Interviews









 Oct 04, 2017
Oct 04, 2017 345.8k
345.8k
