 Aug 09, 2024
Aug 09, 2024  254.8k
254.8k

18
JulInternational Womens Day : Flat 30% off on live classes + 2 free self-paced courses - SCHEDULE CALL
- Hadoop Blogs -
Today Big Data is getting popular among many organizations. Hue is related to Big Data Hadoop and in this blog; we will understand the basics of Hue and the way in which it has been used with Big Data Ecosystem. When it comes to Big Data then organizations ask their developers to provide quick and profitable solutions.
Here the first word and tool that strikes in their mind are Apache Hadoop. The software developers may have an idea about Hadoop, but when it will be about Hadoop implementation then their expectations may be proven different as compared to the reality.

Hadoop is an ecosystem not a single tool. Hadoop includes a number of components that can crack the data challenges for the variably sized company medium, small, or large. If any developer is planning to learn Hadoop then he must be aware and familiar with Hadoop components too.
Hadoop is basically a collection of many components that work together to provide better and improved functionality to the system. Every day new tools are launched in the market and existing are getting improved to provide better performance to the Hadoop ecosystem.
Hadoop Hue is an open source user experience or user interface for Hadoop components. The user can access Hue right from within the browser and it enhances the productivity of Hadoop developers. This is developed by the Cloudera and is an open source project. Through Hue, the user can interact with HDFS and MapReduce applications. Users do not have to use command line interface to use Hadoop ecosystem if he will use Hue.
A lot of features are available in Hue apart from just a web interface that it provides to the Hadoop developers. Hue provides the following listed features due to which it is getting a popular tool for the Hadoop developers:
Above-mentioned reasons make Hue a foremost choice for the Hadoop developers and are used in Hadoop cluster installation. All basic Hadoop features can be accessed through Hue and people who are not familiar with the command line interface can use Hue and access all of its functionalities. Following image shows the user interface of Hue: 
Hue in itself has many components through which user can take the advantage of Hadoop ecosystem and implement it properly:

While working with Hadoop Ecosystem one of the most important factors is the ability to access the HDFS Browser through which user can interact with the HDFS files in an interactive manner. He provides such HDFS interface through which all required operations can be performed on HDFS. If you do not want to work through command line interface then it can be of much help for you.
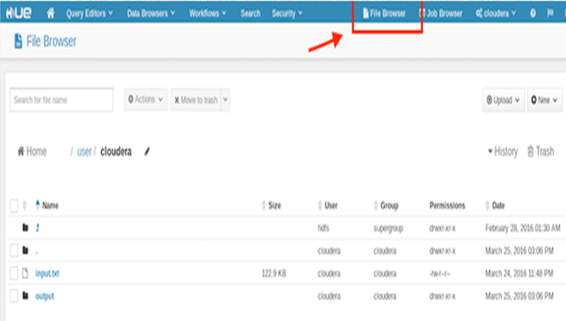
If you are using Hue interface then click on the “File Browser” that is present in the top-right position. A file browser will be opened through this link. Following image shows this interface. For the current or default path, it will enlist all of the files along with file properties. The user can even either delete, download or upload new files from here:
Hadoop ecosystems consist of many jobs and sometimes developers may need to know that which job is currently running on the Hadoop cluster and which job has been successfully completed and which has errors. Through Job browser, you can access all of the job-related information right from inside the browser. For this there is a button in Hue that can enlist the number of jobs and their status. Following image shows the job browser screen of Hue:

Above image shows MapReduce type job that has been finished successfully. Along with Job ID, Application Type, Name, Status and Duration of the job is also listed with its time of submission and the name of the user that have. To show the job status, four color codes are used that are listed below:
If the user needs to access more information about any job then by clicking the job or Job ID user can access the job details. Moreover, another job-related information like in above case two subtasks were also performed for the above-listed job one is MapReduce and other is Reduce that is shown in the below image:

So recent tasks for the job are displayed and that is MapReduce and Reduce. Here other job-related properties like metadata can also be accessed easily from the same platform. Information like the user who has submitted the job, Total execution duration of this job, the time when it was started and ended along with their temporary storage paths and tablespaces, etc can also be listed and checked through Hue job interface like shown in the below image:

Now we will see the Hive Query Editor. Hive query editor allows us to write SQL Hive queries right inside the editor and the result can also be shown in the editor. Hue editor makes the querying data easier and quicker. The user can write SQL like queries and execution of these queries can produce MapReduce job by processing data and the job browser can be checked from the browser even when it is in running state. Query result can be shown in the browser. A bar chart like result has been shown in the following window:

Such charts that are produced as the result of any query can easily be saved to the disk or can be exported to any other file easily. Not only bar chart eve you can produce many other types of charts like a pie chart, line chart and others.
All of the available datastore tables can be displayed, exported and imported through Database browser. Following image shows the database tables. When you will click on any particular table then you can also access the desired information of that table. Right from within the user interface you can view the data and access it. Table data can be visualized and checked from there and you can check the column of any particular table along with its names. Following image shows the table information or metadata of the table:

From this interface, we can browse the data and even check the actual file location of the current table.
Hue also provides the interface for Oozie workflow. All of the past and previous workflows of Hadoop cluster can be checked through this workflow interface. Again, three colors can be used to check the workflow status:
Following image shows an example of this:

New workflows can also be designed through this interface. An inbuilt Oozie editor is there that can be used to create new workflows just by using drag and drop interface.
Here, we have given the introduction to Hadoop along with a detailed description of Hue tools. It provides an easy to use user interface that can be used to process all steps of Hadoop ecosystem. You can access all Hadoop services through Hue interface. With this Hue Hadoop Tutorial guide in detail, you can start your basic work and get enough knowledge to use Hue platform quickly
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Interviews









 Oct 13, 2022
Oct 13, 2022 118.5k
118.5k
