Introduction
Machine learning algorithms are the building blocks of artificial intelligence, allowing computers to learn from data and make predictions or judgements without the need for explicit programming. Based on their goal and approach, these algorithms can be classified into several types. Understanding these categories is critical for grasping the big picture of artificial intelligence and creating efficient machine learning algorithms.
This blog will look at many types of machine learning algorithms, such as supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. We will also look at the common algorithms found in each kind and how they might be used in practice.
Before diving in the algorithms of Machine learning, let us know about machine learning.
What Are Machine Learning Algorithms?
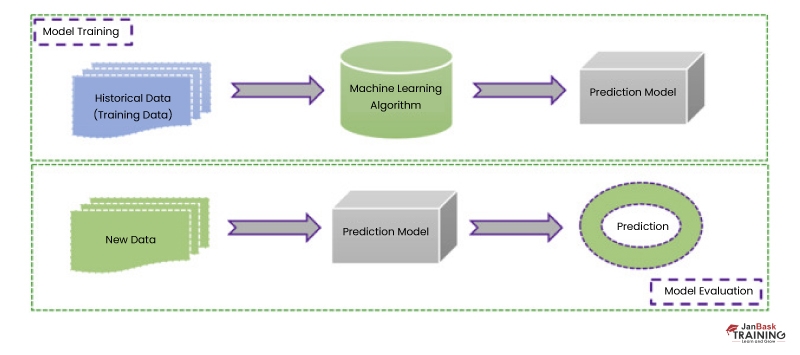
A machine learning algorithm is a mathematical model or rule that explores patterns in data and makes predictions or decisions based on those patterns. These algorithms are trained on a dataset to recognize patterns and correlations between input variables and output variables.

Once trained, the system can make predictions based on new data. The algorithm's performance is determined by the quality of the data, the algorithm employed, and the hyper parameters selected. Different algorithms have different strengths and limitations, and the method chosen is determined by the nature of the problem being solved and the data being used.
Some examples of machine learning algorithms are:
- Supervised Learning is a sort of Machine Learning method in which the model is trained on labeled data to create predictions or classifications. This algorithm is frequently used for picture identification, spam filtering, and sentiment analysis.
- Unsupervised Learning is another method that involves training models using unlabeled data to uncover patterns or groupings within the data. This approach is useful for grouping, detecting anomalies, and segmenting markets.
- Reinforcement Learning is a form of Machine Learning algorithm that learns by interacting with an environment in a trial-and-error fashion. It is widely used in robotics, gaming, and self-driving vehicle navigation.
- There are also Semi-Supervised Learning algorithms, which include supervised and unsupervised learning features. To boost prediction accuracy, these algorithms use both labeled and unlabeled data.
- Finally, Deep Learning algorithms are inspired by the structure and function of neural networks in the human brain. Image identification, natural language processing, and speech synthesis are just a few of the applications where Deep Learning has proven to be quite effective.
Different Types Of ML Algorithms
Algorithms are used in machine learning to create models that can make predictions or classify data. Depending on the sort of problem we wish to answer, there are various types of machine learning algorithms. Supervised learning, unsupervised learning, semi-supervised learning, reinforcement learning, and deep learning are the various forms. There are various algorithms within each of these categories that employ different strategies to output predictions or classify data. The algorithm chosen is determined by the type of problem, the nature of the data, and the desired conclusion.
1. Linear Regression
Linear regression is a basic yet powerful machine learning technique for predicting numerical values. It is a type of supervised learning in which we attempt to construct a linear relationship between independent variables or features and an output variable known as the dependent variable or target. The purpose of linear regression is to determine the best-fit line that minimizes the difference between predicted and actual target variable values.
The optimal values for the slope and intercept coefficients are used to determine this line. We utilize a training dataset that contains both the input variables and the matching target values to train a linear regression model. The programme uses this data to learn how to estimate the coefficients of the line equation. Once trained, the model may predict the target variable for new, previously unknown input data.
This is accomplished by multiplying the input variables by their coefficients and combining them along with the intercept. The outcome provides us with the projected value. It is vital to remember that linear regression makes several assumptions, including linearity, error independence, and homoscedasticity. Violations of these assumptions can have an impact on the accuracy and dependability of the results.
Overall, linear regression is a fundamental method in machine learning that may be used to develop more complex models in fields such as finance, economics, and health.
2. Logistic Regression
Logistic regression is a machine learning approach that is commonly used for binary classification applications. Despite its name, it is a regression technique that estimates the likelihood of a binary result based on input data. The purpose of logistic regression is to develop a function that can distinguish the two groups by estimating the chances that each occurrence belongs to a specific class.
It transforms the output with a sigmoid or logistic function into a probability between 0 and 1, allowing us to understand the prediction. To determine the ideal parameters that best suit the data, the programme performs maximum likelihood estimation. It minimizes the logistic loss function, often known as the cross-entropy loss, during training by employing techniques such as gradient descent.
There are various advantages of using logistic regression. It is computationally efficient and capable of dealing with huge datasets. It also generates probabilistic outputs that are simple to read, helping us to understand the effect of each feature on the prediction. Furthermore, logistic regression may handle both linearly and nonlinearly separable datasets by applying non-linear transformations or employing proper feature engineering. Logistic regression, on the other hand, implies a linear relationship between the features and the log-odds of the result, which may limit its performance in complex circumstances. It also implies that the observations are independent, and it might be vulnerable to outliers or imbalanced datasets.
In such circumstances, regularization approaches such as L1 or L2 regularization can help to reduce these difficulties. In many domains, including healthcare, finance, and marketing, logistic regression is used as a baseline or as part of more complex models. It is an essential component of the machine learning toolbox for binary classification tasks.
3. Support Vector Machine Algorithm
The SVM algorithm is a supervised machine learning technique that is used for classification and regression applications. It is frequently used in a variety of disciplines like image classification, text classification, and bioinformatics. SVM works by determining the best hyperplane in a multidimensional feature space for separating various classes. The purpose is to identify a hyperplane that maximizes the margin between the closest data points of distinct classes, which are referred to as support vectors.
SVM can handle both linearly and nonlinearly separable datasets by employing a variety of kernel functions such as linear, polynomial, radial basis function (RBF), and sigmoid. SVM has the advantage of being effective in high-dimensional spaces, even when the number of dimensions exceeds the number of samples.
Because it can manage datasets with several attributes, it is appropriate for difficult issues. A regularization parameter that is already present in SVM aids in preventing overfitting. SVM, however, has several drawbacks. It may be memory- and computationally- intensive, especially when working with huge datasets.
Choosing the appropriate kernel function and hyperparameters can call for domain knowledge and adjustment because SVM is also sensitive to these choices. SVM is an effective machine learning technique overall with a solid theoretical base. It has been effectively used to tackle a variety of issues and is still a crucial technique in machine learning.
4. Naïve Bayes Algorithm
The Naive Bayes algorithm is a well-known supervised machine learning technique that is commonly used for classification tasks. It is based on Bayes' theorem, which calculates the likelihood of an event given past knowledge. The term "naive" refers to the assumption that all features in the dataset are independent of one another. Despite this simplifying assumption, Naive Bayes can nevertheless produce effective results in a wide range of situations. One of the primary benefits of Naive Bayes is its simplicity and efficiency, particularly when working with enormous datasets.
It is also resilient to irrelevant features, making it suitable for text classification tasks like spam filtering or sentiment analysis. However, if the condition of feature independence is violated or there is insufficient training data, Naive Bayes may not perform effectively. It may also struggle with unusual occurrences or unbalanced datasets. It is also incapable of capturing intricate interactions between characteristics. Overall, Naive Bayes is a useful method for certain classification tasks, but it is critical to analyse its limits and determine whether it is suited for your particular application.
5. K-Nearest Neighbors (KNN)
The K-Nearest Neighbours (KNN) technique is a supervised machine learning algorithm that can be used for classification and regression applications. It is a non-parametric algorithm, which means it makes no assumptions about the data's underlying distribution. Based on a distance metric (e.g., Euclidean distance), the KNN method finds the K nearest data points in the training dataset to a given query point. The approach assigns the query point to the majority class among its K nearest neighbours for classification tasks. As the predicted value for the query point in regression tasks, it computes the mean or median value of the target variable among the K nearest neighbours.
The simplicity and convenience of implementation of the KNN algorithm is one of its advantages. It also does not require training because it is entirely based on previously saved training data. KNN can also be used to solve multi-class classification issues and manage nonlinear decision boundaries.
However, the KNN algorithm has several limitations. It is sensitive to the choice of the K parameter, as a value too small may result in overfitting, while a value too large may result in underfitting. Because it must calculate distances for each query point, the approach can be computationally expensive, especially with huge datasets. Furthermore, because it believes that all features are equally important, it performs poorly in datasets containing irrelevant or noisy features.
Because the KNN method relies on the distance metric, it is critical to normalize the input characteristics before applying it. Furthermore, it is critical to analyze the trade-offs between accuracy and computing efficiency, as well as to assess the applicability of KNN for your unique issue area.
6. Clustering Algorithms
In machine learning, clustering algorithms are used to group similar data points together based on their traits or qualities. These algorithms are unsupervised, which means they don't need labeled data to train. There are various clustering methods, each with its unique approach and characteristics. Here are some popular clustering algorithms:
- K-Means: This approach attempts to split data into K clusters, where K is a fixed number. It iteratively reduces the sum of squared distances between data points and cluster centroids. K-Means is easy to grasp and computationally efficient, but it can struggle with non-linear clusters or when the number of clusters is unknown ahead of time.
- Hierarchical Clustering: This algorithm builds a cluster hierarchy from the bottom up (agglomerative) or top down (divisive) approach. It is not necessary to define the number of clusters in advance. Agglomerative clustering begins with each data point as its own cluster and merges them based on similarity, resulting in a tree-like structure. Divisive clustering starts with all data points in one cluster and separates them recursively. Hierarchical clustering provides insights on data structure but is computationally demanding.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): This technique clusters dense areas of data points and detects outliers as noise. It can handle clusters of any shape and can automatically determine the number of clusters. DBSCAN is sensitive to parameter settings, especially the neighborhood option.
- Gaussian Mixture Models (GMM): GMM is based on the assumption that data points are created by a mixture of Gaussian distributions. It uses probability to allocate data points to clusters by estimating the parameters of these distributions. GMM can handle clusters of various forms and sizes and detect overlapping clusters. It can, however, be sensitive to starting parameter settings and may converge to local optima.
These are only a few examples of machine learning clustering techniques. The algorithm chosen is determined by several criteria, including the nature of the data, the required number of clusters, and the peculiarities of the situation at hand. It is frequently beneficial to experiment with many algorithms and analyze their performance in order to discover the best one for a certain situation.
7. Artificial Neural Networks
Artificial Neural Networks (ANN) are a type of machine learning technique that is inspired by the structure and function of biological neural networks in the human brain. ANNs are utilized for a variety of tasks such as classification, regression, pattern recognition, and others. ANNs are made up of interconnected nodes called artificial neurons or perceptrons that are arranged in layers. Weighted connections between neurons serve as the basic building elements of ANNs, allowing information to pass through the network. Each neuron aggregates input signals, performs an activation function, and sends the result to the next layer.
The feedforward neural network is the most common type of ANN, in which information flows in one direction from the input layer to the output layer via one or more hidden layers. The network modifies the weights of the connections during training by employing methods such as backpropagation, which involves propagating errors back through the network and changing the weights accordingly.
Because of its ability to simulate complicated, non-linear data interactions, ANNs have grown in prominence. They can learn and extract useful features from raw data automatically, minimizing the need for manual feature engineering. ANNs, on the other hand, frequently require significant amounts of labeled training data and can be computationally costly, especially in deep structures with many layers.
Deep Learning is a machine learning subject that focuses on training deep neural networks with several hidden layers. Deep neural networks, also known as deep ANNs, have achieved extraordinary success in a variety of disciplines, including picture and speech recognition, natural language processing, and autonomous driving. Convolutional neural networks (CNNs) for image data, recurrent neural networks (RNNs) for sequential data, and generative adversarial networks (GANs) for producing synthetic data are all architectural variations of ANNs. These modifications improve the capabilities of ANNs in several problem domains.
Finally, ANNs are a powerful machine learning tool capable of handling complicated issues. To enable successful training and deployment, they require careful design, tuning, and consideration of computational resources.
8. Random Forest Algorithm
The Random Forest technique is a frequently used machine learning algorithm for classification and regression tasks. It is an ensemble method for making more accurate predictions by combining the predictions of numerous independent decision trees. A Random Forest is a collection of decision trees, each of which has been trained on a random portion of the original data and a random subset of the available features.
During training, each tree makes predictions independently, and the final prediction is obtained by averaging the outputs of all the trees. In classification problems, the final prediction is usually the majority vote among the trees, whereas in regression tasks, it is frequently the mean or median of all the trees' predictions.
There are various advantages to using the Random Forest method. First, because it employs several trees and averages their predictions, it is particularly resistant to overfitting. It is capable of handling huge and high-dimensional datasets, as well as missing values and outliers.
It is also less impacted by irrelevant features, making it appropriate for datasets including both informative and noisy features. Furthermore, the Random Forest method estimates feature relevance, allowing users to pick the most important features in the dataset. It is relatively simple to develop and can handle both categorical and numerical data. Random Forests, on the other hand, can be computationally expensive, especially with a high number of trees.
Depending on the situation, training a Random Forest may necessitate a significant amount of computer resources and time. Because the final forecast is the outcome of an ensemble of decision trees, interpretability can be an issue.
Overall, the Random Forest algorithm is a powerful machine learning method that frequently produces outstanding results. It is especially beneficial when working with large and high-dimensional datasets, or when interpretability is secondary.
9. Apriori Algorithm
The Apriori algorithm is a common approach in machine learning for mining association rules. It is specifically developed to find frequently occurring itemsets in transactional datasets. The method generates itemsets that meet a minimum support criterion through an iterative procedure.
The Apriori technique begins by determining the most common individual items in the dataset, known as 1-itemsets. It then leverages these often occurring 1-itemsets to produce larger 2-itemsets by connecting pairs of 1-itemsets. This method is repeated iteratively, producing larger itemsets until no more frequent itemsets can be produced.
The method examines the dataset at each iteration to count the occurrences of each itemset. A frequent itemset is one whose support (the number of transactions including the itemset) exceeds the minimum support threshold set by the user. Following the discovery of frequent itemsets, the Apriori algorithm develops association rules based on these itemsets. Association rules express associations between objects and are often of the form "If itemset A occurs, then itemset B will also occur with a certain degree of confidence."
There are some limits to the Apriori algorithm. Due to the possibly enormous amount of created itemsets, it can be computationally demanding, especially when dealing with large datasets.
Furthermore, when there are many unique items or high-dimensional datasets, it may suffer from the "combinatorial explosion" problem. Despite its shortcomings, the Apriori algorithm serves as a foundation for association rule mining and has had a significant impact in the field. To solve its shortcomings, many optimisations and improvements have been proposed, making it a valuable tool for detecting correlations and patterns inside transactional datasets.
10. Dimensionality Reduction Algorithms
In machine learning, dimensionality reduction techniques are used to minimize the number of input features or variables in a dataset while keeping significant information. They contribute to overcoming the curse of dimensionality, which occurs when datasets with a large number of features result in computational inefficiency, increased complexity, and overfitting. There are several regularly used dimensionality reduction algorithms:
- PCA (Principal Component Analysis): PCA is a popular linear dimension reduction technique. It identifies linear combinations of the original features, known as principal components that capture the greatest amount of variance in the data.
- It is applicable to both supervised and unsupervised tasks, and it is especially useful when dealing with highly correlated characteristics.
- Linear Discriminant Analysis (LDA): Another linear dimensionality reduction technique that is often used for classification problems is LDA. Unlike PCA, LDA considers class labels and seeks a subspace that maximizes separability between classes while minimizing within-class dispersion.
- t-SNE (t-Distributed Stochastic Neighbour Embedding): t-SNE is a non-linear dimensionality reduction technique that excels at visualizing high-dimensional data in lower-dimensional environments. It is excellent for exploring clusters and patterns in data since it emphasizes on retaining local links between data items.
- Autoencoders: Autoencoders are unsupervised dimensionality reduction techniques based on neural networks. They figure out how to reconstitute input data from a compressed representation or bottleneck layer. By limiting the size of the network, valuable characteristics are learned, resulting in successful dimensionality reduction.
- Random Projection: Random Projection is a technique that projects the original high-dimensional space into a lower-dimensional space using random matrices. It uses the Johnson-Lindenstrauss lemma to keep pairwise distances between data points and therefore reduces dimensionality.
These are only a few dimensionality reduction algorithms. The algorithm chosen is determined by a number of criteria, including the features of the dataset, the required level of interpretability, and the specific task at hand. It is critical to assess and compare several strategies in order to identify the most effective.
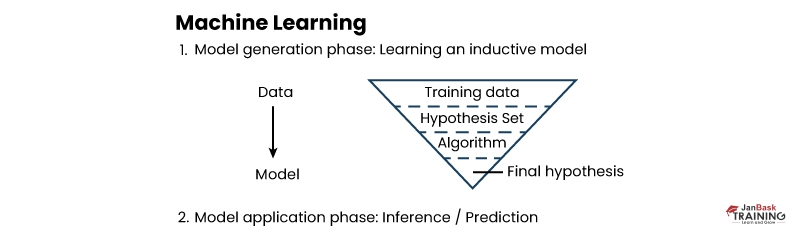
How Does Machine Learning Algorithm Work?
Machine learning algorithms analyze enormous amounts of data in order to uncover patterns or relationships. The algorithm learns from this data by modifying parameters like weights, biases, and coefficients to produce the best possible performance on the given job. This is known as training, and it entails feeding the algorithm input samples as well as the desired output or target value, and then altering its parameters to minimize the error between its predictions and the actual result.
Once trained, the algorithm can be used to generate predictions or judgements on previously unknown data. The algorithm uses the input information and its learning parameters to anticipate the outcome or conclusion.
The method's performance on new data is influenced by the complexity and applicability of the algorithm, as well as the quality and variety of the training data. Creating algorithms and models that can accurately and automatically carry out tasks that would otherwise require human assistance or knowledge is the overall objective of machine learning.
Machine learning algorithms are designed to self-learn by finding patterns in data. There are several sorts of algorithms, each with their own set of advantages:
- Labeled examples are required for supervised learning algorithms to learn from. They look for relationships between inputs and outputs in order to generate predictions about new data. Logistic regression and decision trees are two examples.
- Hidden patterns in unlabeled data are discovered by unsupervised learning techniques. They categorize data or discover associations. K-means clustering and principal component analysis are two examples.
- Reinforcement learning algorithms gain knowledge by interacting with a changing environment. To maximize performance, they use trial-and-error to discover the optimal behavior within a scenario. Q-learning and policy gradients are two examples.
- Neural networks are machine learning algorithms that are patterned after the human brain. They are composed of interconnected nodes that process data and adjust connections as a result of that processing. Convolutional neural networks and recurrent neural networks are two examples.
The sort of algorithm you use is determined by your data and what you intend to do with it. Do you require predictions, insights into patterns, optimal behavior methods, or picture recognition? You'll find the best machine learning algorithm for the job after some trial and error.
Essential Components of Machine Learning Algorithms
The fundamentals of machine learning algorithms entail becoming acquainted with the various types of algorithms used for various tasks such as classification, regression, clustering, and dimensional reduction.
It's also critical to understand the concept of overfitting and how to avoid it with approaches like cross-validation. Furthermore, data preparation is critical, and understanding feature selection and feature engineering can help an algorithm perform better. Finally, knowing how to evaluate a model's performance using measures like accuracy, precision, recall, and F1 score is critical for picking the best method for a specific task.
To use machine learning algorithms efficiently, you must first comprehend their fundamental components.
Training Data: Because machine learning algorithms learn by example, you must feed them with high-quality training data. The more data there is, the better, but it must be clear, consistent, and relevant to the work at hand.
Features: The algorithm's inputs are the features. Choose which characteristics are most useful and relevant to your aim with care. Too many characteristics might slow down learning and reduce accuracy. Too few features will not provide enough information for successful learning.
Hyper parameters: These are the parameters that are established prior to the start of the learning process. The learning rate, the number of epochs or iterations, and the regularization parameters are all examples of parameters. Optimizing performance requires fine-tuning hyper parameters. To find the best combination for your data and use case, you may need to experiment with different variables.
Generalization: The ability of an algorithm to function well on fresh and previously unknown data is generalization. If an algorithm memorizes the training data but cannot generalize to fresh data, it is useless in practice. Cross validation, regularization, and having adequate data all contribute to better generalization.
Overfitting: When algorithms memorize the training data well and find it difficult to generalize on first input is known as over-fitting. To avoid overfitting, keep your model basic, use regularization, and provide no more data than is required.
What Are The Benefits Of Using Machine Learning Algorithms?
Machine learning algorithms offer numerous advantages to businesses and organizations.
Efficiency: Machine learning algorithms are far faster than humans at analyzing large volumes of data. They are capable of detecting patterns and insights that would otherwise go missed. This enables businesses to swiftly get meaningful insights and make data-driven decisions.
Personalization: Machine learning enables businesses to personalize their client experiences. Algorithms can discover individual preferences and personalize information to each user by analyzing client data and behavior. As a result, customer engagement and experience improve.
Automation: Many automated systems and processes are powered by machine learning. Algorithms can perform repetitive and monotonous jobs, allowing humans to focus on more important activities. Automation also decreases the possibility of human error and can aid in the improvement of quality and consistency.
Adaptive Learning: Machine learning algorithms may learn from fresh data and adapt their models accordingly. They can automatically adjust to changes in data or the environment without being actively reprogrammed. As a result, machine learning is well suited to dynamic problems that vary over time.
Increased Accuracy: Accuracy is improved because ml algorithms can learn from prior examples and make accurate predictions or judgements on fresh data.
Better insights: Machine learning algorithms can identify patterns and insights in data that humans may not see, allowing for better decision making.
Increased scalability: Because ml algorithms can handle massive, complicated datasets, they are perfect for big data applications.
Machine learning algorithms improve efficiency, personalisation, automation, and adaptive learning. They can assist propel enterprises into the future and acquire a competitive advantage when appropriately used. The advantages of machine learning are vast, and use will only increase in the future years.
How Learning These Vital Algorithms Can Enhance Your Skills in Machine Learning?
Learning these critical machine learning methods can dramatically improve your field skills. Here's how it's done:
1. Gaining a thorough understanding of the fundamentals: By learning these algorithms, you will obtain a solid understanding of the essential concepts and principles of machine learning. This comprehension will serve as the foundation for future research and learning in the discipline.
2. Problem-solving abilities: Each algorithm is designed to handle a specific set of issues and data structures. You will have a diversified toolkit to approach different issue areas with different data properties if you become familiar with a wide range of methods. This improves your problem-solving abilities and allows you to select the best algorithms for specific assignments.
3. Feature selection and engineering: Understanding these methods can assist you in identifying the most relevant features and developing new useful features. This ability is critical for boosting model performance and gaining valuable insights from complex datasets.
4. Model selection and evaluation: Understanding different algorithms allows you to make informed decisions when choosing the best model for a specific task. You can analyse the benefits and drawbacks of many algorithms and select the one that best matches the task at hand. You will also be able to appropriately examine and comprehend model performance measures.
5. Model building and optimisation: By learning these methods, you will receive hands-on expertise in implementing, fine-tuning, and optimizing their parameters. This hands-on knowledge is invaluable when it comes to constructing robust and efficient machine learning models.
6. Versatility in problem domain: These methods are applicable to a wide range of applications, from simple linear regression to complicated neural networks. Learning multiple algorithms increases your adaptability in tackling a wide range of problem domains and data types, including numerical data, text, pictures, and time series.
7. Staying current: The field of machine learning is continually growing, with new algorithms and techniques being introduced on a regular basis. You will be better equipped to grasp and adapt to new advancements in the field if you have a solid foundation in these critical algorithms.
Learning these important algorithms improves your machine-learning skills by providing a solid foundation, improving problem-solving abilities, facilitating feature selection and model evaluation, enabling model building and optimization, increasing problem-domain versatility, and keeping you current with the evolving field of machine learning.
Future of Machine Learning
Machine learning has a bright future, with continual developments and discoveries predicted to shape the field. Here are a few major areas with high potential:
1. Deep Learning: Deep learning approaches, such as neural networks, have proven to be extremely effective in a variety of disciplines, including image identification, natural language processing, and autonomous driving. Deep learning architectures and algorithms are anticipated to evolve further, allowing for increasingly more sophisticated and accurate models.
2. Explainable AI: As machine learning models become more complex, the requirement for transparency and interpretability grows. Researchers are hard at work creating approaches to make AI more explainable; guaranteeing that machine learning models' judgements can be accounted for and understood by humans.
3. Reinforcement Learning Algorithms: Reinforcement learning algorithms are gaining traction in training intelligent agents to interact with their environments and learn via trial and error. This has the potential to be used in areas such as robotics, self-driving vehicles, and game play, where agents can acquire complicated behaviors and decision-making processes.
4. Transfer Learning: Transfer learning enables models to transfer knowledge from one domain to another, allowing for faster and more efficient learning. Because models may be pre-trained on big datasets and fine-tuned for specific tasks, this technique holds promise in cases where labeled data is scarce.
5. Ethical and Fair AI: As the influence of AI rises, it is critical to ensure that machine learning systems are built and implemented in an ethical and fair manner. There is a growing emphasis on resolving bias, privacy, and accountability issues in machine learning algorithms, paving the road for responsible AI development.
6. Edge Computing: As Internet of Things (IoT) devices proliferate, there is a growing demand to handle and analyze data closer to the source. Machine learning algorithms are being optimized for deployment on resource-limited devices, allowing for real-time processing and decision-making without relying heavily on cloud infrastructure.
7. Collaboration with other fields: Machine learning is becoming more intertwined with other fields such as healthcare, finance, and transportation. We should expect breakthroughs in areas such as personalized medicine, fraud detection, and smart transportation systems as interdisciplinary cooperation expands.
While the future of machine learning offers immense promise, it also comes with its ethical, societal, and technical difficulties that must be addressed. Continued study, prudent development, and deliberate integration of machine learning into many areas will all contribute to its positive social impact.
Which Certifications Are Must To Become Machine Learning Experts?
There are various high-quality online certifications available to help you become a machine learning specialist and increase your expertise and credibility. While there is no comprehensive list of "must-have" certificates in the field of machine learning, the following are some commonly recognised and regarded certifications:
1. Microsoft Certified: Azure AI Engineer Associate: The Azure AI Engineer Associate certification focuses on creating and executing AI solutions utilizing Azure Cognitive Services, Machine Learning, and other Azure AI technologies.
2. Google Cloud Certified: Machine Learning Engineer: This certification validates your ability to develop, create, and deploy machine learning models on Google Cloud Platform.
3. AWS Certified Machine Learning - Specialty: This certification verifies your ability to use the AWS Cloud to design, implement, deploy, and maintain machine learning solutions.
4. IBM Data Science Professional Certificate: This specialization, available on Coursera, covers key ideas in data science and machine learning utilizing Python and popular libraries.
5. Stanford University - Machine Learning Certificate: This certificate programme includes machine learning topics such as regression, classification, clustering, and deep learning.
It is important to note that these qualifications are not the only indicators of machine learning proficiency. Hands-on experience, continual learning, and practical application of machine learning models all contribute to your proficiency. All these certification course can help you ace your upcoming machine learning interview.
Conclusion
Machine learning algorithms are essential for computers to learn from data and make intelligent decisions. Understanding the many types of machine learning algorithms is critical for creating effective machine learning systems. Supervised learning is used for prediction and classification tasks, whereas unsupervised learning is used to identify patterns and structures in data, semi-supervised learning makes use of both labelled and unlabeled data, and reinforcement learning is focused on learning through interaction. Machine learning may uncover new possibilities and promote innovation across multiple industries by using the appropriate algorithm for the task at hand. Get ready to start your future with the machine learning certification course.
FAQs
1. Can you explain the distinction between supervised and unsupervised learning algorithms?
Supervised learning algorithms learn from labelled training data, with each instance assigned a target label. They are employed in tasks including classification and regression. Unsupervised learning algorithms, on the other hand, work with unlabeled data to find patterns or structures, such as grouping or dimensionality reduction.
2. How can I select the most appropriate machine learning method for my problem?
The method chosen is determined by criteria such as the type of problem being solved, the nature of the data, the available resources, and the required accuracy or interpretability. It is critical to analyse the characteristics and assumptions of various algorithms, and occasionally testing is required to discover the best solution.
3. How do you balance model complexity and model performance?
Increasing model complexity can possibly increase training data performance, but it comes with the danger of overfitting and poor generalization to new data. As a result, there is a trade-off between model complexity and generalizability. Regularization, cross-validation, and performance evaluation measures all aid in striking a balance between complexity and performance.
4. Can I combine various algorithms?
To boost performance, you can mix or ensemble numerous algorithms. Ensemble approaches like bagging (e.g., Random Forests) or boosting (e.g., AdaBoost) integrate numerous models' predictions to create more accurate predictions. This can reduce overfitting, improve resilience, and capture various features of the data.
5. Is feature engineering required for machine learning algorithms?
The process of modifying or selecting relevant features in a dataset to improve the performance of machine learning models is known as feature engineering. While certain algorithms are capable of dealing with raw data, feature engineering is frequently required to extract relevant representations and increase model accuracy. Normalisation, feature scaling, dimensionality reduction, and the creation of new features based on domain knowledge are all part of the process.
Trending Courses
Gen AI
- Introduction to Generative Models
- Generative Adversarial Networks (GANs)
- The Art and Science of Prompt Engineering
- MLOps: Deploying Generative AI Models
Upcoming Class
7 days 28 Jul 2026
Agentic AI
- Introduction to Agentic AI
- Multi-Agent Setup with LangGraph Context Handling in Graphs
- Performance Benchmarking Advanced Prompt Engineering for Agents
- Agent Behavior Tuning Project and Mock Session
Upcoming Class
3 days 24 Jul 2026
AI in Automation Testing
- Intro to AI & ML in Automation
- Playwright + JS (JavaScript) + API Tesng
- Automaon with Using ChatGPT & Playwright MCP server
- GitHub Copilot, AI Tools & Interview preparation
Upcoming Class
10 days 31 Jul 2026
Cyber Security
- Introduction to cybersecurity
- Cryptography and Secure Communication
- Cloud Computing Architectural Framework
- Security Architectures and Models
Upcoming Class
3 days 24 Jul 2026
Data Science
- Data Science Introduction
- Hadoop and Spark Overview
- Python & Intro to R Programming
- Machine Learning
Upcoming Class
4 days 25 Jul 2026
QA
- Introduction and Software Testing
- Software Test Life Cycle
- Automation Testing and API Testing
- Selenium framework development using Testing
Upcoming Class
3 days 24 Jul 2026
Salesforce Service Cloud
- Industry Knowledge Introduction
- Adoption and Maintenance
- Interaction Channels Introduction
- Integration and Data Management
Upcoming Class
24 days 14 Aug 2026
AWS
- AWS & Fundamentals of Linux
- Amazon Simple Storage Service
- Elastic Compute Cloud
- Databases Overview & Amazon Route 53
Upcoming Class
1 day 22 Jul 2026

 Dec 04, 2024
Dec 04, 2024  4.9k
4.9k






















 Jun 16, 2022
Jun 16, 2022 7.4k
7.4k
