
 Jan 24, 2020
Jan 24, 2020  6.4k
6.4k

31
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Data Science Blogs -
With the advent of the 21st century, human civilization has seen exponential growth in terms of computational resources at its disposal. This increased resource has allowed human civilization to perform extremely computational tasks with relative ease. One of the algorithms in need of high-end computational resources is “Random Forest”, which is being discussed in this blog.
Random forest is an evolved version of decision trees and is used to perform classification as well as regression. Random forest is a supervised learning-based algorithm that employs an extremely specialized type of learning to fall under supervised learning known as ensemble learning.

Defining Ensemble learning:
In the domain of supervised learning, ensemble learning basically is a method of using multiple learning algorithms to obtain a better result as compared to a single algorithm. Thus, instead of training a single algorithm and then use a poll based design to conclude the final output.
As it is well known thata supervised learning-based algorithm performs their task by searching through their hypothesis domain to find a suitable hypothesis for the input. Now, the ensemble model actually tries to create multiple hypotheses and solves them, thus, theoretically making a model that is better suited for a problem as compared to a single hypothesis solution. This assumption holds good for cases where it is not possible to construct a single hypothesis for the problem under consideration.
The ensemble models also use a greater amount of computational resources as compared to a single model. For consideration of poor learning in single hypothesis-based learning which is compensated by the ensemble, it considerably increases the resource requirement for the final output.
Revisiting Decision Trees:
Read: A Practical guide to implementing Random Forest in R with example
Decision trees are the building blocks of random forest. A decision tree looks like a tree-like graph with each node belonging to the decision taken. These types of designs are extremely helpful when inherits of any algorithm only contain control-statements.
In other words, a decision tree happens to be a flowchart like design whose internal nodes represent a condition which decides the next step taken by the machine. Each branch coming out of the node defines a particular path taken by the machine till the time it reaches a leaf node which depicts the final result of the query. The steps taken from the root to the leaf depict all the rules.
The tree-based design of any working model is considered one of the best as it can be visualized with ease and is mostly used in supervised learning. The tree-based design of any model provides high accuracy and ease of interpretation to any of the predictive design. As compared to linear-models, these models map non-linearity in the inherited design very well. These models can be used to solve classification as well as regression problems with ease.
Further details can be found at the Janbask decision tree blog.
Just as a forest comprises a number of trees, similarly, a random forest comprises a number of decision trees addressing a problem belonging to classification or regression. Since a random forest comprises a number of decision trees, this makes it an ensemble of models. Every entity of the forest i.e. the decision tree splits of its own class prediction and these class prediction are then put to a vote. The class with the most votes becomes the final output of the random forest.
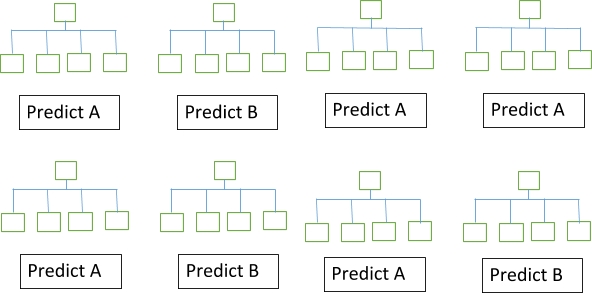
Fig. 1 Visualization of a Random Forest Model Making a Prediction
The inherited concept which makes random forests so powerful is quite simple. This is known as the Wisdom of the crowds. In the technical language of data science, the reason is stated as:
Read: Data Acquisition: Everything You Need to Know About its Tools and Components!
“A large number of models working on an uncorrelated hypothesis to solve the performance will outperform any of the individual models under consideration.”
The key in the random forest remains as a low correlation between the hypothesis which is being solved. It's The same as the low correlation shown in yields of stocks and bonds, that are used to make a portfolio which is greater than the sum of its parts. Similarly, uncorrelated models produce ensemble predictions which happen to be more precise than any of the individual prediction. This happens due to the reason that few trees might be producing error but once the output of all the trees is put to a vote, the error is negated by the output of the majority of the trees. Thus, the following make the prerequisite for the random forest to work:
a. There should be some indication in the features so that the models built using these features outperform the random guessing stuff.
b. The correlation between the prediction as well as errors should be as low as possible.
Training a random forest is just like training a decision except for the fact that there happens to be more than one tree to be trained. Since there happens to be more than one tree. Thus, for this model to be trained, a random dataset will be generated from the dataset lib of the random classifier.
The first step is to import the required libraries in the working memory:
from sklearn.ensemble import RandomForestClassifier #imports the random forest algorithm from sklearn.datasets import make_classification #imports random classifier generator
Once, the libraries are imported into the working memory, the next step is to make a dataset if there is no one available with the user. So, the following command should do the wonder:
input, labels = make_classification(n_samples=1000, n_features=6, n_informative=3, n_redundant=0, random_state=0, shuffle=False)
The above command generates a feature space with 4 classes and a total of 1000 data points.
Now, let’s train the classifier:
Read: Data Science vs Machine Learning - What you need to know?
model = RandomForestClassifier(max_depth=3, random_state=0) model.fit(input, labels)
Let's check for the importance of each feature in the forest generates:
print(model.feature_importances_) Output: [0.02384207 0.95184049 0.00756492 0.00214856 0.00845867 0.00614528] The array shows the importance of each feature underconsideration.
Now, let’s query this model
print(model.predict([[0, 0, 0, 0]])) output: 1 Thus, we get that as per the voting pattern the final output of forest is class label 1. Note: The output can vary from one example to another as the dataset is randomly generated
The random forest has numerous advantages over single instance-based models:
It’s not like that random forest has only advantages, it also suffers from few drawbacks like:
Conclusion:
Random forest is a promising ensemble technique that utilizes power voting to generate a very powerful model. The random forest can be effectively utilized in places where the wisdom of the crowd plays a role like in stock markets. In this blog, the random forest algorithm has been discussed as a comparatively better tool for decision trees. A working example of the decision tree has also been provided.
Please like and leave your comments in the comment section.
Read: Unlock the Advanced Power of Augmented Analytics in Data Science: A Transformative Fusion
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
The Complete Roadmap to Becoming a Data Engineer and Get a Shining Career
 5.6k
5.6k
Data Science Career Path - Know Why & How to Make a Career in Data Science!
219.9k
Difference Between Data Scientist and Data Analyst
432.1k
A Simple & Detailed Introduction of ANOVA
5.4k
Data Scientist Salary 2025 - Based On Location, Role & Industry
7.6k
Receive Latest Materials and Offers on Data Science Course
Interviews









 Jan 06, 2023
Jan 06, 2023 5.6k
5.6k
