Introduction
Over the years, the amount of data generated has increased by leaps and bounds, which comes in all forms and formats and also at a very high speed. Earlier, data was managed and handled manually, usually because it was limited data, but having said that, in the present situation, that is not the case. As the volume of data generated continuously increases, storing, processing, and analyzing it has become more challenging, commonly known as Big Data. Along with it, the next important question is how do we manage this Big Data? And this is where Hadoop comes into play — a framework used to store, process, and analyze Big Data.
The blog's objective is to give a basic idea of Big Data to beginners new to the platform. This article will give you a sound knowledge of Hadoop basics and its core components. You will also get to know why people started using Hadoop, why it became so popular quickly, and why there is an excellent demand for Big Data Hadoop Certification.
To prepare these tutorials ob Big Data for beginners, I took references from multiple books and prepared this gentle definitive guide for beginners in Hadoop. This tutorial will surely provide perfect guidance to help you in deciding your career as a Hadoop professional in the data management sector or why to choose Big Data Hadoop as the primary career choice.
A Gentle Introduction to What is Hadoop in Big Data
Hadoop is an open-source Apache framework that was designed to work with big data. The main goal of Hadoop in Big Data is data collection from multiple distributed sources, processing data, and managing resources to handle those data files.
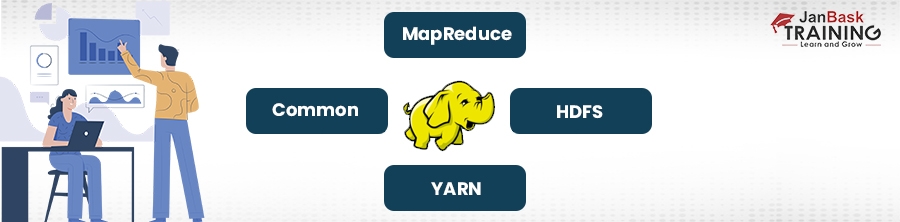
People are usually confused between the terms Hadoop and big data. Few people use these terms interchangeably, but they should not be. In actuality, Hadoop is a framework designed to work with big data. The popular modules that every Hadoop professional should know about either as a beginner or advanced user include – HDFS, YARN, MapReduce, and Common.

- HDFS (Hadoop Distributed File System) – This core module provides access to big data distributed across multiple clusters. With HDFS, Hadoop gets access to multiple file systems, too, as required by the organizations.
- Hadoop YARN – The Hadoop YARN module helps manage resources and schedule jobs across multiple clusters that stores the data.
- Hadoop MapReduce – MapReduce works similarly to Hadoop YARN, but it is designed to process large data sets.
- Hadoop Common –This module contains a set of utilities that support three other modules. Some of the other Hadoop ecosystem components are Oozie, Sqoop, Spark, Hive, Pig, etc.
Learn how to install Hadoop and Set up Hadoop cluster so that you can master Hadoop skills and grow your career.
What isn’t Hadoop?
Now we will discuss what Hadoop is not so that related confusion with the terminology can be avoided quickly.
- Hadoop is not Big Data - People are usually confused between the terms Hadoop and big data. Few people use these terms interchangeably, but they should not be. In actuality, Hadoop is a framework designed to work with big data.
- Few people consider Hadoop as an operating system or set of packaged software apps, but it is neither an operating system nor a set of packaged software apps.
- Hadoop is not a brand but an open source framework that can be used by registered brands based on their requirements.
Importance of Learning Hadoop
What is the use of Hadoop in Big Data? Hadoop is considered one of the top platforms for business data processing and analysis, and the following are some of its significant benefits for a bright career ahead:
- Scalable: Businesses can process and get actionable insights from petabytes of data.
- Flexible: To access multiple data sources and types.
- Agility: Parallel processing and minimal movement of data process substantial amounts of data with speed.
- Adaptable: To support a variety of coding languages, including Python, Java, and C++.
Tip: For more information about use of Hadoop in Big Data, read - Top 10 Reasons Why Should You Learn Big Data Hadoop?
Core Elements of Hadoop Modules
In this section of Apache Hadoop tutorial we’ll have a “Detailed discussion on Hadoop Modules or Core elements to give you valuable insights on Hadoop framework and how it actually works with big data”
HDFS – Hadoop Distributed File System
This core module provides access to big data distributed across multiple clusters of commodity servers. With HDFS, Hadoop gets access to multiple file systems too, and it can work with almost any file system. This is the primary requirement by organizations, so Hadoop Framework became so popular in a shorter time span only. The functionality of the HDFS core module makes it the heart of the Hadoop framework.
HDFS keeps track of files and how they are distributed or stored across the clusters. Data is further divided into blocks, and blocks need to access wisely to avoid redundancy.
Hadoop YARN – Yet another Resource Navigator
YARN helps manage resources and schedule jobs across multiple clusters that store the data. The significant elements of the module include Node Manager, Resource Manager, Application Master, etc.
The “Resource Manager” assigns resources to the application. The “Node Manager” manages those resources on different machines like CPU, network or memory, etc. The “Application Master” works as a library for the other two components and sits between the two. It helps in resource navigation so that tasks can be executed successfully.
Hadoop MapReduce
MapReduce works similarly to Hadoop YARN, but it is designed to process large data sets. This is a method to allow parallel processing on distributed servers. Before actual data is processed, MapReduce converts large blocks into smaller data sets that are named “Tuples” in Hadoop.
“Tuples” are easy to understand and work on when compared to larger data files. When data processing is complete by MapReduce, then work is handed over to the HDFS module to process the final output. In brief, the goal of MapReduce is to divide large data files into smaller chunks that are easy to handle and process.
Here the word MAP refers to Map, Tasks, and Functions. The “Map” process aims to format data into key-value pairs and assign them to different nodes. After this “reduce” function is implemented to reduce large data files into smaller chunks or “Tuples.” One of the important components of the MapReduce function is JobTracker which checks out how jobs are.
Tip: Read to learn more about the difference between Hadoop YARN and Hadoop MapReduce.
Hadoop Common
This module contains a set of utilities that support three other modules. Some of the other Hadoop ecosystem components are Oozie, Sqoop, Spark, Hive, Pig, etc.
Why Should You Learn Hadoop Tutorial?
To start learning Hadoop basics, there is no need to have any degree or a Ph.D. Hadoop enthusiasts having fundamental programming knowledge can help them begin their training to embark on a bright career with Big Data. At the same time, our Big Data Hadoop Online Training and Certification program can help you by availing Big Data study material pdf. Big Data Hadoop Online Free Training courses are perfectly suitable for middle and senior-level management to upgrade their skills. It’s specifically helpful for software developers, architects, programmers, and individuals with experience in Database handling.
Also, the professionals with background experience in Business Intelligence, ETL, Data Warehousing, mainframe, testing, as well as project managers in IT organizations, using which they can broaden their learning Hadoop skills. Learners that are Non-IT professionals or freshers who want to focus on Big Data learning can also directly opt for Hadoop certification so as to become leaders of tomorrow.Prepare for your Hadoop interview with these top 20 Big Data Hadoop interview questions and answers to begin your career as a Hadoop developer.
Why is Hadoop just loved by the organizations processing Big Data?
The way Hadoop process big data is just incredible. This is the reason why Hadoop Framework is just loved by the organizations that have to deal with voluminous data almost daily. Some of the prominent users of Hadoop include – Yahoo, Amazon, eBay, Facebook, Google, IBM, etc.
Today, Hadoop has made a prominent name in the industries that are characterized by big data and handles more sensitive information that could be used to provide further valuable insights. They can be used for all business sectors like Finance, Telecommunications, Retail sector, online sector, government organizations, etc. The uses of Hadoop don’t end here, but it sure gives you an idea about Hadoop's growth and career prospects in reputed organizations. If you also want to start your career as a Hadoop professional, then join Big Data Hadoop Online Free Training program at JanBask Training immediately.
Conclusion
We hope you enjoyed reading this article. If you breezed through this article and the information discussed later about what is hadoop in Big Data, what isn’t Hadoop, importance of learing Hadoop, core eleements of Hadoop modules, why should you learn Apache Hadoop tutorial, why is Hadoop just loved by the organizations processing Big Data, etc., you might be interested in checking out the details on the Big Data Hadoop Online Training and Certification program by JanBask Training and career opportunities. Feel free to write us for further queries as we like to entertain your queries quickly after expert advice only.
FAQs
1. Can you suggest how do to start learning Big Data for beginners?
Ans:- You can speak to us by sharing your thoughts through this form, and one of our team members will reply within one working day by email or telephone. We are always happy to help.
If you’d prefer to speak to us now, connect with our team, and one of the mobile app design experts will discuss your ideas and project.
2. Which Skills does your Big Data Hadoop Online Free Training and Certification Program teach?
Ans:- We’ll help you in getting started with Hadoop online and understand the world of big data. It will introduce you to Hadoop, the applications of big data, the significant challenges in big data, and how Hadoop solves these significant challenges. You will also learn essential tools that are part of the Hadoop ecosystem and frameworks such as Hive, Pig, Sqoop, and HBase. Our Big Data study material pdf will also support you in mastering these skills.
3. Which significant skills will I learn?
Ans:- The following significant skills you will learn
- HDFS
- MapReduce
- YARN components
- Sqoop
- Hadoop ecosystem
4. Who should take up this program?
Ans:-
- Aspiring data scientists
- Project managers
- IT professionals
- BI professionals
- Software developers
5. Why should I take up this program?
Ans:- You must consider taking up this program because there is an $84.6 billion projected growth in the global Hadoop market, and the average salary of a Big Data engineer is around $89K.
6. What are the prerequisites to getting started with Hadoop?
Ans:- There are no prerequisites to get started with Hadoop. But it’s recommended that learners can have a basic understanding of mathematics, statistics, and data science.
7. How do beginners get started with Big Data Hadoop?
Ans:- Big Data Hadoop enthusiasts who want to get started with Hadoop can begin with the fundamentals first, and once they have mastered the basics, they can move on to the advanced topics.
8. What are top data management specializations?
- Decision Scientist
- Data Scientist
- Data Analyst
- Data Engineer
- Machine Learning Engineer
- Data Architect
- Database Administrator
- Product Analyst
9. How will my doubts be addressed in this online data management course?
Ans:- Our Data Management Master Online Courses have live interaction classes and peer-to-peer communication forums that will help you clear your doubts also, our teaching professionals will respond to your queries. There are regular faculty Q&A sessions to clear your doubts.
10. What to expect after completing the Data Management course?
Ans:- After the completion of the Data Management course:
- You’ll have an excellent knowledge of handling the databases
- You’ll have the confidence, knowledge, and methods to proceed as a certified Data Manager
- This course will help sharpen your skills and interact with other students and professionals around the world.
- On gaining the training and certification, you can try your luck at the big companies.
Hadoop Course
Upcoming Batches
Trending Courses
Upcoming Class
9 days 30 Jun 2026
Upcoming Class
5 days 26 Jun 2026
Upcoming Class
12 days 03 Jul 2026
Cyber Security
- Introduction to cybersecurity
- Cryptography and Secure Communication
- Cloud Computing Architectural Framework
- Security Architectures and Models
Upcoming Class
1 day 22 Jun 2026
Data Science
- Data Science Introduction
- Hadoop and Spark Overview
- Python & Intro to R Programming
- Machine Learning
Upcoming Class
13 days 04 Jul 2026
QA
- Introduction and Software Testing
- Software Test Life Cycle
- Automation Testing and API Testing
- Selenium framework development using Testing
Upcoming Class
2 days 23 Jun 2026
Salesforce Service Cloud
- Industry Knowledge Introduction
- Adoption and Maintenance
- Interaction Channels Introduction
- Integration and Data Management
Upcoming Class
12 days 03 Jul 2026
AWS
- AWS & Fundamentals of Linux
- Amazon Simple Storage Service
- Elastic Compute Cloud
- Databases Overview & Amazon Route 53
Upcoming Class
1 day 22 Jun 2026

 Oct 02, 2022
Oct 02, 2022  513.4k
513.4k























 Mar 20, 2018
Mar 20, 2018 421.5k
421.5k
