
 Mar 05, 2018
Mar 05, 2018  262k
262k

06
SepDon’t Miss Out : Join our live webinar on AI in Test Automation - Register Now
- Hadoop Blogs -
Spark SQL is a famous data processing tool among Big data professionals. Structured and semi-structured data can be easily processed on Spark SQL. Here structured data is that data which has a proper schema like Hive, JSON, Cables or Parquet data which has a pre-defined set of fields, records and other data, while semi-structured data may not necessarily have a schema. Today Hadoop is extensively used by industries to analyze data and Hadoop uses MapReduce technique to provide scalable, flexible and cost-effective computing models without compromising the speed of data processing. Apache Spark was also introduced to speed up the computation process of Hadoop software.
It is believed that Spark is a modified version of Hadoop, but it is not true as it has its own cluster management computation. Infact Spark uses Hadoop to store data and to process it. So in short Hadoop is used by Spark in two ways, one is to store data and another is to process it. This article is written to provide you an introduction to Spark and discuss the same in detail. The Spark has its own way of managing clusters and the computation processes so basically it uses Hadoop just to store the data.
Apache Spark was developed in 2009 by Matei Zaharia in UC Berkley’s AMPLab. Initially under the BSD license it was launched as open source technology. In 2013 it was donated to the Apache Software Foundation and now it has become one of the topmost products of the Apache Foundation. Apache Spark is a lightning-fast computing technology. By using MapReduce technology, it can even process high-level computations easily. These high-level computations can include stream processing and interactive queries. One of the advantageous features of Spark is in-memory cluster computing, which can increase the processing speed to great extent. An extensive workload, including iterative algorithms, batch applications, streaming and interactive queries are also covered by Spark.
Apache Spark can be built through Hadoop components. There are three ways to do this and they are shown in the following figure: 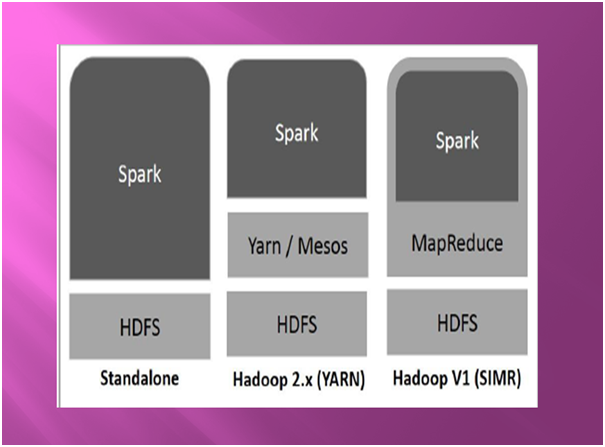
Hadoop Yarn: It means that Spark runs on Yarn. To run Spark on Yarn you do not need any pre-installation and root-access. Spark can be integrated into the Hadoop ecosystem or Hadoop stack and due to these other components can run on the top of the stack.
Standalone: In Standalone mode Spark runs on HDFS (Hadoop distributed file system) and for HDFS a separate space is allocated for HDFS. All spark and MapReduce jobs are run side by side.
Read: Pig Vs Hive: Difference Two Key Components of Hadoop Big Data
Spark in MapReduce (SIMR): Spark in MapReduce is used to launch spark job for standalone deployment. The user can start Spark and use the shell with SIMR without administrative access.
Apache Spark Core: Spark Core is underlying execution engine which is used by Spark platform and its other functionality is built upon this platform. It provides the most advantageous in-memory computing.
Spark SQL: It is a component over Spark core through which a new data abstraction called Schema RDD is introduced. Through this a support to structured and semi-structured data is provided.  Spark Streaming:Spark streaming leverage Spark’s core scheduling capability and can perform streaming analytics. It performs RDD on mini data sets and can perform a transformation on these data sets.
Spark Streaming:Spark streaming leverage Spark’s core scheduling capability and can perform streaming analytics. It performs RDD on mini data sets and can perform a transformation on these data sets.
MLib: It is a distributed machine learning framework. The MLib is nine times faster than Hadoop disk-based versions of Apache Mahout.
GraphX: It is a distributed framework for processing graphs. It can perform Graph computations through separate APIs, it is known as Pregel abstraction API. An optimized run time is also used for this abstraction.
Spark SQL is used to process structured data. Through this programming module data frame is used and it can act as distributed SQL query engine. Spark SQL has following features:
Read: Hbase Architecture & Main Server Components
Integrated:Spark programs and SQL queries are mixed seamlessly. Spark SQL can help the user to query structured data as distributed dataset which is also known as RDD in Spark. There are separate APIs for this integration like Java, Scala and Python. Due to these APIs, SQL queries can be easily run along with complex analytic algorithms.
Hive Compatibility:Unmodified Hive queries can be run on existing warehouses. Hive front-end and Meta store can be reused by Spark SQL and as a result of this it becomes fully compatible with Hive data, UDFs, queries.
Scalability: Spark SQL is advantageous for the RDD model and support fault tolerance, mid-query and handles even the larger jobs. Even for historical data a different engine can be used.
Unified Data Access: From a variety of sources the data can be loaded and collected. A single interface is provided by Schema RDDs to work efficiently with structured data which may include parquet files, Apache Hive tables and JSON files.
Standard Connectivity: You can connect with JDBC or ODBC. In Spark SQL server mode connectivity can be performed by standard JDBC and ODBC.
Apache Spark has the following architecture and includes three layers named Language API, Schema RDD and Data Sources: 
Read: Salary Structure of Big Data Hadoop Developer & Administrator
Language API:Apache Spark is compatible with many languages like Python, Java, Scala and HiveQL.
Schema RDD: A special data structure RDD is used in Spark Core and works on tables, records and fields. Schema RDD is used as a temporary table and this Schema RDD is called a Data Frame.
Data Sources: For Apache Spark the usual data sources are Avro files, text files and data sources for Spark SQL is different. Data sources for Spark may include JSON, Parquet files, Hive tables, Cassandra database and others.
The Data frame is basically a collection of distributed data. The data is organized into named columns and are like tables with better optimization. A Data Frame for Spark can be constructed from various data sources like external databases, data files, existing RDDs. Spark data frames have the following features:
Conclusion
Nowadays Hadoop is being used by a number of organizations. As data processing is the key to success in this era of online businesses, so the developers need efficient tools to process data. Apache Spark speeds up the data processing in a distributed environment and therefore is getting popular. Apache Spark has many features due to which it is the most preferred tool to perform SQL operations using Data Frames.
Read: Top 45 Pig Interview Questions and Answers
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Search Posts
Related Posts
Receive Latest Materials and Offers on Hadoop Course
Interviews









 May 10, 2018
May 10, 2018 759.9k
759.9k

 759.9k
759.9k