
 May 03, 2019
May 03, 2019  711.9k
711.9k

03
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Hadoop Blogs -
Hadoop is supported by the Linux platform and its different flavors. So, it is necessary to install Linux first to set up the Hadoop environment. In case, you have any other operating system; you could use a Virtual box Software and run Linux inside the Virtual box. Hadoop is generally installed in two modes, single node, and multi-node. Hadoop Installation Modes
Single Node Cluster means there is only a single Data Node running and setting up all NameNode, ResourceManager, DataNode, and NodeManager on a single machine. It is generally used for study and testing purpose. For small environments, single node installation can efficiently check the workflow in a sequential manner as compared to large environments where data is distributed across hundreds of machines.
In the case of Multi-node cluster, there are multiple Data Nodes running, and each data node runs on different machines. These types of clusters are suitable for big organizations who process voluminous data every day. They have to deal with petabytes of data daily distributed across hundreds of machines, so they prefer using multi-node clusters for large environments. Prerequisites for Hadoop Installation
Hadoop Installation on Linux CentOS
Command: tar –xvf jdk-8u101-linux-i586.tar.gzCommand: wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gzCommand: tar –xvf hadoop-2.7.3.tar.gz
Command: vi .bashrcCommand: source .bashrcCommand: java –version Command: hadoop versionCommand: cd hadoop-2.7.3/etc/hadoop/ Command: Is A Complete list of Hadoop files are located in /etc/Hadoop directory and they can be displayed using “ls” command.Command: vi core-site.xmlHere are the steps to configure core-site.xml file:
Read: Key Features & Components Of Spark Architecture
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Command: vi hdfs-site.xmlHere are the steps to configure hdfs-site.xml file:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permission</name>
<value>false</value>
</property>
</configuration>
Command: cp mapred-site.xml.template mapred-site.xml command: vi mapred-site.xml.Here are the steps to configure mapred-site.xml file:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Command: vi yarn-site.xmlHere are the steps to configure yarn-site.xml file:
<?xml version="1.0">
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
Command: vi hadoop-env.shcommand: bin/hadoop namenode -formatThese commands format HDFS through NameNode. You should never format the running file system; otherwise you will all the data stored on the system.
Command: cd hadoop-2.7.3/sbin command: ./start-all.shCommand: ./hadoop-daemon.sh start namenodeCommand: ./hadoop-daemon.sh start datanodeCommand: ./yarn-daemon.sh start resource managerCommand: ./yarn-daemon.sh start nodemanagerCommand: ./mr-jobhistory-daemon.sh start historyservercommand: jpslocalhost:50070/dfshealth.html to check the Name Node interface.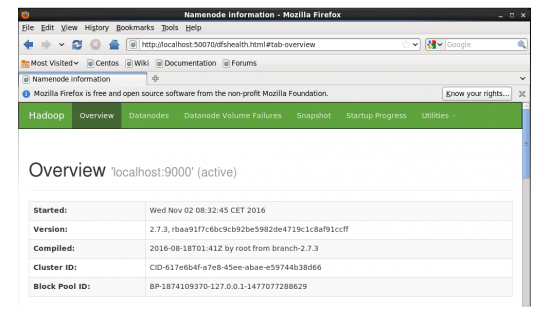 Congratulation, you have successfully installed a single node Hadoop cluster in one go. In the next section, let us learn how to install Hadoop on a multi-node cluster.
Congratulation, you have successfully installed a single node Hadoop cluster in one go. In the next section, let us learn how to install Hadoop on a multi-node cluster.
The multi-node cluster contains two or more data nodes in a distributed Hadoop environment. It is practically used in organizations to analyze and process petabytes of data. With a Hadoop certification, you may learn Hadoop environment set up and installation practically. Here, we need two machines, Master and Slave. Data node is running on both machines. Let us start with multi-node cluster set up in Hadoop.
Read: A Complete List of Sqoop Commands Cheat Sheet with Example
What are the Prerequisites?
192.168.56.102 and the IP address for slave machine - 192.168.56.103.Command: service iptables stop command: sudo chkconfig iptables offCommand: sudo nano /etc/hostsWith this command, the same properties are displayed in both, the master and the slave file.
Command: service sshd restartCommand: ssh-keygen –t rsa –p “”Command: cat $HOME/ .ssh/id_rsa.pub>> $HOME/ .ssh/authorized_keysCommand: ssh-copy-id –I $HOME/ .ssh/id_rsa.pub Janbask@slaveCommand: tar –xvf jdk-8u101-linux-i1586.tar.gzCommand: wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gzCommand: tar –xvf hadoop-2.7.3.tar.gzCommand: vi .bashrcCommand: source .bashrcCommand: java –version command: hadoop versioncommand: sudo gedit masterscommand: sudo gedit /home/janbask/hadoop-2.7.3/etc/hadoop/slavescommand: sudo gedit /home/JanBask/hadoop-2.7.3/etc/hadoop/slavescommand: sudo gedit /home/JanBask/hadoop/-2.7.3/etc/hadoop/core-site.xmlHere are the steps to configure core-site.xml file in Hadoop.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
Command: sudo gedit /home/JanBask/hadoop-2.7.3/etc/hadoop/hdfs-site.xmlHere are the steps to configure hdfs-site.xml file in Hadoop.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/edureka/hadoop-2.7.3/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/edureka/hadoop-2.7.3/datanode</value>
</property>
</configuration>
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/edureka/hadoop-2.7.3/datanode</value>
</property>
</configuration>
Command: cp mapred-site.xml.template mapred-site.xml command: sudo gedit /home/Janbask/hadoop-2.7.3/etc/hadoop/mapred-site.xmlHere are the steps to configure the mapred-site file in Hadoop.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
command sudo gedit /home/JanBask/hadoop-2.7.3/etc/hadoop/yarn-site.xmlHere are the steps to configure the YARN-site XML file in Hadoop.
Read: A Comprehensive Hadoop Big Data Tutorial For Beginners
Command: hadoop namenode -formatCommand: ./sbin/start-all.shCommand: jpsIn the end, go to the master:50070/dfshealth.html on your master machine to check that will give the NameNode interface. Now, you should check the number of live nodes; if it is two or more than two, you have successfully set up a multi-node cluster. In case, it is not two then you surely missed any step in between that we have mentioned in the blog. But don’t panic and go back to verify each of the steps one by one. Focus more on file configurations because they are a little complex. If you find any issue then fix the problem and move ahead.
Here we have focused on two data nodes only to explain the process in simple steps. If you want you can add more nodes as per the requirements. I would recommend starting practicing with two nodes initially, and you can increase the count later.
Final Words:
I hope this blog would help you in Hadoop installation and setting up a single node and multi-node cluster successfully. If you are still facing any problem, then you should take help from mentors. You can join the online Hadoop certification program at JanBask Training and learn all practical aspects of the framework.
We have a huge network of satisfied learners spread across the globe. The JanBask Hadoop or Big Data training will help you to become an expert in HDFS, Flume, HBase, Hive, Pig, Oozie, Yarn, MapReduce, etc. Have a question for us? If yes, please put your query in the comment section, we will get back to you.
Read: What Is Splunk? Splunk Tutorials Guide For Beginner
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Hadoop Course
Interviews









 Aug 28, 2024
Aug 28, 2024 931.6k
931.6k

 931.6k
931.6k