 Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Have a big interview for data structure job roles? Worried about what data structures interview questions to prepare?
There is nothing to panic about, if you have a list of interview questions on data structures & algorithms or data structures interview questions in JAVA around you, you will be good to go. In this article, we aim to provide you with valuable insights into common interview questions related to Data Structures.
Being well-prepared for your data structure interview is essential, as it allows you to showcase your knowledge and expertise to potential employers. Remember, interviewers are not trying to catch you off guard with these complicated data structures questions but rather assess your understanding of the subject matter.
You can also learn more about data science course for beginners on our official site. By familiarizing yourself with these interview questions, you can enhance your chances of success in landing a job in fields such as Data Science and Java-based roles, where data structures and algorithms play a crucial role. Let's delve into these Data Structure interview questions to help you excel in your next interview!
Ans:- Data Structure is data collection, management, and storage format for easy access & modification. In other words, it is a collection of data values and the relationship between them and functions & operations that can be applied to these values.
Ans:- Data Structures are mainly of the following two types:
Few examples - Graphs & trees.
Ans:- Data structures are part of the following branch of computer science:
Ans:- A linked list can be a subset of both linear and nonlinear, it depends on its usage & application. If it is used for access strategies, then it is a part of linear structures but when used for data storage, it can be called a non-linear data structure.
Ans:- It is simply a sequence of data objects where elements of data structures are not stored in adjacent memory locations. Each element is inside such a setting is an individual object called a node. Every node has 2 items, one is a data field and the other is a reference to the next node. The head is the entry point in each linked list. When the list is empty, the head is a null reference and the last node has a reference to null.
Scie
Ans:- The algorithm is a defined procedure, which demonstrates the actions or steps to be executed in a certain order to get the desired outputs. An algorithm refers to a precise and well-defined set of instructions or steps that need to be followed in a specific order to achieve the desired outcomes. It provides a systematic approach to problem-solving by outlining the actions or operations required.
Ans:-
Ans:- A doubly linked list is a complex type of linked list, further in which each node has two links, the first link connects to the next node pinned in the sequence, whereas the second link is connected to the previous node. It allows for easy transversal between the data elements in different directions.
Here are a few examples of a doubly linked list:
Ans:-
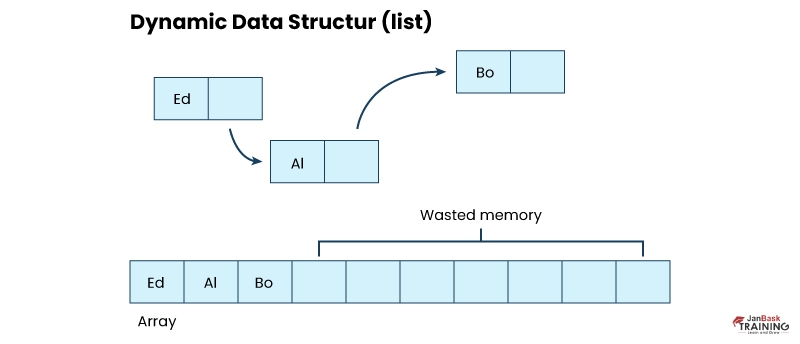
Dynamic data structures are a collection of data in memory that expands and shrinks as per the program. And allows the programmer to regulate memory utilization as per requirement. A few examples of dynamic data structures are slack, queue, heap, linked list, and array.
Ans:- A problem can be solved in too many ways. To treat computational problems, the algorithm analysis provides an estimation of the required resources and also helps to determine the time and space these resources would require to execute.
Ans:- A stack is a data type that defines a linear data structure with an order - LIFO (Last in first out) or FILO (first in last out). Three basic operations /functions of the stack are - Pop, peek, and push.
Stacks are used for:-

Ans:- The queue data structure is a data type that specifies the ordered list or linear data structure by using the first in first out (FIFO) operation for gaining access to elements. In such a structure, insert operations are done at the end “REAR” and delete operations are done on the other end called “FRONT”.
Here are some of the applications of queue data structures:
Ans:- A Dequeue, short for the double-ended queue, is a data structure that allows the insertion and removal of elements from both ends of the queue. It provides operations to delete and insert elements at both the REAR and FRONT ends of the queue.
Ans:- Stack structure has its application in -
Ans:- Heap and Stack both of them are part of memory and are often required for use in JAVA for multiple needs this one of the most important data structures and algorithms interview questions: But here is what makes them incomparable:
Ans:- PUSH and POP help to define how the data should be stored and retrieved within a stack.
Ans:- A postfix expression is an expression where the operators follow the operands. The best part of this expression is:
For example - If you write - a+b, it will be shown as ab+ in postfix.
Ans:- QuickSort Algorithm has considered the fastest it delivers the best performance with more inputs. Here are the reasons why this algorithm is said to be best & fastest over other sorting algorithms:
Ans:- Merge sort is a type of a divide and conquer algorithm that helps in sorting the data. This merges & sorts the adjacent data and develops bigger sorted lists out of it, these multiple lists are merged recursively to form even bigger sorted lists - until you don’t get a final and single sorted list.
Ans:- The graph data structure is a non-linear data structure that comprises nodes or vertices connected by edges or arcs, enabling the storage and retrieval of data. These edges can be either directed, indicating a one-way connection, or undirected, allowing for a two-way connection between vertices.
Ans:- Graph data structures are used for:
Ans:-
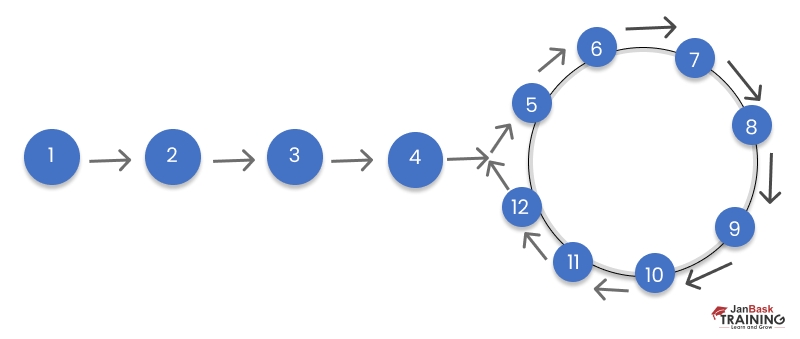
Ans:- There are two commonly used methods to determine whether a linked list contains a loop:
Ans:- Multilinked structures are commonly used in scenarios where indexing and sparse matrices need to be generated. These structures provide efficient storage and retrieval of data for such applications.
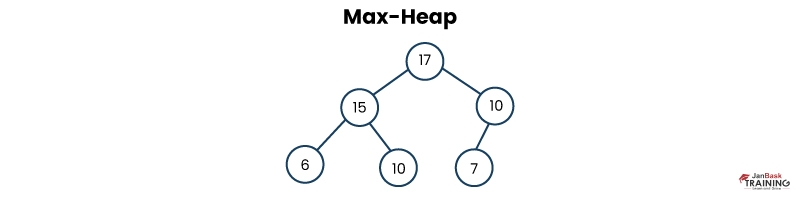
Ans:- In a max heap data structure, the value of the root node is greater than or equal to the values of its child nodes. This hierarchical arrangement ensures that the maximum element is always stored at the root, allowing for efficient retrieval of the maximum value from the heap.

Ans:- A jagged array is an array where its elements are themselves arrays of different sizes and dimensions. Unlike a regular two-dimensional array, jagged arrays allow each row to have a different length, providing flexibility in representing irregular or ragged data structures.
Ans:- A queue can be implemented using two stacks. Let q be the queue andstack1 and stack2 be the 2 stacks for implementing q. We know that stack supports push, pop, and peek operations and using these operations, we need to emulate the operations of the queue - enqueue and dequeue. Hence, queue q can be implemented in two methods (Both the methods use auxillary space complexity of O(n)):
1. By making enqueue operation costly:
Here, the oldest element is always at the top of stack1 which ensures dequeue operation occurs in O(1) time complexity.
To place the element at top of stack1, stack2 is used.
Pseudocode:
Enqueue: Here time complexity will be O(n)
enqueue(q, data):
While stack1 is not empty:
Push everything from stack1 to stack2.
Push data to stack1
Push everything back to stack1.
Dequeue: Here time complexity will be O(1)
deQueue(q):
If stack1 is empty then error else
Pop an item from stack1 and return it

2. By making the dequeue operation costly:
Here, for enqueue operation, the new element is pushed at the top of stack1. Here, the enqueue operation time complexity is O(1).
In dequeue, if stack2 is empty, all elements from stack1 are moved to stack2 and top of stack2 is the result. Basically, reversing the list by pushing to a stack and returning the first enqueued element. This operation of pushing all elements to a new stack takes O(n) complexity.
Pseudocode:
Enqueue: Time complexity: O(1)
enqueue(q, data):
Push data to stack1
Dequeue: Time complexity: O(n)
dequeue(q):
If both stacks are empty then raise error.
If stack2 is empty:
While stack1 is not empty:
push everything from stack1 to stack2.
Pop the element from stack2 and return it.

Ans:- A stack can be implemented using two queues. We know that a queue supports enqueue and dequeue operations. Using these operations, we need to develop push, pop operations. Let stack be ‘s’ and queues used to implement be ‘q1’ and ‘q2’. Then, stack ‘s’ can be implemented in two ways:
1. By making push operation costly:
This method ensures that the newly entered element is always at the front of ‘q1’ so that pop operation just dequeues from ‘q1’.
‘q2’ is used as auxillary queue to put every new element in front of ‘q1’ while ensuring pop happens in O(1) complexity.
Pseudocode:
Push element to stack s: Here push takes O(n) time complexity.
push(s, data):
Enqueue data to q2
Dequeue elements one by one from q1 and enqueue to q2.
Swap the names of q1 and q2
Pop element from stack s: Takes O(1) time complexity.
pop(s):
dequeue from q1 and return it.
2. By making pop operation costly:
In push operation, the element is enqueued to q1. In pop operation, all the elements from q1 except the last remaining element, are pushed to q2 if it is empty. That last element remaining of q1 is dequeued and returned.
Pseudocode:
Push element to stack s: Here push takes O(1) time complexity.
push(s,data):
Enqueue data to q1
Pop element from stack s: Takes O(n) time complexity.
pop(s):
Step1: Dequeue every elements except the last element from q1 and enqueue to q2.
Step2: Dequeue the last item of q1, the dequeued item is stored in result variable.
Step3: Swap the names of q1 and q2 (for getting updated data after dequeue)
Step4: Return the result.

Ans:- There is a total of 6 types of trees:
Ans:- Bubble sort is a simple comparison-based sorting algorithm. It works by repeatedly comparing adjacent elements in a list and swapping them if they are in the wrong order. The algorithm continues this process until the entire list is sorted.
Ans:- File structures and storage structures are two different concepts related to data organization: Storage structures refer to the way data is structured and stored in the computer's memory. It defines how the data is represented, organized, and accessed within the memory. Examples of storage structures include arrays, linked lists, trees, and hash, make sure you are familiar with the topic, this is one of the most asked data structures and algorithms interview questions.
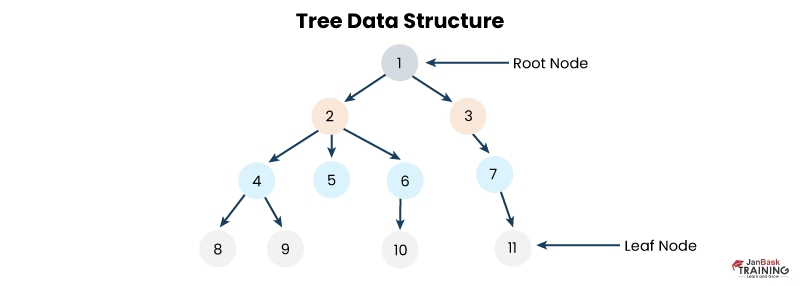
Ans:- The tree data structure has the following applications:
Ans:-
Ans:- A spanning tree is a subset of Graph G that has all the vertices covered with the least number of edges. Such trees do not have a cycle, they cannot be disconnected. The number of such trees depends on how the graph is connected. Say a complete undirected graph can have n(n-1) a number of spanning trees - where n calls for nodes.

Ans:- You can use two data structures to perform LRU cache:
Ans:- The selection sorts are:
Ans:- The size of the array - If we need to add more elements in the queue, we need to expand the size of the queue, but by chance, if we are using an array to implement a queue, it is not possible to extend the array size, therefore, array implementation of the queue is often a problem.
Waste of memory- The space of the array that is used for storing queue elements cannot be reused to store the queue elements because the elements can only be put in from the front end, and the value of the front end is so high that all the space before that will not be filled completely. If these type of questions make it complicated for you to understand data science, you can take help of our data science course for beginners on the janbask official site to understand them.
Ans:- Tree data structures find applications in various domains, including:
Ans:- A graph, denoted as G(V, E), is a collection of vertices (nodes) V and edges E that connect these vertices. It is a non-linear data structure where nodes may have complex relationships among them, forming a network of interconnected elements. Graphs can be seen as cyclic trees, as they do not strictly follow parent-child relationships.
Ans:- In graph theory, the terms cycle, path, and circuit have distinct meanings:
Ans:- Graphs can be implemented using different data structures depending on the requirements. Two commonly used data structures for graph implementation are:
Ans:- Breadth-First Search (BFS) uses a queue data structure, while Depth-First Search (DFS) utilizes a stack data structure for traversal and exploration of graph elements.
Ans:- The graph data structure finds applications in various domains, such as:
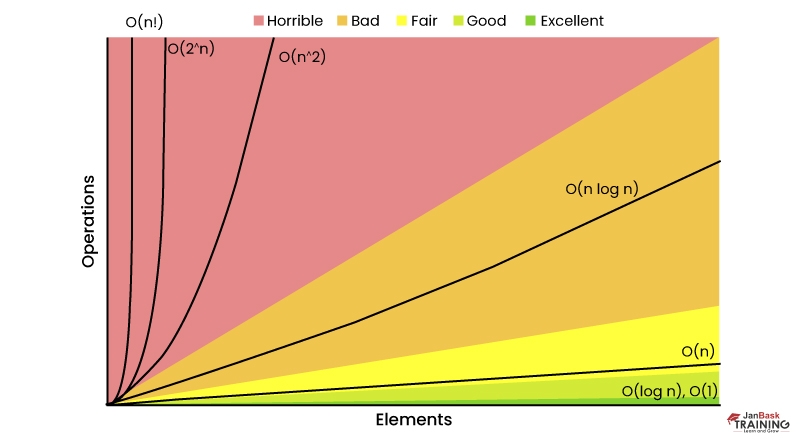
Ans:- Big O notation is commonly used in algorithm analysis because it provides an upper bound on the worst-case time complexity. In most cases, analyzing the upper bound is sufficient for evaluating an algorithm's performance. Big Theta notation, on the other hand, represents both the upper and lower bounds, which may be more challenging to determine accurately.
Additionally, calculating tight bounds can be more complex and often unnecessary for practical purposes. You can learn more about it in through an expert data science certification course on Janbask’s official side.
Ans:- To implement an LRU (Least Recently Used) cache, two data structures are commonly used:

Ans:- To check if a binary tree is a BST, you can perform an in-order traversal and verify if the elements are sorted in ascending order. During the traversal, keep track of the previous key value, and if the current key value is less than or equal to the previous one, the tree is not a BST.
Ans:- To reference all the elements in a one-dimensional array, you can use an indexed loop. By iterating from index 0 to the array size minus one, the loop counter can access each element of the array sequentially.
Ans:- Data structures are applied in various fields to efficiently organize and manipulate data. Some areas where data structures are commonly used include:
In the context of arithmetic expressions, the notations represent different ways of writing expressions while maintaining the same essence or output:
A binary tree is a type of data structure composed of nodes, where each node has at most two child nodes: a left child and a right child. The binary tree structure resembles an upside-down tree, with the topmost node called the root. The left child represents the left subtree, and the right child represents the right subtree. Binary trees are often used in programming as an extension of linked lists. If you are eager to learn about data science in-depth, you can also learn through the data science certification online.
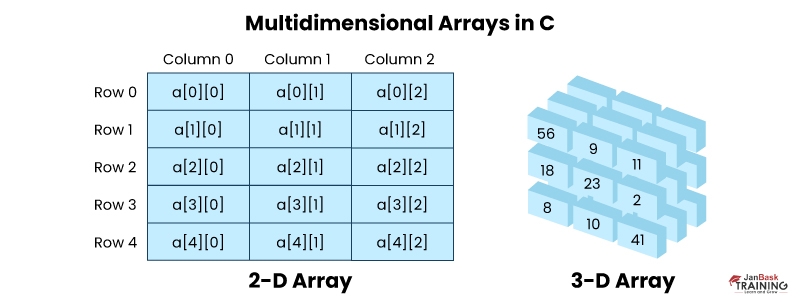
Multidimensional arrays are data structures that use multiple indexes to store data in a tabular form. They are useful when data cannot be adequately represented using a single dimension index. For example, a two-dimensional array can be seen as a table with rows and columns, while a three-dimensional array can be visualized as a cube with multiple layers.
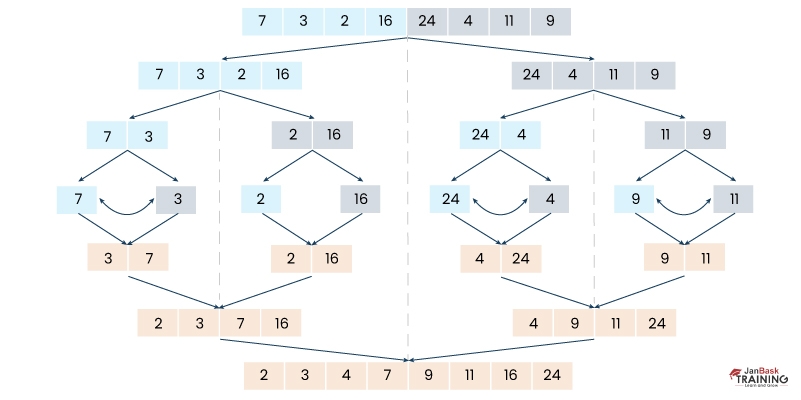
Ans:- Merge sort is a technique that involves dividing and sorting data to achieve the desired outcome. It merges adjacent elements and creates larger sorted elements, which are then combined until a single sorted list is obtained. Merge sort is valuable for efficiently sorting large datasets.
Ans:- Linked lists offer several advantages, including easy data modification and flexibility regardless of the number of elements present. This makes them an ideal data structure for implementing software testing and quality assurance processes.
Ans:- In data storage and retrieval, PUSH and POP are two fundamental operations. PUSH involves adding data to the stack, while POP refers to retrieving data from the stack. During retrieval, only the topmost element is considered.
Ans:- Memory allocation depends on the data type of the variables being declared. For example, if an integer variable is declared, it will consume 32 bits of memory storage. The allocated space varies based on the data type.
59). Compare the advantages and disadvantages of using a heap versus a stack.
Ans:- The heap offers advantages such as flexibility and dynamic memory allocation, allowing for efficient memory management. However, accessing memory in the heap is slower compared to the stack. It's important to consider these factors when choosing between the two.
Ans:- To insert new data into a tree, follow these steps: first, check if the data is unique and not already present in the tree. Then, determine if the tree is empty. If it is, insert the new item into the root. If the key is smaller than the root's key, insert the data into the left subtree; otherwise, insert it into the right subtree.
Ans:- A binary tree can have a minimum of zero, one, or two nodes. It is possible to have an empty tree, a tree with just one node, or a tree with a root and two child nodes.
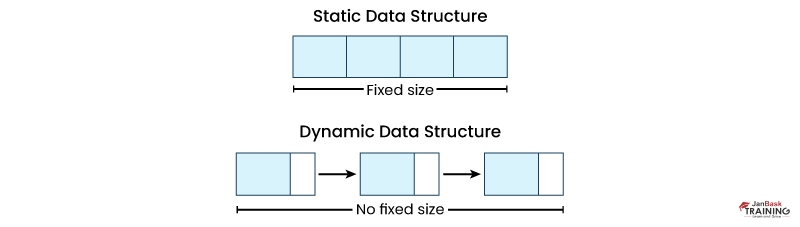
Ans:- Dynamic data structures differ from standard data structures in that they offer flexibility. These structures can be expanded or contracted as needed, allowing for efficient manipulation of data without strict limitations on structure size.
Ans:- In programming, an array is a data structure where data is stored and accessed based on an index that corresponds to the element's position in the data sequence. This enables flexible data access in any order. An array is essentially a variable with a fixed number of indexed elements.
Ans:- A minimum of two queues is required for implementing a priority queue. One queue is used for sorting priorities, while the other is used for storing the actual data. Let’s move on to more difficult data structure and algorithm interview questions that freshers find hard to answer.
Ans:- Linked lists have several advantages over arrays, including dynamic data structure, ease of insertion and deletion operations, and efficient memory utilization. They are also well-suited for implementing data structures like queues, trees, and stacks.
Ans:- Stacks have various applications in data structures, including expression evaluation, backtracking, function calling and return, memory management, and checking parenthesis matching in expressions.
Ans:- Data structures find applications in numerous areas, including numerical analysis, operating systems, artificial intelligence, compiler design, database management, graphics, statistical analysis, and simulation, all of which are relevant in QA training and software testing.
Ans:- The main difference lies in the memory area accessed. Storage structure refers to the data structure in the computer system's memory, while file structure represents the storage structure in auxiliary memory.

Ans:- A multidimensional array consists of more than one dimension and is essentially an array of arrays or a layered array. The most basic form is a 2D array, which resembles a matrix or table with rows and columns. Declaring a multidimensional array is similar to declaring a one-dimensional array, but with additional dimensions.
Ans:- A stack is a data structure that allows access to the topmost element. Data is stored in a stack, and each new data element added to the stack "pushes" the existing elements downwards. This enables easy retrieval of the most recent data from the top of the stack.
Ans:- A queue is a data structure that operates on the principle of First In First Out (FIFO), where the first element added to the queue is the first one to be processed. A common application of a queue is in scheduling systems, where tasks or commands are placed in a queue and executed in the order they were received.
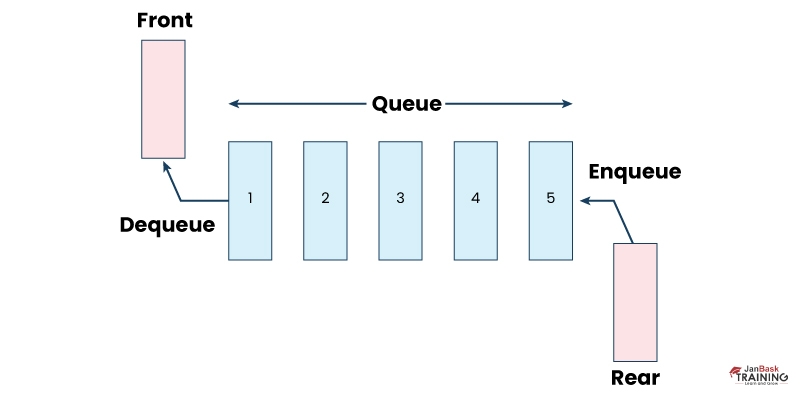
Ans:- Dequeueing refers to the operation of removing or accessing the element at the front of a queue. It allows retrieving the earliest element that was added to the queue for further processing or manipulation.
Ans:- Stacks and queues are distinct data structures with notable differences:
Ans:- Variables are fundamental for storing data in a computer's memory. They represent individual pieces of data, such as characters or numbers, and simplify programming by allowing values to be referred to by their names. The specific way variables are stored depends on the programming language, which may involve variable declaration and different type requirements.
Ans:- A queue can be implemented using a stack by making either the enqueue or dequeue operation more complex. One approach involves using two stacks: s1 (main stack) and s2 (temporary storage). The enqueue operation can be made costly by transferring elements from s1 to s2 before pushing the new element to s1. The dequeue operation remains a simple pop operation from s1.
Ans:- To implement a stack using queues, two queues (q1 and q2) can be utilized. Making the push operation costly involves moving elements from q1 to q2, enqueueing the new element in q1, and transferring elements from q2 back to q1. Making the pop operation costly entails moving all but the last element from q1 to q2, removing the last element from q1, and transferring elements from q2 to q1.
Ans:- Push and pop operations are fundamental operations performed on stacks. Push adds an element to the stack, while pop removes an element from the stack.
Ans:- Quicksort is generally regarded as the fastest sorting algorithm due to its average-case time complexity of O(n log n). While it has a worst-case time complexity of O(n^2), the average-case performance makes it more efficient than other sorting algorithms.
Ans:- Merge sort is a divide and conquer sorting algorithm. It divides a list of elements into two halves, recursively applies merge sort to each half, and then merges the sorted halves. By repeatedly merging sorted sublists, the entire list becomes sorted.

Ans:- Asymptotic analysis involves evaluating the mathematical runtime performance of algorithms. It helps establish best-case, worst-case, and average-case scenarios, allowing for an understanding of how algorithms perform and compare as the input size grows.
I hope you have got the data structure interview questions or data structures interview questions JAVA-based. We have a complete bank of data structures for interview questions, for which you can consult us. We will lead you to helpful ways to strengthen your practice for algorithms and data structures interview questions.
If you have been looking for data structure interview questions in Java, these are a few important algorithms and data structure interview questions. To understand the components of DS interview questions in-depth, a learning guide is required. Knowing and preparing these data structure interview questions can easily help if you wish to crack your data science and Java-based job interviews.
But to know more about algorithms and data structures interview questions or data structures interview questions in Java, you can buy our Data science self-learning kit, where you will find complete packaged knowledge on data structures and others - from concepts to interview questions, you will be served with comprehensive knowledge. If you are confused about how to prepare DSA interview questions, you can even reach out to our instructors, who will help you find the finest & effective ways to prepare and crack these questions during the interview process.
Question 1: What are the key characteristics of an exemplary data structure?
Ans:- A good data structure should have efficient operations for the insertion, deletion, and retrieval of data. It should utilize memory efficiently, minimize time complexity for common operations, and provide easy and intuitive ways to access and manipulate data.
While preparing for data structures questions, you should learn about the exemplary data structure in-depth.
Question 2: What is the difference between an array and a linked list?
Ans:- Arrays and linked lists are both data structures used to store collections of elements, but they differ in their underlying implementation. Arrays have a fixed size and store elements in contiguous memory locations, allowing for direct access using indices. Linked lists, on the other hand, consist of nodes that store both data and a reference to the next node, enabling dynamic size and efficient insertions and deletions but slower access times. You can check out the class for data science to learn more about it.
Question 3: What is the significance of time complexity in data structures?
Ans:- Time complexity measures the efficiency of an algorithm or operation in terms of the input size. It helps in understanding how the performance of a data structure scales with the size of the data. A lower time complexity indicates faster execution, making it crucial to choose data structures and algorithms with optimal time complexity for specific tasks.
Question 4: What are the trade-offs between different types of search algorithms?
Ans:- Different search algorithms, such as linear search, binary search, and hash-based search, have their advantages and trade-offs. Linear search is simple but less efficient for large collections. Binary search requires a sorted list but has a faster search time. Hash-based search offers constant-time lookup but requires additional memory for hash tables and may have collisions.
Question 5: How do trees and graphs differ as data structures?
Ans:- If you have been reading data structure interview questions and answers, you must have seen a a common understanding that Trees and graphs are both non-linear data structures, but they differ in terms of their relationships and connectivity. Trees have a hierarchical structure with a single root node and branching child nodes. They typically have a specific order and are used for efficient searching, sorting, and hierarchical representations. Graphs, on the other hand, have arbitrary connections between nodes called edges, allowing for complex relationships. Graphs are suitable for modeling networks, relationships, and various real-world scenarios.
Question 6: How do I prepare for a data structure interview?
Ans:- There are multiple online platforms offering courses on data structures. You can choose what suits you the best. Once you join a data science training program, you’ll know all about data structures which will help you prepare for Java data structures interview questions and questions on data structures and algorithms with answers.
Question 7: What is the scope of Data Structure?
Ans:- Computer Science and Software Engineering have a broad and diverse scope of usage of Data structures across the fields. It is being utilized almost in every software now a days. Enroll in data science training programs and prepare for dsa interview questions and data structures and algorithms interview questions and answers.
Question 8: Is DSA worth learning in 2024?
Ans:- Absolutely Yes! Data Structures and Algorithms (DSA) have a huge scope and are garnering more recognition day by day. All you have to do is join a data science course for beginners and get ready for your interview questions on data structures and Java data structures interview questions and answers.
Question 9: Is 2 months enough to learn DSA?
Ans:- Yes with your sheer dedication and hard work you can learn DSA and crack your dream job. Enroll in a data science certification course and prepare for all possible questions on data structures.
Question 10: Can data structures and algorithms get you a job?
Ans:- Earning a Python data science certification can not only land you a job but also a high-paying one. According to GlassDoor, Data structures and algorithms have an average salary of $136,205 per year in the United States. If you want to have a career get ready for your interviews with data structure interview questions.

Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment








