
 Mar 21, 2020
Mar 21, 2020  4.5k
4.5k

25
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Data Science Blogs -
ARIMA is an acronym for AutoRegressive Integrated Moving Average. It is a class of models that captures a suite of different standard temporal structures in time series data. In this tutorial, you will discover how to develop an ARIMA model for time series data with Python. It is basically a forecasting equation for a stationary time series. It is utilized to figure out what things are much of the time purchased together or put in a similar basket by clients. It utilizes this buy data to use adequacy of deals and promoting. Market Basket Analysis searches for blends of items that as often as possible happen in buys and has been productively utilized since the presentation of electronic retail location frameworks that have permitted the assortment of monstrous measures of information.
In association rules, the objective is to distinguish thing groups in transaction type databases. Association rule revelation in marketing is named "market basket analysis" and is planned for finding which gatherings of items will, in general, be bought together. These things would then be able to be shown together, offered in post-transaction coupons, or suggested in internet shopping. We portray the three-organize process of rule age and afterwards evaluation of rule solidarity to pick a subset. We take a gander at the mainstream rule-producing Apriori algorithm, and at that point criteria for deciding the quality of rules.
This model is further divided into three types:
Linear trend estimation is a statistical system to help translation of information. At the point when a progression of estimations of a procedure is treated as a period arrangement, trend estimation can be utilized to make and legitimize explanations about inclinations in the information, by relating the estimations to the occasions at which they happened. This model would then be able to be utilized to depict the conduct of the watched information, without clarifying it. Right now, trend estimation communicates information as a linear function of time, and can likewise be utilized to decide the hugeness of contrasts in a lot of information connected by an all-out factor. To make a linear model that catches a period arrangement with a worldwide linear trend, the result variable (Y) is set as the time arrangement qualities or some function of it, and the indicator (X) is set as a period record. Hence a linear equation is formed as:
Y = aX + b
Where b is intercepted on the Y axis when X is 0.
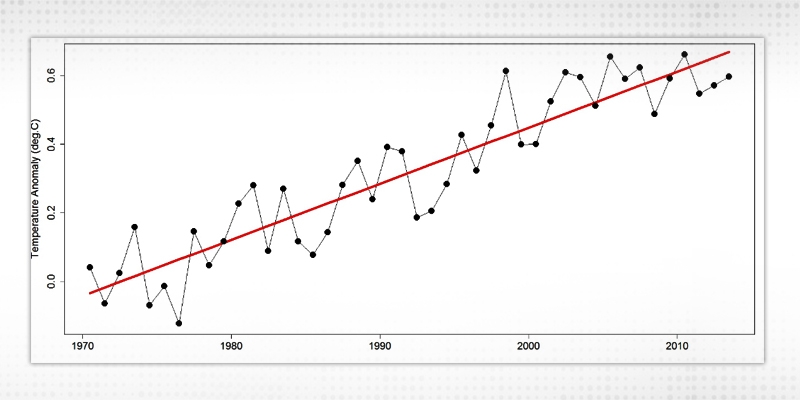
Figure 1 Linear Trends
Read: PCA - A Simple & Easy Approach for Dimensionality Reduction
The exponential trend model is one of the most broadly utilized stochastic procedure models. The exponential model depicts the advancement or degrading process dependent on a condition, for example,
Y = B.eA.t
where Y = debasement; T = time; and A and B = parameters to be assessed by the relapse technique dependent on chronicled information.
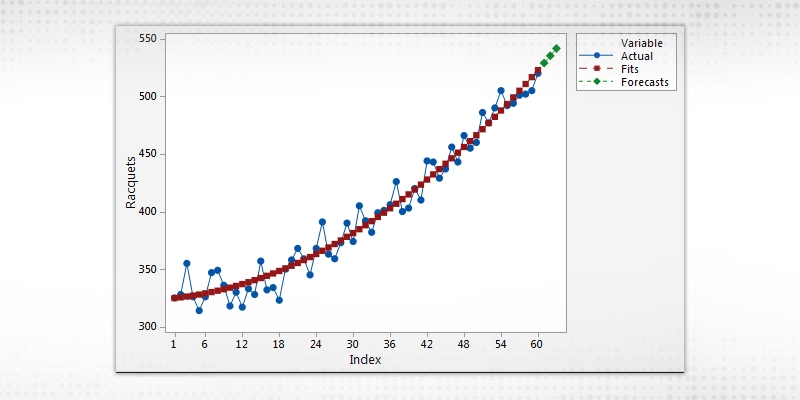
Figure 2 Exponential Trends
Polynomial trends portray an example in the information that is curved or changes from a straight linear trend. It regularly happens in a huge arrangement of information that contains numerous variances. As more information opens up, the trends frequently become less linear, and a polynomial trend has its spot. Graphs with curved trend lines are commonly used to show a polynomial trend.
A polynomial of degree n is an element of the structure
Read: An Ultimate Guide To Python For Data Science (2025)
y = anxn + an−1x n−1 + . . . + a2x 2 + a1x + a0
where the an, an-1, an-2, ….. a2, a1 are real numbers (sometimes called the coefficients of the polynomial).
a0=the intercept
x=the explanatory variable
n=the nature of the polynomial (e.g. squared, cubed, etc.)
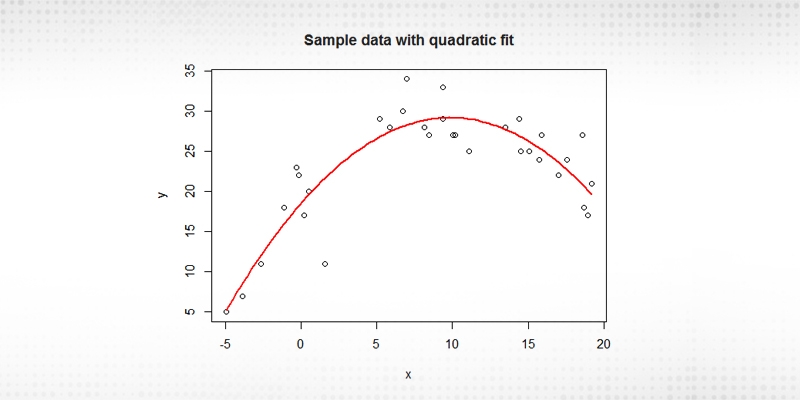
Figure 3 Polynomial Trends
When all is said in done, any sort of trend shape can be fit as long as it has a numerical portrayal. Be that as it may, the fundamental supposition that is this shape is appropriate all through the time of information that we have and during the period that we are going to figure. Don't pick an excessively perplexing shape. Even though it will fit the preparation information, all things considered, it will in truth be overfitting them. To abstain from overfitting, consistently look at the approval execution and cease from picking excessively complex trend designs.
Read: Introduction of Decision Trees in Machine Learning
A seasonal example in a period arrangement implies that periods that fall in a few seasons have reliably sequential qualities than those that fall in different seasons. Models are day-of-week designs, month to month designs, what're more, quarterly examples. Seasonality is caught in a regression model by making another all-out factor that means the season for each worth. This all-out factor is then transformed into fakers, which thusly are included as indicators in the regression model.
At long last, we can make models that catch both trend and seasonality by including indicators of the two kinds. For instance, from our investigation information a quadratic trend and month to month seasonality are both justified. We consequently fit a model to the preparation information with certain indicators. On the off chance that we are happy with this model in the wake of assessing its prescient exhibition on the approval information and contrasting it against options, we would re-fit it to the whole unpartitioned arrangement. This re-fitted model would then be able to be utilized to produce k step ahead figures by connecting the proper month and record terms.
At the point when we utilize linear regression for time series estimating, we can represent examples, for example, trend and seasonality. In any case, conventional regression models don't represent reliance between values in various periods, which in cross-sectional information is thought to be missing. However, in the time series setting, values in neighbouring periods will, in general, be connected. Such a relationship, called autocorrelation, is instructive and can help in improving gauges. On the off chance that we realize that a high worth will, in general, be trailed by high qualities (positive autocorrelation), at that point we can utilize that to modify gauges. We will presently talk about how to process the autocorrelation of a series, and how best to use the data for improving gauges.
Relationship between estimations of a time series in neighbouring periods is called autocorrelation since it portrays a connection between the series and itself. To figure autocorrelation, we process the connection between the series and a slacked adaptation of the series. A slacked series is a "duplicate" of the first series which is pushed ahead at least one time periods. A slacked series with slack 1 is the first series pushed ahead one time period; a slacked series with slack 2 is the unique series pushed ahead double cross periods, and so forth.
Conclusion
Also, its notoriety as a retailer's method, Market Basket Analysis is relevant in numerous different zones:
More and more organizations are finding methods for utilizing market basket analysis to increase valuable bits of knowledge into affiliations and concealed connections. As industry pioneers keep on exploring the procedure's worth, a prescient rendition of market basket analysis is making in-streets across numerous sectors to recognize consecutive buys.
Please leave the query and comments in the comment section.
Read: 10 Most In-demand Skills of Data Scientist to Flourish in Your Career
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Job Description & All Key Responsibilities of a Data Scientist
 566.5k
566.5k
What Is Data Science? A Beginners Guide To Data Scientists
179.7k
A Simple & Detailed Introduction of ANOVA
5.4k
Introduction of Decision Trees in Machine Learning
5.9k
What Is Time Series Modeling? Forecasting Process and Model
6.8k
Receive Latest Materials and Offers on Data Science Course
Interviews









 Jan 10, 2019
Jan 10, 2019 566.5k
566.5k
