
 Mar 01, 2018
Mar 01, 2018  185.5k
185.5k

27
JunMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Hadoop Blogs -
You must have heard about HBase Architecture many times and also must have come across various resources that help to understand about them in a better way. This article is dedicated to people who are still struggling to understand every detail about Hbase Architecture & Main server components. To let you know end to end information about this topic we will discuss the following points;
HBase is meant to provide low-latency random writes as well as reads on top of the HDFS. HBase architecture has one HBase master node i.e. HMaster and has several slaves that we call region servers. Each region server or slave serves a particular set of regions, and a particular region can be served only by a single region server. In HBase, the tables are randomly distributed by the system when they become too difficult to handle. Aligned and sorted set of rows that are stored collectively together is referred as a region. It can be considered as one of the most simple and foundational units of horizontal scalability in HBase.
HBase provides us the convenience of scalability as well as partitioning for highly specific storage and retrieval. It has gained tremendous popularity due to the increase in the popularity of Big data Space. This space can be used to store, manage as well as process huge amount of multi-structured data. When we talk about HBase, it is not only a NoSQL but also a column-oriented database that is built on top of Hadoop in order to overcome any type of limitations of HDFS because it enables faster reads and writes in an optimized manner.
Read: A Beginner's Tutorial Guide For Pyspark - Python + Spark
HBase actually consists of three types of servers in a master-slave type of architecture. Region servers serve data for both the reads as well as writes. Whenever we need to access data, clients communicate with HBase Region Servers at a one go directly without wasting any time. DDL (create, delete tables) operations are very well handled by the HBase Master process. Zookeeper, being a part of HDFS, maintains a live cluster state every time without any fail. The Hadoop Data Node is responsible for storing the data that the Region Server manages. Now entire HBase data is stored in nothing but HDFS files. The Region Servers are associated with the HDFS Data Nodes, and this enables to put the data close to where it is required the most. HBase data can be considered absolutely local at the time when it is written, but the time when the region is moved, it not at all remains local until compaction.
This is mainly responsible for the simple process where regions are assigned to region servers for load balancing in the Hadoop Cluster. Roles and Responsibilities that HMaster fulfill include; 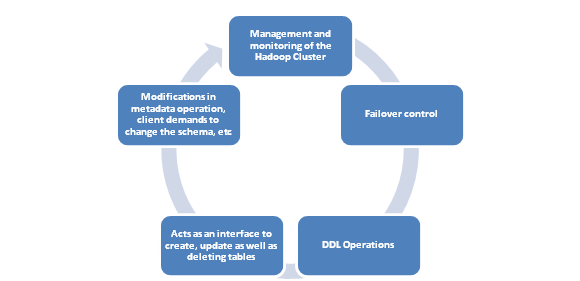
So, basically, HMaster is a lightweight process.
Read: CCA Spark & Hadoop Developer Certification Exam Practice Tests
These worker nodes are solely responsible for any kind of reading, writing, deletion or for any kind of update requests from clients. A region server can serve as much as 1,000 regions. 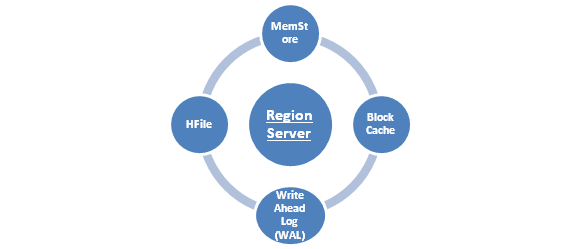 It runs on every node in Hadoop cluster and also works on HDFS DataNode and have various components that include the following;
It runs on every node in Hadoop cluster and also works on HDFS DataNode and have various components that include the following;
Zookeeper is an important essential because HBase uses this ZooKeeper as distributed coordination service for every type of region servers that are already in the function. ZooKeeper is actually a centralized monitoring server that is responsible for maintaining the exact configuration information for providing a synchronized result. 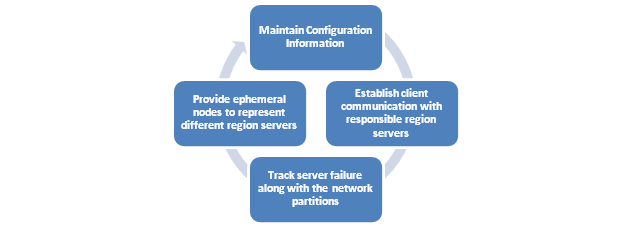 So, when a client wishes to communicate effectively with regions, ZooKeeper must be contacted at the first place in order to connect with the responsible region server as well as the HMaster. Their service is really vast. Take a glance at few services that ZooKeeper is responsible for;
So, when a client wishes to communicate effectively with regions, ZooKeeper must be contacted at the first place in order to connect with the responsible region server as well as the HMaster. Their service is really vast. Take a glance at few services that ZooKeeper is responsible for;
Understanding the fundamental of HBase architecture is not easy. But running the HBase efficiently on top of HDFS in production is the real challenging task when it comes to row key designs manual splitting, monitoring compactions, etc.
Read: A Complete List of Sqoop Commands Cheat Sheet with Example
HBase is an essential component of the Hadoop ecosystem that holds the fault tolerance feature of HDFS. Yes, the HBase provides the much-needed real-time read or write access to data and hence the HBase can be referred to the data storage instead of a database as it lacks on few common features of traditional RDBMS like typed columns, triggers, secondary indexes and advanced query languages.
Understanding HBase Architecture and main server components is not an overnight thing and so we have put maximum efforts to let know Why HBase is in high demand and has gained so much popularity coverings basics of Apache HBase Architectural Components.
Read: How to install Hadoop and Set up a Hadoop cluster?
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Hadoop Course
Interviews












 Jun 30, 2019
Jun 30, 2019 7.5k
7.5k

 7.5k
7.5k