
 Aug 14, 2019
Aug 14, 2019  6.8k
6.8k

23
JunMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Data is the new age currency to business success. Future will belong to the businesses and people who will have the nerve to play the real disruptor and lead change in their spaces driven by data. Data will ultimately write the true success stories of the businesses. It will also be defined by the proactiveness of business models to be able to foresee the emerging realities and challenges and mold them to their advantage. There will be no possibility of growth if you as a business will not be able to truly read between the lines and work around various aspects of data and come up with jaw-dropping insights for all the stakeholders. This is the scope of data analytics, which now seems like a major technological disruption, and will soon become a new norm. Going for an AWS Training Certification will prepare you for future growth.
Data analytics has gained significance in recent years due to rapid growth in data- a trend that will continue to make ripples in the business world for years to come. There are many predictions that suggest that the coming days will be marked by huge growth in data by 2025. Data analytics is thus vital to business growth, and as many as 90 percents of professionals already rely on insights to make more informed business decisions. Thus, businesses that rely on analytics stand a clear chance of success than the ones which do not. Although endowed with many new and obvious advantages, data analytics is an intricate process. Many attempts have been made to ease the whole process to make it more comprehensible and simple. There are many tools available, and Amazon Athena powered by AWS or Amazon Web Services is one of them.
Amazon launched Athena in 2016 as one of the servers. It is a tool for data analytics mainly used for processing complex queries in a short time. As it does not have any server thus all hassles for setting it up are ruled out, and they do not require any management of infrastructure, no setup or data warehouses. It helps make it easy to analyze data on Amazon S3, making use of the standard SQL. It is by the new Athena query engine that the real power of S3 storage is completely unleashed along with no need for maintenance. There is no need for any kind of infrastructure, and querying can be started by the creation of a table and loading of data inside it.
The customer has to ultimately pay only for the queries which are run as there is no need for any infrastructure. Athena can automatically scale up and work on queries to give quick results even in the case of huge datasets and other complex queries. It is helpful in the analysis of structured, semi-structured, and even unstructured data which is stored in Amazon S3. Many dynamic queries can be created for the datasets using Athena. Latter also works with the AWS Glue for giving you a better way to keep the metadata in S3. It is with the help of AWS CloudFormation and Athena that many named queries can be used which will let you name your query and then call it making use of that name. The interactive service from Amazon Web Services can be very useful for Data Scientists, and other developers for taking a quick look at the table and thereby avoiding the hassle of running the entire query. Athena can also be used for fetching the data from S3 and loading it into different stores of data via the Athena JDBC driver, which is used for log storage, analysis, and other data warehousing events. In the next section, we will check through the list of Athena Features. However, to be a reputed AWS professional much depends on the certification you hold, consider going for industry-recognized Cloud computing certifications.
Athena is one of the huge numbers of services which are provided by Amazon. There are many features of Athena which make it highly recommendable for the task of Data Analysis. Presto which is an open-source distributed SQL query engine backs, Athena. Former is also instrumental in running highly interactive analytic queries on all sizes of data sources, i.e. from gigabytes to petabytes. DDL (Data Definition Language) which is written in Apache Hive or either the Table statements are used for facilitating, reading, writing, and even the management of huge and distributed datasets. Although Hive supports SQL the latter also allows for concepts like external tables and data portioning. All the metadata like definitions of tables, names of columns, etc. is stored in the Athena metadata store. Athena also comes in many complex joins, nested queries, and many other window functions. It also supports many complex data types like the arrays and even the struts. It is easy to achieve partition using any key, which also includes the custom keys of date and time.
Various file formats in which data is stored in the form of objects are:
As and when the query is performed, you can obtain the stream of data from Amazon S3 in the same manner as a query is made in a real SQL database. Queries are made either by APIs or the AWS Console. It is by making use of the AWS Console that you can get the running time of the query and scan the data in bytes. In Athena, the worries about scaling, performance, and even maintenance of data are ruled out as there are sufficient resources for having fast and interactive query performance. Queries are automatically run in parallel or petabytes of data, thus most results are returned within seconds. All this is possible as Athena makes use of warm compute pools over many Availability Zones.
Athena can be accessed by either of the three ways:
However, when it comes to learning the nitty-gritty of in-demand skills like Cloud Professionals what is better than the leader in the cloud computing market– Amazon Web Services. Check out our comprehensive AWS Certifications Guide to help you excel in the cloud domain and get an ex-factor for your resume.
Athena is one of the many services provided by Amazon. It has many features which make it highly suitable for Data Analytics. Here are the most prominent ones:
All these features are an addition to its cost-effectiveness. It has a very simple and basic pricing structure. The best part is that you are only making a payment for the queries which you run. The charges are at a rate of $5 per TB of data scanned. All the DDL statements like CREATE, ALTER, DROP, queries used for partitioning, and even the failed queries are free completely with no hidden charges. In case you cancel a query midway then the charges will only be levied for the amount of data that has been scanned till that point. Costs can also be brought down by the compression of many columnar formats and partitions. It is with the help of these techniques that Athena has to scan very less data than Amazon S3. Computation does not have any direct charges, so the total cost estimation is done purely based on the amount of data that you have to work with.
Tip: If cloud computing fascinates you and you want to make a long-term career around it, more specifically in AWS technology then check out the AWS Career Path and gain a complete insight about this most demanded IT profession.
Athena by AWS easily integrates with many Business Intelligence tools like Looker, Tableau, Mode Analysis, AWS QuickSight, etc., and many more for some highly advanced reports and visualizations. All this needs to be considered as it is specifically true for businesses that want the simplicity of making use of Athena for a spot or even ad hoc data analysis. Now, that you have got a taste of AWS Athena, take this 2-minute free AWS Quiz to check your Cloud computing knowledge and stay updated with the latest updates and innovations in AWS.
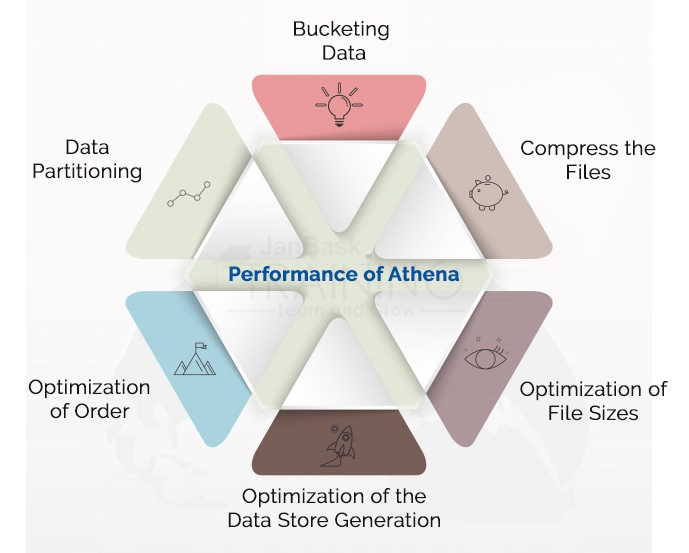
In order to get the maximum from Athena, you may consider structuring your data. Here are a few tips which will help to maximize your Athena performance:
Note: There is always a curiosity in cloud computing and if you are serious about your career in AWS. Don't miss out on these Top 30 Apache spark interview questions and answers that will help you crack your next interview with ease.
So, this is how to tune your performance Anthna. Consider joining a professional AWS Community to connect with the top industry experts and professionals.
Amazon Athena uses the Presto with complete standard SQL support, which also works with many standard data formats, which include CSV, JSON, ORC, Avro, and even Parquet. Athena can take care of much complex analysis, which involves large joins, window functions, and even the arrays. As Athena makes use of the Amazon S3 as the baseline data store, it has high availability and durability with redundant storage of data across many facilities and devices in every facility.
Amazon AWS Athena is one of the most promising data analytics tools by Amazon. Being an interactive service and based on Amazon S3, it makes data analysis easier. Also being serverless, there are no requirements of infrastructure management. It is truly the technology of tomorrow. Give a jumpstart to your AWS professional career by enrolling yourself in a comprehensive AWS Certification Course, today! For more information on such topics, you may refer to JanBask Training.
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Search Posts
Related Posts
How To Create Your Own First Amazon EC2 Instance?
 258.3k
258.3k
AWS Certified SysOps Administrator Associate Certification Complete Guide
228.1k
What is the Salary of an AWS Certified Solutions Architect?
11.6k
Level up You Career With Best Agile Certification: Exam Detail & Preparation Tips
3.9k
AWS Developer learning path - Future Career Scope & Roadmap
219.4k
Receive Latest Materials and Offers on AWS Course
Interviews









 Jul 18, 2024
Jul 18, 2024 258.3k
258.3k
