
 Jun 30, 2019
Jun 30, 2019  7.6k
7.6k

08
AugMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Hadoop Blogs -
Spark has emerged as the most powerful, highly in-demand, and the primary big data framework across the major industries of the world. It has become a robust complement to Hadoop, which was the original choice of technology for big data. This has been possible due to the ability of Spark to handle big data challenges in addition to its accessibility and power. It now has a sound user base of more than 225,000 members and the contribution to code done by over 500 people from 200 different companies. It has become the preferred framework by some mainstream players like Alibaba, Amazon, eBay, Yahoo, Tencent, Baidu, etc.
Rajiv Bhat, the senior vice president of data science and marketplace at InMobi said, “Spark is beautiful. With Hadoop, it would take us six-seven months to develop a machine learning model. Now, we can do about four models a day”. Thus, Spark is an open-source framework for real-time processing, which has become the most running projects by the Apache Software Foundation. It is at present the undisputed market leader in the realm of Big Data processing. It thus has a huge career scope and is worth the deal to become a Spark certified professional.
There is a huge amount of data which is produced in the world of the internet every day, which has to process within seconds. This is made possible by the Spark Real-Time Processing Framework. Latter has become an essential part of our lives as it spans industries like banking for detection of frauds, governmental surveillance systems, automation in healthcare, stock market predictions, etc. Looking at these domains which employ real-time data analytics in a major way:
The most common question which strikes the businesses is what was the need for Spark when Hadoop was there. This can be answered by delineating the concept of batch and real-time processing. While the former rests on the concept of processing blocks of data which have been stored for a certain period and later work on real-time processing model. The MapReduce framework of Hadoop in 2005 was a pathbreaking technology in big data but only until 2014 when Spark was introduced. The main selling proposition of Spark was speed in real-time as it was 100 times faster than the MapReduce framework of Hadoop. Thus, it can be said that Hadoop works on the principle of batch-processing of data which has been stored over some time. Spark, on the other hand, is instrumental in real-time processing and solve critical use cases. Additionally, even in terms of batch processing, it is found to be 100 times faster.
Read: Scala Tutorial Guide for Beginner
Apache Spark is an open-source cluster framework of computing used for real-time data processing. It has a bubbling open-source community and is the most ambitious project by Apache Foundation. Spark gives an interface for programming the entire clusters which have in-built parallelism and fault-tolerance. It has been basically built on MapReduce Framework of Hadoop and extends the same to many more computation types. Some of the salient features of Spark are:
Spark enjoys a well-marked and layered architecture with all the components and layers widely clubbed and integrated with other extensions and libraries. The architecture rests on two primary abstractions:
The Spark Architecture has two main daemons along with a cluster manager. It is basically a master/slave architecture. The two daemons are:
One Spark cluster has only a single Master and many Slaves/ Workers. Individual Java processes are run by the driver and the executors while users can run them on different machines like a vertical cluster or mixed machine configuration or even on the same horizontal spark cluster.
Read: HDFS Tutorial Guide for Beginner
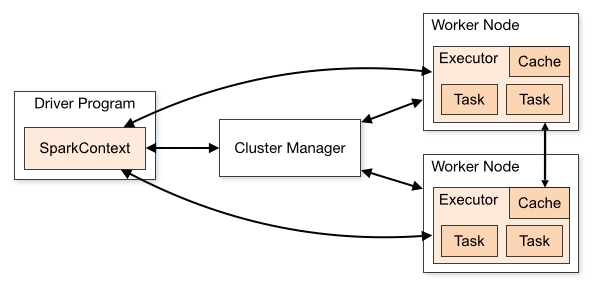
1). Driver: The driver program is the central point which runs the primary () function of the application. It is also the entry point of Spark Shell (Scala, Python, and R). Spark Context is built here. Components of the Driver are:
All these are responsible for translating the spark user code into actual spark jobs which are implemented on the cluster. Roles of the Driver are:
2). Executor: An executor is mainly responsible for executing the tasks. It is a distributed agent. Every spark application comes endowed with its own process executor which run for the complete lifetime of the Spark application. This is known as “Static Allocation of Executors.” It is also possible for the users to choose the dynamic allocation of executors in which the executor are added and removed to match the overall workload. Roles of the Executor are:
Read: Big Data Hadoop Developer Career Path & Future Scope
3). Cluster Manager: The choice of a cluster manager for every application Spark is completely dependent on the goals as cluster managers give a different set of scheduling capabilities. The standalone cluster manager is easier to use while developing a new spark application. There are three types of cluster managers which can be leveraged by a Spark application for allocating and deallocating various physical resources like client spark jobs, CPU memory, etc.
As the client submits a spark application code, it is implicitly converted by the driver into a logical DAG. Various optimizations like pipelining of transformations and then converting the logical DAG into a physical execution plan with a set of stages. It is after the creation of a physical execution plan with various small physical execution units is created known as tasks which are clubbed together and sent to the Spark Cluster.
The Driver then interacts with the cluster manager and holds negotiations for the resources. It is the cluster manager, which helps in the launching of the executors on the slave nodes. The tasks are sent to the cluster manager by a driver based on the data placement. Executors register with the driver program before execution. The driver will monitor these as the application runs. The future tasks are also scheduled by the driver again based on data placement. When driver programs main () method exits or when stop () method, it terminates all the executors and release them from the cluster manager.
Thus, the architecture enumerates its ease of use, accessibility, and the ability to handle big data tasks. The architecture has finally come to dominate Hadoop mainly because of its speed. It finds usage in many industries. It has taken Hadoop MapReduce to a completely new level with few shuffles in the processing of data. The efficiency 100X of the system is enhanced by the in-memory data storage and real-time processing of data. Also, the lazy evaluation contributes to the speed. It is wise to upgrade yourself the same as it holds great potential for the training. For more insights on the same and related technologies, please visit JanBasktraining.com
Read: ELK vs. Splunk vs. Sumo Logic – Demystifying the Data Management Tools
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Hadoop Course
Interviews









 Mar 28, 2024
Mar 28, 2024 242.7k
242.7k

 242.7k
242.7k