
 Jul 26, 2023
Jul 26, 2023  630.8k
630.8k

10
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- SQL Server Blogs -
If you are looking for the most essential data modeler interview questions and answers for freshers and experienced, you have reached the right place today. When plenty of technology companies use it worldwide, Data Modeling enjoys a share of 15.43 % in the global market. Indeed, you have the opportunity to move ahead in your career with Data Modeling skills and a set of top Data Model interview questions and answers. If Data Modeling is new to you or you want to know the Data Modeling concept in depth, then join the SQL Server Training & Certification course at JanBask Training to give a new definition to your career.
JanBask Training mentors have prepared a list of frequently asked data model interview questions that will help you in getting your dream job as a Data Modeling Architect. So without further delay, let’s proceed to know some of the data modeling interview questions and their answers.
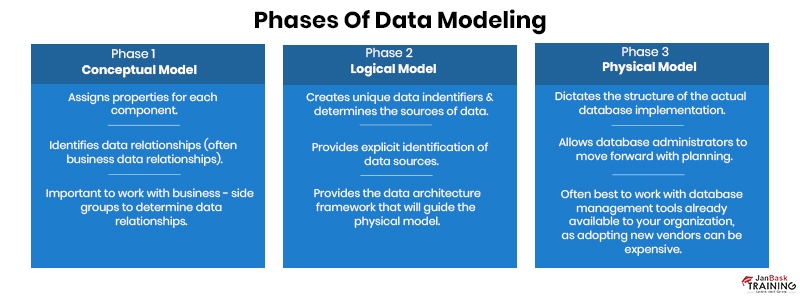
Ans:- A Data Model is the conceptual representation of a database's business requirements or physical attributes that help communicate the business requirements with clients. Data models are optical displays of the enterprise’s data components and the relationships between them. By letting describe and organizing the data in terms of related business methods, the data model helps to develop proper information systems. It could be the physical data model and the logical data model, enterprise data model, conceptual data model, relational data model, OLTP data model, etc. The three prime elements included in a data model are data structures, operations, and integrity constraints meant for the operations and framework.
Ans:- The approach that is used to prepare a data model is called Data Modeling. Data modeling is the method of producing a smooth sketch of the software system and the data components it comprises, utilizing text and symbols to show the data and the workflow. Data models offer a blueprint to create a fresh database or revamp an older application.
Ans:- Data models are optical displays of the enterprise’s data components and the relationships between them. By letting describe and organizing the data in terms of related business methods, data models help to develop proper information systems. It could be the physical data model and the logical data model, enterprise data model, conceptual data model, relational data model, OLTP data model, etc.
Ans:- A physical data model contains a Table, key constraints, columns, unique key, foreign key, default values, indexes, etc. A physical data model refers to the database-particular model that showcases relational data objects comprising tables, columns, and primary as well as foreign keys along with the relations. A physical data model must be utilized to produce DDL statements which can be further incorporated into the database server.
Ans:- A logical data model refers to a model that does not correspond to the database elaborating things about which the firm wishes to gather data and the relation among those objects. The three kinds of logical data models include relational data models, network data models, and hierarchical models. A logical data model is related to the business requirements and is used to implement the data. A logical data model contains an entity, attributes, primary key, alternate key, Inversion keys, rule, definition, business relation, etc.
Ans:- A physical data model contains the physical attributes of a database. The database performance, physical storage, and indexing strategy are essential considerations of a physical data model. The main component here is a database. The approach that is used for creating a physical data model is called physical data modeling.
Ans:- A logical data model launches the framework of data components and the connections between them. It does not rely on the physical database that delineates the way the information will be implemented. The logical data model works as a blueprint for the deployed data. A logical data model is related to the business requirements and is used to implement the data. The approach that is used for creating a logical data model is called logical data modeling. Logical data modelling also called information modelling assists organizations to produce a visual comprehension of the data they should process to properly accomplish certain tasks and business cycles.
Ans:-
|
Logical Data Model |
Physical Data Model |
|
1). A logical data model will tell the business requirements logically. 2). A logical data model is responsible for the actual implementation of data stored within a database. 3). A logical data model contains an entity, attributes, primary key, alternate key, Inversion keys, rule, definition, business relation, etc. |
1). A physical data model will tell you about the target database source and its properties. 2). A physical data model will tell you how to create a new database model from the existing one and apply the referential integrity. 3). A physical data model contains Table, key constraints, columns, unique key, Foreign Key, default values, indexes, etc. |
Further, if you want to interact with similar minds & learn more. Join our JanBask SQL Community to gain valuable information on SQL Server, Oracle, and MySQL. You can find various tips, tricks, and tutorials designed to help you with your Data Modeling queries.
Ans:- A database consists of multiple rows and columns, called a table. Further, each column has a specific datatype, and constraints are set for the columns based on conditions. So an entity refers to the object that is present in the actual world. Consumer, fridge, and pencil are examples of entities. They are kept in the database and they must be identifiable and distinct from the rest of the group.
Ans:- A Column is defined as the vertical alignment of data and information stored for that particular column. A column-store database management system refers to a DBMS that indexes every column of the table, gathering the indexes in line of row data. The highest limit is 1024 columns in the table.
Ans:- A row is a set of tuples or records, or it could be taken as the horizontal arrangement of the data. Horizontal arrays are called rows in the matrix. However, in DBMS, columns are called fields. A row is a single category of related data existing in the table. Relational databases comprise tables containing rows and columns.
Ans:- ER is a logical representation of entities and defines the relationship among entities. Entities are given inboxes, and the relationships are given by arrows. It is a graphical display that shows connections among individuals, objects, areas, ideas, or events within the IT system. The ERD utilizes data modeling methods that can smoothen business processes and act as the concrete ground for a relational database.
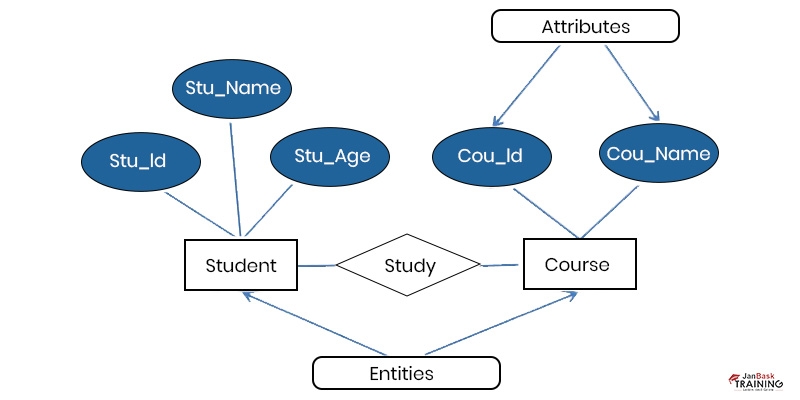
In the above image, there are two entities namely Student and Course, and their relation. The relation defined is many-to-many, since a course can be taken up by many students, and a student can take more than one course. Student entity has attributes- Stu_Id, Stu_Name, and Stu_Age. The course entity possesses attributes like Cou_Id and Cou_Name.
Q13). What do you understand by the primary key constraint in a database?
Ans:- The primary key constraint is set on a column to avoid null values or duplicate values. In simple words, a column containing unique items can be defined as the primary key constraint. It could be the bank number, security number, or more. The primary key constraint denotes that the constrained columns’ values should specially detect and recognize every row. A table can contain a single primary key, but it may possess various unique constraints.
Ans:- When more than a single column can be defined as the primary key constraint, it becomes composite. A composite key denotes various columns for a primary key or foreign key constraint. Here two tables are created. The first one possesses a composite key which behaves like the primary key and the next table contains a composite key behaving like a foreign key.
Ans:- The Primary key can be defined for the parent table, and the foreign key is set for the child table. The foreign key constraint always refers to the primary key constraint in the main table. A foreign key refers to a column existing in a table where values should be compatible with the values of a column from another table. Foreign key constraints impose referential integrity, which states that if column value A belongs to column value B, then column value B should be present.

In the above figure, Stud_Id is common but possesses a separate key constraint for the two tables. The field Stud_id comprises the primary key since it is detecting the rest of the field of the Student table. However, Stud_Id is a foreign key belonging to the De[artment table as it acts as a primary key attribute for the Student table.
Ans:- When a numerical attribute is enforced on a primary key in a table, it is called the surrogate key. This could be defined as a substitute for natural keys. Instead of generating primary or foreign keys, surrogate keys are generated by the database, and they are further helpful in designing the SQL queries.Surrogate keys are distinct identifiers for a record or object in the table. It is identical to the primary key but it is not taken from the table data. Rather the object produces this certain key
Q17). Why is a composite word added before any key constraint?
Ans:- Keys and Constraints are protocols that state what data values are permitted in a few data columns. They are vital database concepts and are a portion of the database’s schema concept. When the same constraint is enforced on multiple columns, the composite word is added before that particular key constraint.When the same constraint is enforced on multiple columns, the composite word is added before that particular key constraint.
Q18). Name a few popular relationships within a data model.
Ans:- These are identifying, non-identifying, and self-recursive relationships in a data model.
An identifying relationship is one where an example of the child entity is detected through the linkage with the parent entity. This means that the child entity is reliant on the parent entity for its survival.
A non-identifying relation is where the relation between two entities is present but the child entity is not detected through the linkage with the parent entity. This implies that the child entity is independent of the parent entity for their survival.
The self-recursive relationship is when there is a relation between two entities of identical type. This implies that the relation is between various instances of the identical entity type.
Ans:- As you know, the parent and child table is connected with a thin line. When the referenced column in a child table is a part of the primary key in the parent table, then those relationships are drawn by a thick line and named as the identifying relationships in a data model. An identifying relationship is the one present between two entities where an example of a child entity is detected through the linkage with the parent entity. This implies that the child entity is relied on the parent entity for its survival and cannot live without it.
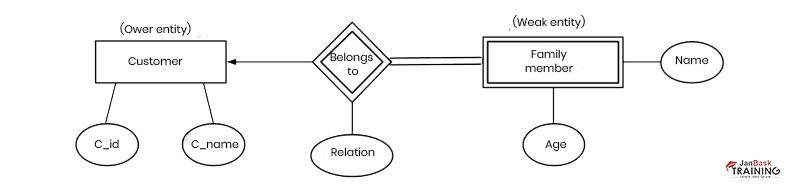
Ans:- In most cases, a parent table and the child table are both connected with a thin line. When the referenced column in a child table is not a part of the primary key in the parent table, then those relationships are drawn by a dotted line, and it is named the non-identifying relationships in a data model. In other words,a non-identifying relation is where the relation between two entities is present but the child entity is not detected through the linkage with the parent entity. This implies that the child entity is independent of the parent entity for their survival.
Q21). How will you define cardinality in a data model?
Ans:- Cardinality is an arithmetic concept. It converts into the count of components present in a set. Cardinalities are used to define relationships; they could be one-to-one, one-to-many, many-to-many, etc. The higher the cardinality value, the more unique values within a column. Cardinality generally shows the relation between the data in two separate tables, by enhancing the number of times a certain entity happens as compared to a different one. The database of an auto repair shop can display that the mechanic performs tasks with various buyers regularly.
Ans:- This is a standalone column in the table connected to the same table's primary key and is named the self-recursive relationship here. Where there is a relation between two given entities of identical type, it is termed a recursive relation. This also indicates that the relation is between various instances of the identical entity type. A worker can supervise numerous workers. So it is a recursive relation of entity worker within its own self.
Ans:- Here, all-important entities are defined as related to an enterprise. You should first understand the essential data elements and their possible relationship. This relationship is defined as enterprise data modeling. To understand this model in the best areas, you should divide the data models into subject areas. The enterprise data model is a kind of unification structure that circumferences the majority of the data of an enterprise. The enterprise framework can contain enterprise-wide data structures that are conceptual, scientific, or physical models.
Ans:- The relational data model is the visual representation of data objects within a database. The approach used to create a relational data model is called relational data modeling. The relational model refers to the scientific data structures- including the data tables, views, and indexes that are segregated from the physical storage frameworks. This segregation implies that database administrators can handle physical data storage without hampering the accessibility of the data as a scientific framework.
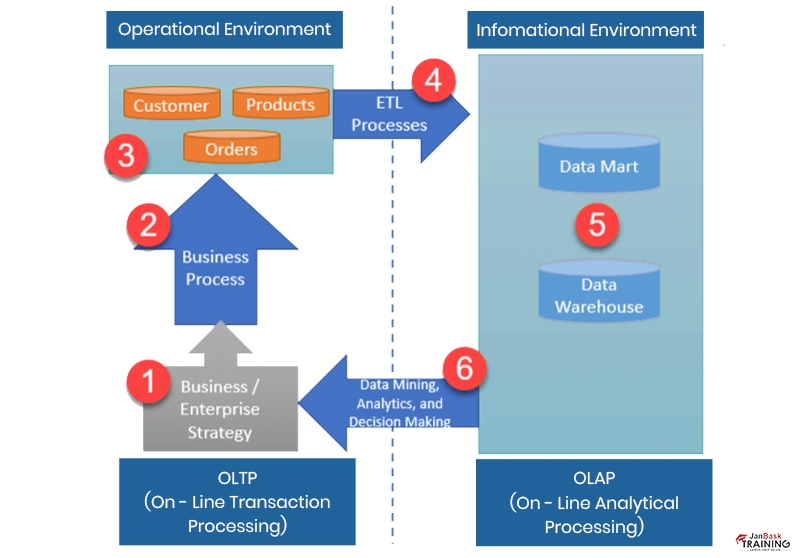
Ans:- OLTP or Online Transaction Processing is an approach where the data model is specially created for the transactions, and the approach is named OLTP data modeling. Data modeling refers to the way of stating and arranging the framework, connections, and constraints of data existing in the database. It is a vital stage to design and optimize database systems, exclusively for online transaction processing applications.
Ans:- It will give you detailed information related to the entity, attributes, or relationships between them. A conceptual data model must be used to state and convey supreme-level connections between ideas and entities. They support the firm to view the data and the connections between various kinds of data. They are visual showcases of data that signify the story of how a company works under certain situations. This lets the companies evade oversights that may cause major issues.
Ans:- This is a rule imposed on the data. Different types of constraints could be unique, null values, foreign keys, composite keys or check constraints, etc. Constraints refer to the protocols or rules applied to the database tables to preserve the coherence, righteousness, and stability of the data. They can be deployed to impose data linkages over tables, check that data is distinct, and pause the intervention of wrong data. A database requires constraints to be trustworthy and of supreme quality.
Ans:- This constraint is added to avoid duplicate values within a column. Unique constraints refer to the rules that the values of the key are authentic only when they are distinct. A key that is constrained to possess distinct values is known as a unique key. A unique constraint is powered by utilizing a unique index. The unique constraint also guarantees that the values in the column are varied.
Q29). Define the check constraint.
Ans:- A check constraint is helpful in defining the range of values within a column. It is a rule that denotes the values that are permitted in a single or more column of each row of the base table. A check constraint can be defined to guarantee that the values in the column comprising ages are positive numbers. A check constraint is meant to restrict the value range that can be positioned in the column.
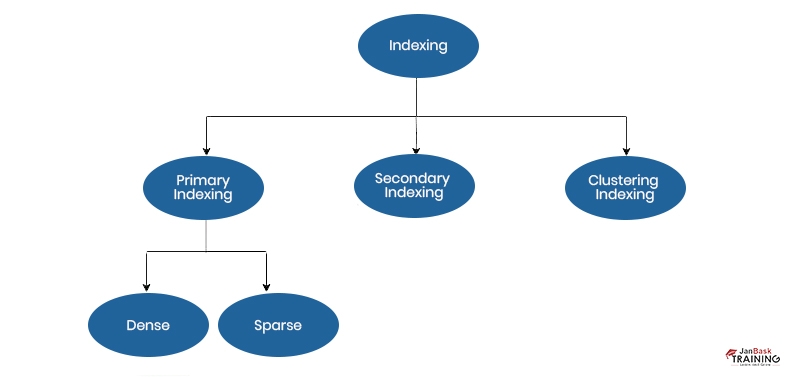
Ans:- An Index is composed of a set of columns or a single column that is needed for fast retrieval of data. Index is a replica of chosen columns of data, that is created to allow a proper search. It usually contains a key or direct link to the actual row of data from where it was duplicated, to facilitate the entire row being extracted properly. There are two primary kinds of indexing ways. They are Primary indexing and Secondary indexing.
Ans:- A sequence could be defined as the database object needed to create a unique number. Sequences are meant for the task of producing distinct key values. Applications can deploy sequences to evade probable concurrency and performance issues arising from column values needed to record values.
Ans:- To simplify the data based on standard rules, database normalization is needed. It is the way of arranging data into a tabular form in a way so that the outcomes of utilizing the database are always clear and as desired. The database can be designed to adhere to any kind of normalization like 1NF, 2NF, and 3 NF. Normalization also refers to the way to reduce redundancy from a relation. An overabundance can lead to insertion, removal, or upgradation anomalies. Hence normalizations assist in erasing the excessiveness in relations.
Q33). What do data modelers use normalization for?
Ans:- The purpose of normalization is to:
Ans:- Denormalization is the technique of adding redundant data to an already normalized database. This step improves read performance at the expense of write performance. It is the way of including precomputed extra data to an elsewhere normalized relational database to refine the readability of the database. Normalizing a database means erasing overabundance so that one copy is present of every kind of information. Denormalization is utilized by the database managers
Ans:- Metadata describes data about the data. Shows what data is actually stored in the database system. It is the data offering information regarding one or more aspects related to the data. It is meant to give a list of the fundamental knowledge about data that can turn to recording and performing with certain data simpler and smoother. Ways of generating the data is an instance of metadata.

Ans:- The data mart is a summary version of the data warehouse designed to be used by specific departments, units, or user groups within your organization. B. Marketing, sales, HR, or finance. It is the data storage process that comprises data as per the company’s business unit. It also has a tiny and chosen segment of the data that the firm gathers in a huge storage system. Firms utilize data mart to examine department-related data more properly. It is a general type of data warehouse that concentrates on one subject or stream of business like sales, and marketing. They collect data from lesser sources as compared to data warehouses.
Ans:- OLTP System Example:
Ans:- Types of normalization are
Ans:- Forward engineering is a technical term used to automatically transform a logical model into a physical working device. It is the way of producing a database schema from a physical structure. It allows the association of the data model with the database when physical alterations have been done to the data structure, like including, excluding, or modifying entities, fields, indexes, names, and connections.
Ans:- Data modeling refers to the way to build a visual display of either the entire information system or segments of it to convey interactions between data points and framework. A data cube that stores data as aggregates. It helps users to analyze data quickly. PDAP data is stored in a way that facilitates reporting. Data modeling occurs in a few steps selecting a data source, selecting datasets, selecting attributes, utilizing the relation tool, hierarchies, roles, and finalization.
Ans:- A snowflake schema is an arrangement of dimension and fact tables. Both tables are typically further divided into separate dimension tables. It is a multi-dimensional data structure that is an augmentation of the star schema, where dimension tables are fragmented into subdimensions. Snowflake schemas are usually deployed for business intelligence and reporting in OLAP data warehouses, and data marts. The target is to normalize the denormalized data present in the star schema. This settles the write command slow-downs linked with star schemas.
Ans:- A sequence clustering algorithm collects a set of data containing paths and events that are similar or related to each other. It is a special kind of algorithm that blends sequence analysis with clustering. This algorithm can be utilized to investigate the data that has events that can be connected sequentially. The algorithm detects the most ordinary sequences and executes clustering to detect sequences that are identical. There are four main techniques of clustering. They are centroid-based, density-based, distribution-based, and hierarchical-based clustering.
Ans:- Discrete data is finite or defined data. B. Gender, phone number. Continuous data is data that changes continuously and regularly, for example, Age. Discrete data and continuous data are kinds of quantitative data. The prime distinction is the kind of data they showcase. Discrete data only displays data for a certain event, but continuous data displays modern advancements in data over a time period. The count of children and their shoe size are examples of discrete data but their stature measurements are continuous data.
Ans:- Time Series Algorithms are methods of predicting continuous values of data in a table. For example, employee performance can predict benefits and impact. They offer algorithms to forecast upcoming trends such as Autoregressive Integrated Moving Average, Exponential Smoothing, and Seasonal Trend Decomposition. Time series is a machine learning method that predicts the target number as per the previous record of target values. It is a unique way of regressions.
Ans:- BI (Business Intelligence) is the set of processes, architecture, and technologies that transform raw data into meaningful information that drives meaningful business action. A suite of software and services for transforming data into actionable information and knowledge. It means the methodical and technical framework that gathers, keeps, and examines the data created by a firm’s activities. It is a widely used term that circumferences data mining, process analysis, and elaborative analytics. Business Intelligence intensifies how a firm carries out decision-making by deploying data to respond to questions about the firm’s present and past.
Ans:- Data warehousing is the process of collecting and managing data from a variety of sources. It provides meaningful insights into the enterprise. Data warehousing is typically used to connect and analyze data from disparate sources. It is the core of a BI system designed for data analysis and reporting. It is a kind of data management system that is created to allow and assist business intelligence works, specifically analytics. Data warehouses are purely meant to execute queries and analysis and also comprise huge amounts of previous data.
Q47). What is the junk dimension?
Ans:- A junk dimension combines two or more related cardinalities into a single dimension. These are typically boolean or flag values. It is an easy way of categorizing specifically low-cardinality flags as well as indicators. The flags and indicators are erased from the fact table by producing an unreal dimension while positioning them into a proper dimensional structure. If the indicator fields are kept in the fact table, we need to create multiple small dimensional tables, and the quantity of data kept in the fact table will rise enormously, resulting in performance disruptions. Here the junk dimension comes to the rescue.
Ans:- The frequency of data collection is the frequency of data collection. It also goes through different stages.
These phases are-
Ans:- Cardinality is a numeric attribute of the relationship between two entities or an entity set. Database cardinality means the range of components organized in tables and rows. It also implies to the calculation performed to identify the components in the set, detect connections among various tables, and detect the count of values in the tables. The cardinality of the set can be limited or infinite.
Ans:- The essential fundamental relationships of the different types are
Ans:- Granularity represents the level of information stored in a database table. To make it high or low, you can use a table that contains a transaction-level table and a fact table. Particle size is also a measure of the smallest dataset that each component/task/application can handle individually. Multiple granularity means to hierarchically fragment the database into certain blocks which may be locked. The multiple granularity protocol intensifies concurrency and decreases lock overhead. It further preserves the record of what and how to lock and turns it smoother to decide whether to lock or unlock a data item.
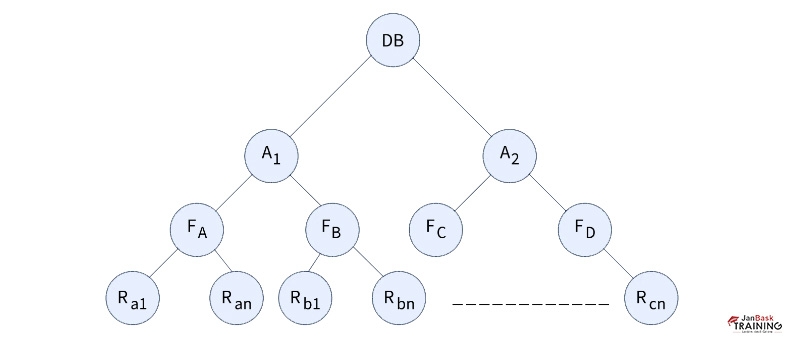
Here in the figure, the first stage displays the whole database having various records. The next layer contains nodes that display areas. The children of the next stage are called files. The lowest stage in the tree is called records. So the four levels are Database, Area, File, and Record.
Ans:- Data sparseness refers to the number of empty cells in the database. It represents the amount of data available in a particular dimension of the data model. Insufficient information consumes a lot of space to store the aggregate. Sparse data refers to a variable where the cells do not have real data within data analysis. Sparse data is null or contains a zero value and they are varied from absent data since sparse data are displayed as empty or zero but absent data do not display what the values are. The data sparsity issue happens when the document is shifted to vector form.
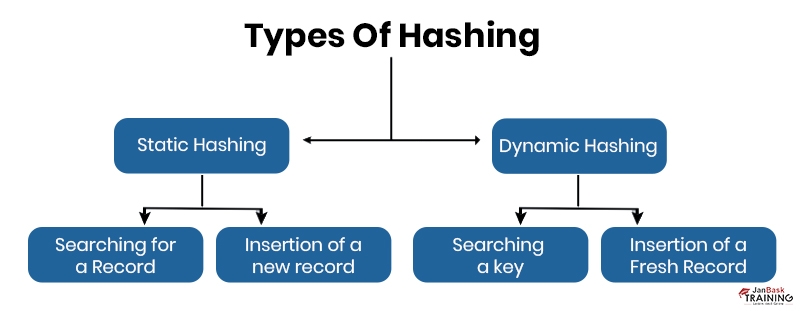
Ans:- Hashes are helpful for searching index values to get the data you need. It is used to calculate the direct location of the data using the index. It is the way to convert a specific key or a string of characters into a different value and integer. This is generally displayed by a smaller, fixed-length value or key that shows and turns it simpler to detect and use the actual string.
Ans:- OLAP stands for On-Line Analytical Processing and is designed to help managers, executives, and analysts gain insights faster, more confidently, more consistently, and more interactively. It is a type of technology that makes OLAP used in intelligent solutions, including planning, budgeting, analysis, forecasting, simulation models, and more. OLAP helps clients consider multiple dimensions and perform analysis to provide insights that help them make better decisions.
Ans:- A recursive relationship occurs when there is a relationship between the entity and itself. These relationships are complex and require a more sophisticated approach to mapping data to schemas. Consider the case where a doctor is flagged as a healthcare provider in a healthcare database. Now, when a doctor gets sick, he has to see another doctor as a patient, leading to a recursive relationship. To do this, add a foreign key to the health center number on each patient record. It should be noted that such entity-related recursion has an exit path.
The errors that are faced in Data Modeling include the following:
Ans:- It is possible to break down entities into various sub-entities or categorized them by certain attributes. Every sub-entity has valid features and is referred to as a subtype entity. Features that are present in each entity are positioned in a greater or super-level entity which is known as a supertype entity. In other words, a supertype entity refers to a data structure entity that contains one or more different entities that perform like subtypes. The higher-level entity is called the parent entity or the supertype one and every lower-level entity is called the child or subtype entity.
Ans:- NoSQL databases are more beneficial than relational databases owing to the following reasons:
Ans:- Conformed dimensions refer to the dimensions that carry the same meaning and values over various fact tables and subject areas. A conformed dimension related to time can possess the same features and stages of granularity for sales, and inventory. A conformed dimension in data warehousing implies a dimension that lets the facts and methods be classified and elaborated in the same manner over various data marts so that there is a constant report across the company.
Ans:- Data mining refers to a multi-disciplinary potential that utilizes machine learning, statistics, Artificial Intelligence, and database technology. It refers to inventing previously unrecognized connections existing among the data. Data mining also includes the way to detect anomalies, styles, and bonds within huge datasets to forecast the results. A wide set of methods can be used to utilize the predictions to elevate revenues, enhance customer relationships, and decrease risks.
Ans:- The method of authenticating and examining a model which would be utilized to forecast testing and authentication results. It can also be utilized for machine learning, AI, and also statistics. It is a very common statistical method that is a type of data-mining procedure that performs by examining previous and present data and producing a model to predict upcoming outcomes.

Ans:- Hierarchical DBMS refers to a database where the model data is arranged in a tree-like pattern. Data is gathered in a hierarchical form. Data is shown utilizing a parent-child connection. Here parents may possess numerous children, while children possess a single parent. A hierarchical structure implies that the data are visualized as a set of tables, or categories that create a hierarchical connection.
Ans:- The disadvantages of the hierarchical data model are as follows:
Ans:- The process-driven approach utilized in data modeling adheres to a stepwise technique on the connection between the entity-connection model and organizational method. Process-driven also implies the capacity to do a task independently by adhering to a linked method constantly. This capacity calls for simultaneously performing the task, without evading, including, or changing steps and also without the requirement for external control.
Ans:- The benefits of utilizing data modeling are as follows:
Ans:- UML stands for Unified Modelling Language. It refers to a usual purpose, database development, and modeling language in the domain of software engineering. The prime objective is to offer a usual method to view system design. It is not any programming language but a range of rules that are meant to sketch diagrams. UML has now traced its path into documenting various business workflows.
Ans:- The network model refers to a model that is created on a hierarchical model. It facilitates greater than one connection to link records, which shows it contains various records. It is normal to create a range of parent records and child records. Every record can connect to various sets that allow you to execute intricate table relations. A network model is seen as a flexible method to showcase objects and their connections.
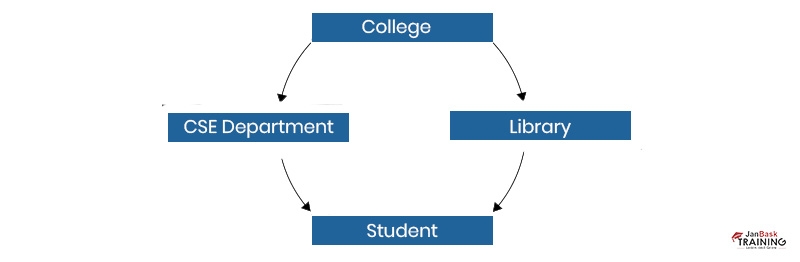
In this figure, the Student entity contains two parents. They are the CSE department and Library. The CSE department and Library comprise the same parent namely College.
Ans:- When greater than one field is utilized to display a key, it is known as a compound key. A compound key resembles a composite key where two or more fields are required to produce a distinguished value. However, a compound key is generated when two or more primary keys from various tables are existing as foreign keys in an entity. The foreign keys are utilized to properly detect every record.
Ans:- The advantages of utilizing keys are as follows:
Ans:- An alternate key refers to a column or set of columns existing in a table that simply detects each row present in the table. A table can contain various options for a primary key, however, only a single one can be made the primary key. Every key which is not categorized as primary key is termed an alternate key. For instance, supposing an example of a student it can comprise NAME, ROLL NO., and CLASS. So, ROLL NO< refers to the primary key, and others in the column are termed as alternate keys.
Ans:- The features of DBMS are as follows:
Ans:- RDBMS stands for Relational Database Management System. It refers to a software that is emant to gather data in the pattern of tables. Here, data is handled and gathered in rows and columns, which are called as tuples and attributes. RDBMS is a rich and potent data management system which is utilized broadly all over the world. Also, RDBMS are dependent on the relationship model, an exciting, direct method to showcase data in a tabular form.
Ans:- The disadvantages of the Data model are as follows:
Ans:- The circumstance where a secondary node chooses a goal utilizing ping time or when the nearest node is a secondary one, is termed as chained data replication. It comprises a new way to unite clusters of fail-stop storage servers. The style is meant to assist huge-scale storage services that possess great throughput and accessibility without sacrificing vital consistency. Chained data replication also implies the method where the non-official data is duplicated into different non-official data.
Ans:- A virtual data warehouse offers an accumulated visualization of the entire data. A virtual data warehouse does not include previous data and it is held as a logical data model containing metadata. Virtual Data Warehousing also refers to the compute clusters that enhance the advanced data warehouse. It is an independent compute asset that can be used anytime to execute SQL and DML and then switched off when not required.
Ans:- Snapshot refers to an entire visualization of data at the moment when the data extraction method starts. A snapshot can be utilized to record activities. For instance, when a worker tries to modify his address, the data warehouse can be signaled for a snapshot. This implies that every snapshot is taken when a certain event is triggered. A storage snapshot refers to a range of reference markers for data at a certain moment. It behaves like an elaborate table of contents, offering the user with available data copies that they can view later.
Ans:- The power of the system to retrieve, clean, and store data in two ways is known as a bi-directional extract. Bi-directional extract offer upgrades that allow the process of data loading to speed up. Also, since regular updates are fetched helpfully, firms can utilize the data well to establish the latest products and generate market strategies.
Ans:- Data model and the related data such as entity definition, feature definition, columns, and data types, are gathered in the repository, which can be easily accessed by data modelers and the whole team also. It is also known as a data library or archive that contains a huge set of Database frameworks comprising various Databases that collect, handle, and gather various datasets to be allocated, examined and reported.
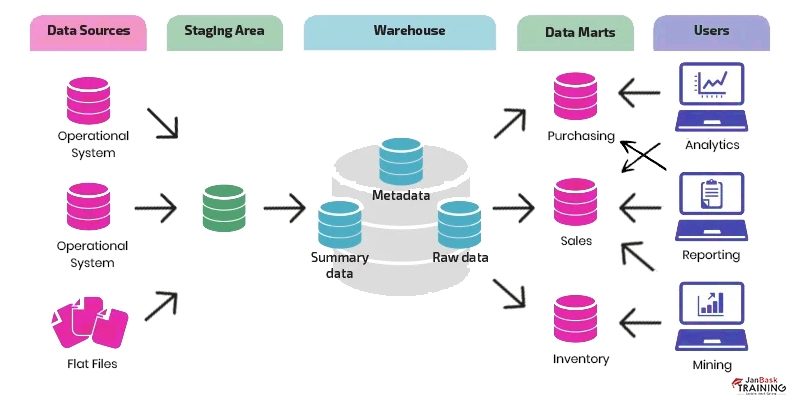
Ans:- In star flake schema you need to enter the required facts and the primary keys of the dimensional tables in the Fact table. Fact tables are the unification of the entire dimension table key. Here, every dimension table is attached to the fact table with the help of a foreign key relation. This lets the users query the data present in the fact table through attributes from the dimensions tables. For instance, a user can wish to view sales revenue by product classification, or by place and time.
Here, the fact table is placed at the mid-point that comprises keys to each dimension table such as Dealer_ID, Model ID, Product_ID, and various other attributes such as revenue and Units sold.
Ans:- A Recursive relationship happens when there is a connection between the entity and itself. For instance, a single-to-many recursive relation happens when a worker is the manager of another worker. The worker entity is connected to itself, and there exists a single-to-many connection between one worker and other workers. Due to the highly intricate behavior of these connections, there are intricate ways of mapping them to a schema and showing them in one sheet.
Ans:- The kinds of dimensions in data modeling are mentioned below:
Ans:- A factless fact table refers to a table without facts. They just contain dimensional keys, and they grab events that happen at the information stage and not at the computation stage. The many-to-many links between dimensions are caught in the factless fact table, comprising no numerical or textual facts. They are usually needed to document events or data about coverage. They are helpful to track and observe a method of gathering data. There are two kinds of factless fact tables, one that elaborates happening and the other describing situations.
Ans:- A critical success factor (CSF) refers to a specific aspect or component that a group, department, or firm must properly use and intensify to suffice the strategic goals. They promote an elevated value for products and services and helpful results. The importance arises from the fact that they act as a roadmap for the firm and the probable method to know what the results entail is to examine and state a critical success factor. The four kinds of CSF are Environmental CSF, industry CSF, Temporal CSF, and Strategy CSF.
Ans:- Dimensional Modeling refers to a data model style that is especially helpful for data storage in a warehouse. The target of dimensional modeling is to create the database in a more intense way to fetch data. The advantage of using a dimension model is that it facilitates you to gather data in a way that makes it smoother to gather and fetch data once it has been stored in the warehouse. Various OLAP systems use a dimensional model as the data model. Dimensional modeling refers to the method that utilizes Dimensions and Facts to keep the data in the warehouse.
Ans:- The CAP theorem displays that no distributed system can guarantee C, A, and P simultaneously. In other words, it denotes that a distributed system cannot offer more than two assurances. Here C stands for consistency. It denotes that the data must be consistent after an activity. After refining the database, all the queries must return an identical outcome. A stands for availability. There must not be any downtime with the database and it must remain active. P stands for partition tolerance. Even when interaction is inconsistent between the servers, the system must be functional.
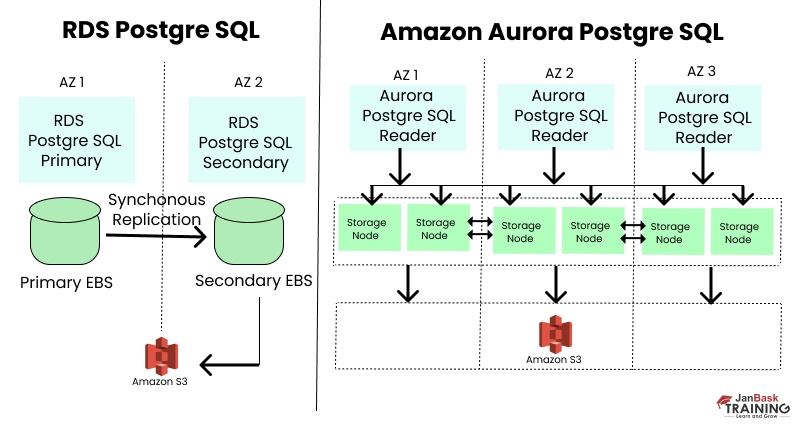
Ans:- The Amazon RDBMS service refers to the web service that is meant for arranging, tackling, and scaling a relational database in the cloud system. Standard relational database engines are assisted by Amazon RDS, which is handled, stretched, and accessible on demand. RDS manages time-taking management tasks, letting you concentrate on the application instead of the database. Amazon RDS lets you encrypt the databases utilizing keys you control through AWS key management service. Data kept at rest in the storage is encrypted along with the backups and snapshots on the database instance working with Amazon RDS encryption.
Ans:- Amazon Aurora is a high-availability, computed failover relations; database engine that assists MySQL and PostgreSQL. Amazon Aurora is a mixture of MySQL and Postgres. Aurora is a multi-threaded, multiprocessor database engine that enhances working, presence, and operational intensity. It does not use a write-ahead log but has a crash recovery scheme. Amazon also offers the attribute to replicate data from the Amazon Aurora database to a MySQL or Postgres database on the identical instance, letting you utilize the two databases simultaneously.
Ans:- While cooperating with huge businesses with greater than 10,000 records, you can come over the problem of data skew. Professionals mention a condition called ownership data skew when one person possesses various records. The users will face performance issues when working on upgrades. This happens when the maximum count of records for one certain object is possessed by one user or members of one role.
Ans:- The data retention period is the prime component of Snowflake Time Travel. Snowflake preserves the earlier state of the data in a tabular form when it is altered, such as when data is removed or objects comprising data are eradicated. Data retention states how long previous data will be maintained to assist Time Travel operations. The original retention period for Snowflake accounts is a single day.
Ans:- The connections launched between various data tables to properly organize the data are called data models. There are certain data types, columns, associations, and tables available in the data model. The data models present in Power Pivot assist with one-directional connections that are one-to-many. Power Pivot utilizes the SSAS in-memory Vertipaq compression model where the client system’s in-memory storage contains the data models.
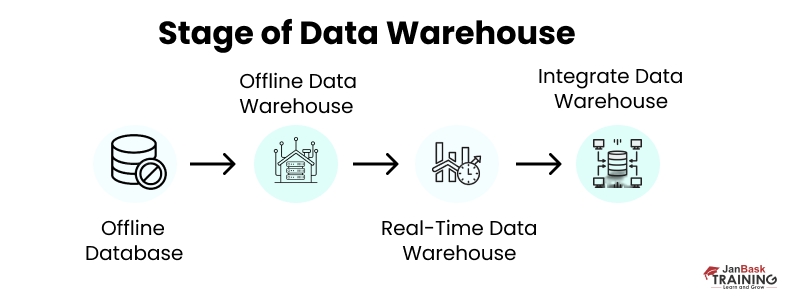
Ans:- Real-time data warehousing means a system that regularly shows the status of the warehouse. Let’s say you perform a query on the real-time data warehouse to get more regarding a certain attribute of the warehouse or entity it defines. Here the result will show the entity’s status when the query was performed. The majority of the warehouses comprise great latent data displaying the business during a certain time period. Poor latency current data is given through a real-time data warehouse.
Ans:- The Complete Compare feature allows you to detect and settle any peculiarities between two data models or script files. To let you know the difference between the models, database, and script file, the Complete Compare wizard provides a huge set of compare situations. It is very potent equipment that allows you to visualize the models and settle issues.
Ans:- A database can gather and fetch data through a column store. It is a contemporary style to collect and fetch data. Nowadays, column store databases utilize column-oriented storage, that keeps the data vertically. The database reads the columns. And hence a query comprises lesser hard disks needed to fetch data. Caching the entire database in RAM is called in-memory analytics. This style was highly unaffordable previously due to the costliness of RAM but now in-memory analytics are used widely by industries.
Ans:- Data vault modeling refers to a hybrid method that utilizes dimensional modeling and a third normal pattern to cater to the logical enterprise data warehouse. The design is flexible to the company’s demands and can be extended, and relied upon. The data vault idea can be utilized with huge, organized, unorganized data sets owing to the design that contains a bottom-up, gradual, and modular style.
Ans:- There are three fundamental classifications of tables in data vault modeling:
Hubs- An unique range of business keys for business purposes.
Links- A distinct range of relations and transactions that serve as the fundamental creation blocks of a business cycle.
Satellites- Detailed information for hubs and links.
Ans:- With the support of the hardware-enhanced cache, Advanced Query Accelerator, Redshift can perform ten times better than other enterprise cloud data warehouses. The data in a warehouse structure with focussed storage should be delivered to automated clusters for processing. By doing a vital part of the data processing in position on the sharp-edge cache, AQUA is meant to shift the compute to the storage.
Ans:- APEX refers to an enterprise low-code development medium from Oracle Corporation and it is used to generate and utilize cloud, mobile, and computer applications. An apex transaction refers to a range of actions that work coherently. The DML tasks responsible for querying records are considered in the category of actions. When a single record-saving mistake occurs during a transaction’s DML method, the whole transaction is either accomplished or taken aback.
We hope these Data Modeler interview questions have given you a glimpse of what kind of questions can be asked in a Data Modeling interview and what a Data Modeler does. So, if you’re planning to accelerate your data modeler career, sign up JanBask Training’s Online SQL Training Program, which will boast a half dozen courses, including in-demand skills and tools and real-life projects.
So, check out JanBask Training’s resources, improve your data modeling experience and skills right away, and give your new data modeling career a great start! All the Best!
Q.1 What are the benefits of the online data science class?
Ans: There are various advantages of the online data science class. It allows you to take up the training from the comfort of your place without the need to travel to a physical location. Also, data science training programs educate you on how to reduce the risk of data theft and faults, boost efficiency, and offer great customer service.
Q.2 What are the career opportunities after getting the data scientist certification online?
Ans: Attaining the data scientist certification online opens the gate to a wide range of career opportunities such as data analysts, data scientists, and database administrators. and data engineers. Data scientist certification online also provides recognition and identity to classify you from the non-certified candidates so that recruiters are more convinced to choose you for the job since your knowledge is authentic as per the certificate.
Q.3 What are the prerequisites for taking up the online data science class?
Ans. The data science training programs have certain prerequisites. The individual must have mathematical knowledge including probability, statistics, and algebra. Having knowledge of object-oriented languages like Java, and Python are extra added benefits to learn data science online.
Q.4 Is coding necessary to learn data science online?
Ans. Yes, the candidate must possess coding knowledge to take up the data science training programs. The data scientist certification online course utilizes programming languages like Python and C to generate machine learning algorithms and handle huge datasets. Hence, prior knowledge of coding is essential to learn data science online.
Q.5 Is Python essential for data science training programs?
Ans. It is normal to perform as a data scientist deploying Python or R. Every language possesses its individual benefits and weaknesses. Both languages are utilized well in the field. Python is comparatively more renowned but R rules in a few industries like for academic research. Hence, Python is equally needed for taking up the data scientist certification online course.
Abhijeet Padhy is a content marketing professional at JanBask Training, an inbound web development and training platform that helps companies attract visitors, convert leads, and close customers. He has been honored with numerous accreditations for technical & creative writing. Also, popularly known as “Abhikavi” in the creative arena, his articles emphasize the balance between informative needs and SEO skills, but never at the expense of entertaining reading.

Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Interviews









 Oct 04, 2024
Oct 04, 2024 5.9k
5.9k

Max
This is indeed a very nice blog. It comprises all the necessary data model interview questions. The data modeling interview questions and answers detailed in this blog are of great help to the ones who are interested and want to proceed further in this domain.
JanbaskTraining
Hey, thanks for the feedback. We would be happy to help you further. Feel free to connect to us at www.janbasktraining.com/contact-us
jone
This is such a wonderful and helpful blog. I loved reading the blog. I am interested in the field of data science. Myself, being a data scientist, I couldn’t stop reading the blog till the end. The database design interview questions mentioned in the blog are really descriptive and
JanbaskTraining
Hey, thanks for the feedback. We would be happy to help you further. Feel free to connect to us at www.janbasktraining.com/contact-us
Amelia MILLER
This is a very informative blog. The database design interview questions mentioned in the blog have been of immense help to me since I have been selected to appear for the data modeling interview round. The blog has all the probable data modeling interview questions and answers that can help us crack the interview in one shot.
JanbaskTraining
Hey, thanks for the feedback. We would be happy to help you further. Feel free to connect to us at www.janbasktraining.com/contact-us
Kaden Brown
This is a very useful blog. The data modelling questions mentioned here are really descriptive and helpful. The illustrative images are an added benefit further escalating the interest to read the blog. The data modeler interview questions are well-written along with their answers to help us have a clear understanding of the entire concept.
JanbaskTraining
Hey, thanks for the feedback. We would be happy to help you further. Feel free to connect to us at www.janbasktraining.com/contact-us
Zane Brown
This is a very good blog. The data modeling questions mentioned over here are a big source of help and support for anybody who has no clue regarding the questions that can come for the interview.
JanbaskTraining
Hey, thanks for the feedback. We would be happy to help you further. Feel free to connect to us at www.janbasktraining.com/contact-us
Emilio Davis
I loved reading this blog. It is a very interesting one. The data modelling interview questions presented in the blog are descriptive and simple. The blog is indeed beneficial.
JanbaskTraining
Hey, thanks for the feedback. We would be happy to help you further. Feel free to connect to us at www.janbasktraining.com/contact-us
Paul Wilson
The blog comprises the fundamental and advanced level data modeling interview questions. We can have a clear idea of the questions that can come for the interview as well as the blog has readymade answers to those questions. Furthermore, the data modeling interview questions are simple, yet essential.
JanbaskTraining
Hey, thanks for the feedback. We would be happy to help you further. Feel free to connect to us at www.janbasktraining.com/contact-us
Odin Washington
The blog contains the necessary data modeling interview questions and answers that act as a great help for those willing to appear for the interview. The questions are nothing but a pure set of gems to help us ace the data modeling interview round.
JanbaskTraining
Hey, thanks for the feedback. We would be happy to help you further. Feel free to connect to us at www.janbasktraining.com/contact-us
Cesar Butler
This is a fantastic blog. It contains all the possible data modeling interview questions that act as fuel to help us survive the data modeling interview round.
JanbaskTraining
Hey, thanks for the feedback. We would be happy to help you further. Feel free to connect to us at www.janbasktraining.com/contact-us