
 Sep 10, 2019
Sep 10, 2019  8.2k
8.2k

08
AugMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Hadoop Blogs -
One of the biggest challenges that big data has posed in recent times is overwhelming technologies in the field. There are so many platforms, tools, etc. to ai you in Big Data analysis that it gets very difficult for you to decide on which one to use for your concern. In this case, the only way to make a good decision is to analyze and understand a few important and popular tools. One such tool is Apache Flink. This blog is a small tutorial that will walk you through the important aspects of Apache Flink.
Apache Flink is the cutting edge Big Data apparatus, which is also referred to as the 4G of Big Data.
Apache Flink is the amazing open-source stage which can address following kinds of necessities effectively
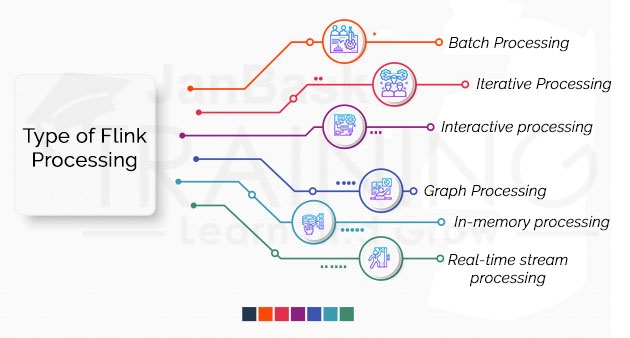
Flink is an option to MapReduce, it forms information over multiple times quicker than MapReduce. It is autonomous of Hadoop yet it can utilize HDFS to peruse, compose, store, process the information. Flink does not give its own information stockpiling framework. It takes information from circulated stockpiling.
On the Architectural side - Apache Flink is a structure and appropriated preparing motor for stateful calculations over unbounded and limited information streams. Flink has been intended to keep running in all normal group situations, perform calculations at in-memory speed and any scale.
Read through the following paragraphs were, we have tried to explain the important aspects of Flink’s architecture.
Any sort of information is created as a flood of occasions. Visa exchanges, sensor estimations, machine logs, or client cooperation on a site or portable application, this information are produced as a stream.
Data in Flink can be processed as either unbounded or bounded streams.
Read: Top 30 Splunk Interview Questions and Answers
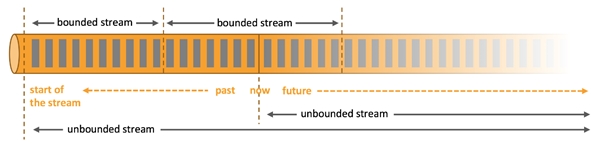
Apache Flink exceeds expectations at preparing unbounded and limited informational collections. Exact control of time and state empower Flink's runtime to run any sort of use on unbounded streams. Limited streams are inside handled by calculations and information structures that are explicitly intended for fixed measured informational collections, yielding superb execution.
On the operations side- Apache Flink is a system for stateful calculations over unbounded and limited information streams. Since many gushing applications are intended to run ceaselessly with negligible vacation, a stream processor must give amazing disappointment recuperation, just as, tooling to screen and keep up applications while they are running.
Apache Flink puts a solid spotlight on the operational parts of stream handling. Here, we clarify Flink's disappointment recuperation component and present its highlights to oversee and regulate running applications.
Machine and procedure disappointments are universal in circulated frameworks. An appropriated stream processor like Flink must recuperate from disappointments to have the option to run spilling applications all day, every day. This does not just mean to restart an application after a disappointment yet additionally to guarantee that its inward state stays steady, with the end goal that the application can keep preparing as though the disappointment had never occurred.
Flink gives a few highlights to guarantee that applications continue to run and stay steady:
Streaming applications that power business-basic administrations should be kept up. Bugs should be fixed and upgrades or new highlights should be actualized. Nonetheless, refreshing a stateful gushing application isn't unimportant. Frequently one can't just stop the applications and restart a fixed or improved adaptation since one can't stand to lose the condition of the application.
Flink's Savepoints are an extraordinary and ground-breaking highlight that explains the issue of refreshing stateful applications and numerous other related difficulties. A savepoint is a reliable preview of an application's state and thusly fundamentally the same as a checkpoint. Anyway rather than checkpoints, savepoints should be physically activated and are not consequently evacuated when an application is ceased. A savepoint can be utilized to begin a state-perfect application and introduce its state. Savepoints empower the accompanying highlights:
Apache Flink is a structure for stateful calculations over unbounded and limited information streams. Flink gives various APIs at various degrees of deliberation and offers committed libraries for normal use cases.
Read: Top 20 Apache Solr Interview Questions & Answers for Freshers and Experienced
The sorts of uses that can be worked with and executed by a stream handling system are characterized by how well the structure controls streams, state, and time. In the accompanying, we portray these structure hinders for stream preparing applications and disclose Flink's ways to deal with handle them.
Streams are a basic part of stream preparing. Notwithstanding, streams can have various qualities that influence how a stream can and ought to be prepared. Flink is a flexible preparing system that can deal with any stream.
Each non-vital application is stateful, i.e., just applications that apply changes on individual occasions don't require state. Any application that runs fundamental business rationale needs to recall occasions or middle outcomes to get to them at a later point in time, for instance when the following occasion is gotten or after a particular time length.
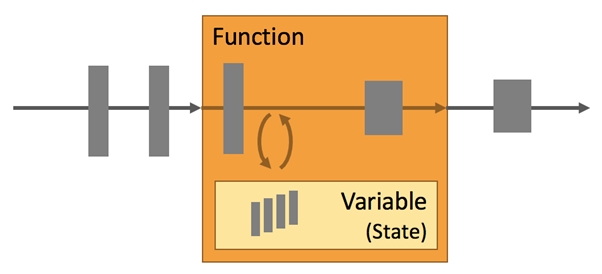
Application state is a top of the line native in Flink. You can see that by taking a gander at all the highlights that Flink gives with regards to state handling.
Time is another significant element of gushing applications. Most occasion streams have inborn time semantics because every occasion is created at a particular point in time. Besides, numerous normal stream calculations depend on schedule, for example, windows accumulations, sessionization, design location, and time-sensitive joins. A significant part of stream preparing is how an application estimates time, i.e., the distinction of occasion time and handling time.
Flink provides very varied features related to time.
Flink doesn't deliver with the capacity framework; it is only a calculation motor. Flink can peruse, compose information from various capacity framework just as can devour information from gushing frameworks. The following is the rundown of the capacity/gushing framework from which Flink can peruse compose information:
Its second layer is usually called deployment/resource management. It can be easily deployed in the modes given as following:
Read: Harnessing the Power of Data Analytics: Exploring Hadoop Analytics Tools for Big Data
The following layer is Runtime – the Distributed Streaming Dataflow, which is additionally called as the bit of Apache Flink. This is the center layer of flink which gives conveyed preparing, adaptation to internal failure, unwavering quality, local iterative handling ability, and so forth.
The top layer is for APIs and Library, which gives the various ability to Flink:
It handles the information at rest, it enables the client to actualize activities like a guide, channel, join, gathering, and so on the dataset. It is principally utilized for appropriated preparing. All things considered, it is an uncommon instance of Stream preparing where we have a limited information source. The bunch application is additionally executed on the gushing runtime.
It handles a nonstop stream of the information. To process live information stream it gives different activities like a guide, channel, update states, window, total, and so on. It can devour the information from the different spilling source and can compose the information to various sinks. It underpins both Java and Scala.
It empowers clients to perform impromptu investigation utilizing SQL like articulation language for social stream and bunch preparing. It very well may be implanted in DataSet and DataStream APIs. In reality, it spares clients from composing complex code to process the information rather enables them to run SQL inquiries on the highest point of Flink.
It is the chart preparing engine which enables clients to run a set of tasks to make, change and procedure the diagram. Gelly likewise gives the library of a calculation to rearrange the advancement of chart applications. It uses local iterative preparing model of Flink to deal with diagram effectively. Its APIs are accessible in Java and Scala.
It is the AI library which gives instinctive APIs and a proficient calculation to deal with AI applications. We compose it in Scala. As we probably are aware, AI calculations are iterative, Flink gives local help to an iterative calculation to deal with the equivalent adequately and productively.
Apache Flink comes with its own set of advantages and disadvantages. Now when you know about its entire architecture, operations, app management, etc., it will be easier for you to decide if you want to use it. If you have any doubts do let us know, we will be happy to help.
Read: Your Complete Guide to Apache Hive Data Models
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Top 10 Reasons Why Should You Learn Big Data Hadoop?
 242.7k
242.7k
Top 20 Apache Solr Interview Questions & Answers for Freshers and Experienced
648k
Salary Structure of Big Data Hadoop Developer & Administrator
818.1k
Your Complete Guide to Apache Hive Installation on Ubuntu Linux
828.2k
An Introduction to the Architecture & Components of Hadoop Ecosystem
670.3k
Receive Latest Materials and Offers on Hadoop Course
Interviews









 Mar 28, 2024
Mar 28, 2024 242.7k
242.7k
