
 Feb 13, 2020
Feb 13, 2020  5.7k
5.7k

04
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Data Science Blogs -
In the 21st century, machines are learning. Few machines learn the concept to the totality few are just weak learners just the students of a class. Few learn the subject, few just fail in the exam. The same is the case with machine learning algorithms, some of them are weak learners. To improve the learning in weak learners, a technique named boosting is implied. This boosting coupled with a set of weak learners give this algorithm its name Adaboost or in full known as “Adaptive Boosting”. To elaborate on this concept of “Adaptive Boosting’ the blog is divided into the following sections:
The weak learner is a type of learner who will only outperform a chance in any scenario where prediction is made. The accuracy of prediction is independent of the type of underlying distribution. These types of classifiers have a chance greater than ½ in the case of binary classification. These types of learners are going to learn something but will not be able to perform as per the requirement. These are though a type of classifier which has their prediction capacity which is slightly correlated with the true classification.
One of the classical examples of weak learners is decision stump (a one-level decision tree). Owing to its hierarchical design and rules associated with decision making it can perform well in certain cases i.e. slightly better than chance. At the same time, it is unjustified to call a support vector machine a weak learner.
In the domain of machine learning, boosting is a type of ensemble-based meta-algorithm that primarily reduces the bias and variance for training done under the domain of supervised learning. These are a family of machine learning algorithms that convert the weak learners into strong ones.
Boosting was first introduced as a solution to hypothesis boosting problem which in simpler terms is just converting a weak learner to a strong learner. Boosting is achieved by building a model with a certain amount of error from the dataset and then creating another one that can rectify the error. This process is done until the training data can be modeled using all the models.
AdaBoost stands for “adaptive Boosting’ and is the 1st boosting algorithm which was designed by Freund and Schapire in 1996. It is primarily focused upon the classification problems and is designed to convert a group of weak learners into a unified strong learner. The learner is represented mathematically as:
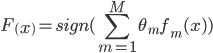
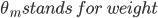
Adaptive boosting refers to a specific method of training a boosting based classifier. A boosting based ensemble classifier is of the form:
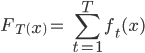
Where ft happens to be a weak learner that digests an input vector x and generated a class prediction.
Now, each weak learner-generated produces an output hypothesis, H(xi), for every sample, supplied in the training set. At every iteration t, a new weak learner is carefully chosen from all those generated in that step and is assigned a coefficient which satisfies the condition that the sum of training error Etof the final classifier is minimized i.e.
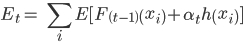
Read: What is Hypothesis Testing | Steps, Types, and Applications
Where Ft-1(x) is the classifier selected in the previous step,
And 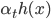 is the weak learner which is under consideration for induction in this step.
is the weak learner which is under consideration for induction in this step.
Steps involved in generating an AdaBoost based classifier:
The following steps are involved once we start from the dataset:
Data Science Training - Using R and Python

Adaboost stands for adaptive booting and is an ensemble-based boosting model for machine learning. Here, python will be used with sklearn to design an Adaboost based classifier and test its accuracy:
The first step in creating a model is to import the model and related lib:
|
from sklearn.ensemble import AdaBoostClassifier |
Imports the Adaboost model from standards lib |
|
from sklearn.datasets import make_classification |
Imports the libraries for creating a random labeled dataset from classification Read: PCA - A Simple & Easy Approach for Dimensionality Reduction |
Once the libraries have been loaded into the working memory, a dataset is being created in this example:
|
input_vector, label = make_classification(n_samples=1000, n_features=7, |
The make_classification generates is used to generate the dataset. This command will generate 1000 samples with 7 features i.e. no. of inputs in the input vector and put the input into input_vector and corresponding labels in the label. |
Now the dataset is ready, the first thing is to give a name to the AdaBoost based model:
|
model = AdaBoostClassifier(n_estimators=100, random_state=0) |
As can be seen, there will be 100 weak leaner in this ensemble. |
Now, the model is to be trained before it can be utilized in any application:
|
model.fit(input_vector,label) |
Now, the model is trained and fit for utilizing in any application and can be queried as:
|
Model.predict([1,0,1,1,0,0,1]) |
The accuracy of the model can be verified by utilizing the command as:
|
model.score(input_vector, label) Read: What Exactly Does a Data Scientist Do? |
for the model trained in this example, the score remains as 0.635
Note: if the dataset is being generated using a make_classifier, the final result may be different because of different initial conditions and differences in the dataset introduced because of randomization.
Adaboost is one of the basic boosting algorithms. Thus, it has its own sets of issues. The major advantages of AdaBoost are:
Adaboost also suffers from a few limitations, which are:
Data Science Training - Using R and Python

Final Words:
In this blog, we have discussed the Adaboost and creating a model based upon AdaBoost. Adaboost is an ensemble-based Boosting technique which is quite useful in scenarios where finding a strong is difficult. It is one of the basic boosting techniques which is still widely used. The major reason for the same being that this model allows us to capture the non-linearity in the data.
Please leave the query and comments in the comment section.
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Data Science vs Software Engineering - What you should know?
 310.4k
310.4k
What is Hypothesis Testing | Steps, Types, and Applications
1.8k
An Easy to Understand the Definition of the Confidence Interval
5.1k
How to Work with Regression based Models?
5.8k
The Future of Data Science: Opportunities and Trends to Watch
5.2k
Receive Latest Materials and Offers on Data Science Course
Interviews











 Jul 21, 2025
Jul 21, 2025 310.4k
310.4k
