
 Apr 20, 2020
Apr 20, 2020  6.5k
6.5k

04
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Data Science Blogs -
Statistics is a part of Mathematics, that manages the collection, analysis, understanding, and the introduction of the numerical information. At the end of the day, it is characterized as the collection of quantitative information. The principle motivation behind Statistics is to make a precise determination utilizing a constrained example of a more noteworthy populace. Statistics can be characterized into two distinct classes. The two unique sorts of Statistics are:
In Statistics, descriptive statistics portray the information, while inferential statistics assist you with making expectations from the information. This blog post is all about Inferential Statistics or as the Topic suggests Statistical Inference.
The general thought that underlies Statistical Inference is the examination of specific statistics from on observational informational collection (for example the mean, the standard deviation, the distinctions among the methods for subsets of the information), with a fitting reference circulation to pass judgment on the centrality of those statistics. At the point when different presumptions are met, and explicit speculations about the estimations of those statistics that ought to emerge by and by having been determined, at that point Statistical Inference can be a ground-breaking approach for making logical determinations that productively utilize existing information or those gathered for the particular motivation behind testing those theories. Indeed, even in a setting when a formal experimental plan is preposterous, or when the goal is to investigate the information, hugeness assessment can be valuable.
Statistical inference is the way toward breaking down the outcome and making ends from the information subject to arbitrary variety. It is likewise called inferential statistics. Hypothesis testing and confidence intervals are the utilizations of the statistical inference. Statistical inference is a technique for settling on choices about the parameters of a populace, in light of irregular sampling. It assists in evaluating the connection between the dependent and independent variables. The motivation behind statistical inference to evaluate the vulnerability or test to test variety. It permits us to give a likely scope of qualities for the genuine benefits of something in the populace. The fixings utilized for making statistical inference are:
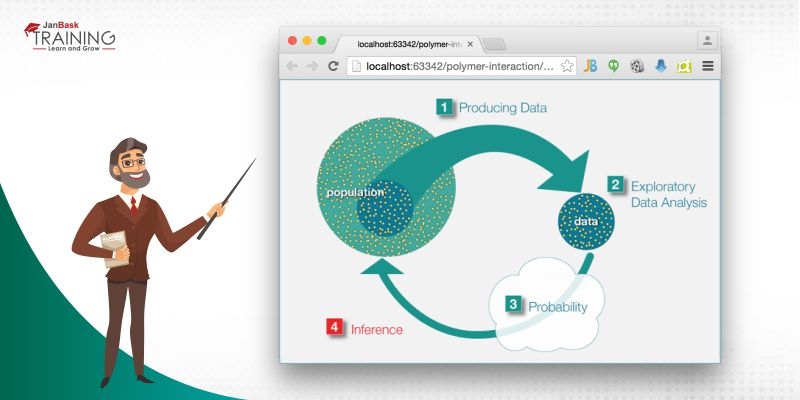
Figure 1 Statistical Inference
The technique engaged with statistical inference are:
Inferential Statistics is critical to inspect the information appropriately. To make a precise end, legitimate information analysis is critical to deciphering the exploration results. It is significantly utilized later on the forecast for different perceptions in various fields.
Data Science Training - Using R and Python

As per the central limit theorem, the mean of a sample of information will be nearer to the mean of the general population being referred to, as the sample size increments, despite the real appropriation of the information. As such, the information is precise whether the appropriation is typical or distorted.
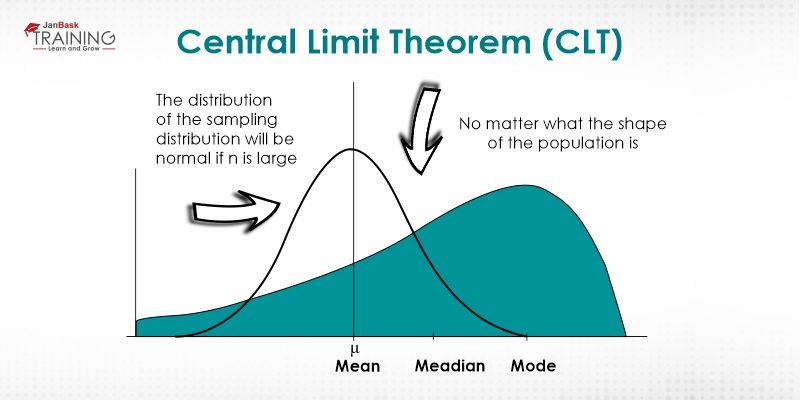
Figure 2 Central Limit Theorem
When in doubt, sample sizes equivalent to or more prominent than 30 are esteemed adequate for the CLT to hold, implying that the circulation of the sample implies is decently ordinarily disseminated. In this manner, the more samples one takes, the more the charted outcomes take the state of an ordinary appropriation. Central Limit Theorem displays a wonder where the normal of the sample means and standard deviations equivalent the population mean and standard deviation, which is very valuable in precisely foreseeing the qualities of populations.
Data Science Training - Using R and Python

Inferential Statistics is critical to analyze the information appropriately. To make an exact end, appropriate information analysis is imperative to decipher the examination results. It is significantly utilized later on the forecast for different perceptions in various fields. It encourages us to make inference about the information. The statistical inference has a wide scope of utilization in various fields, for example,
With so much discussion of statistics, on the unavoidable issue comes up: imagine a scenario in which the sample is not the same as the parameter of the population. All things considered; it might be. That distinction between the sample statistics and the parameter is called sampling variability or as mentioned in the topic Variation between Samples. There is consistently variability in a measure. Variability originates from the way that only one out of every odd member in the sample is the equivalent. For instance, the normal stature of Indian guys is 5'5" however I am 5'8". I fluctuate from the sample mean, so this presents some variability.
Sampling variability is valuable in most statistical tests since it gives us a feeling of various the information is. Like I said before, I am not the normal stature, however, there are additionally a few people that are shorter than the normal tallness. The sampling variability is the measure of contrast between the deliberate qualities and the measurement.
Some statistical inference solution realities are:
Sampling variability is the contrast between the deliberate worth and the genuine measurement or parameter. The sampling variability is additionally alluded to as standard deviation or difference of the information. It is utilized in a few sorts of statistical tests to break down the information for a hidden structure.
Following keynote points are drawn out from the Central Limit Theorem:
Please leave the query and comments in comment section.
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Data Science Course
Interviews












 Oct 12, 2022
Oct 12, 2022 194.9k
194.9k

 194.9k
194.9k